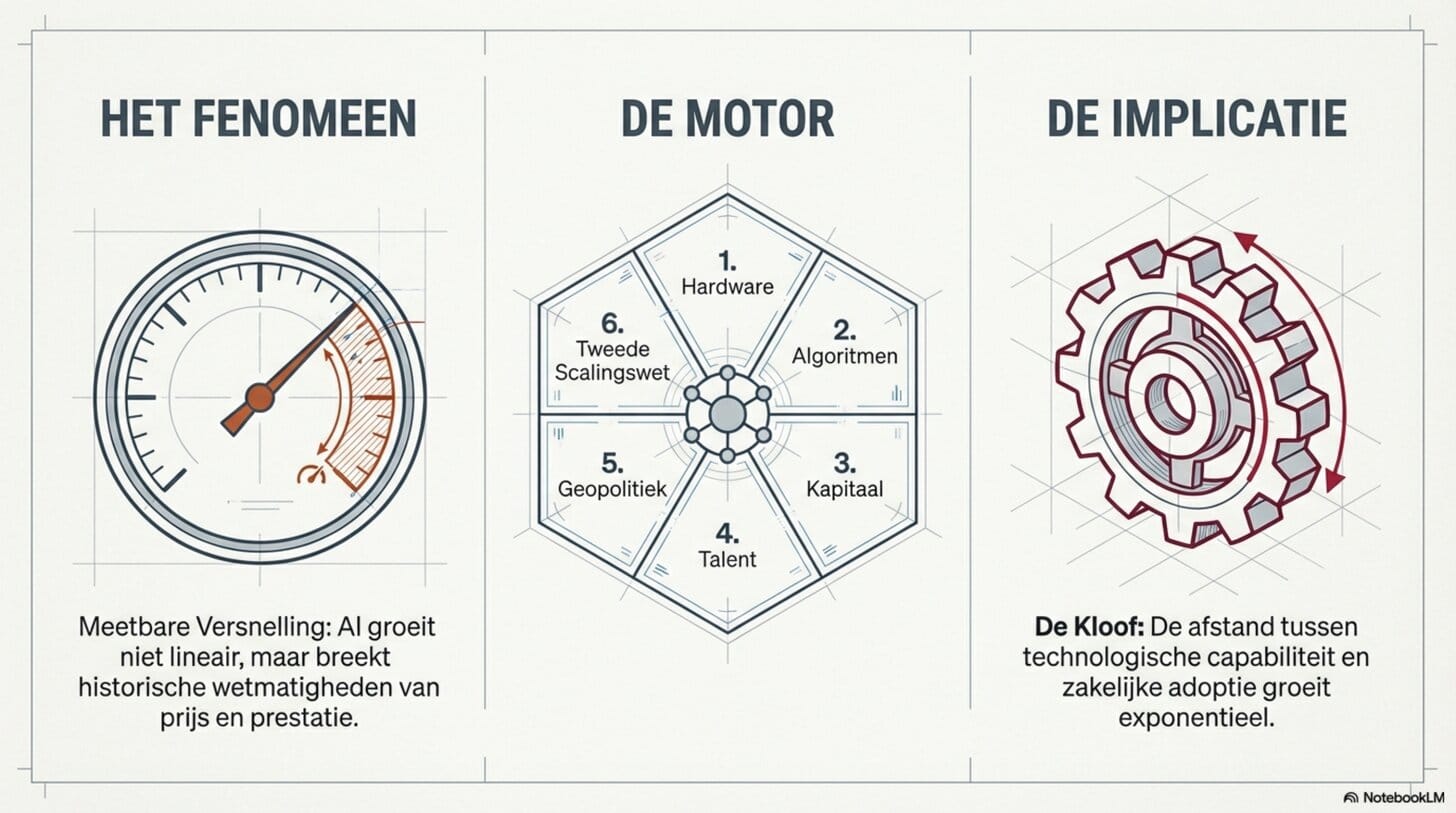
De versnelling van AI

Het gaat niet alleen sneller. Het gaat structureel sneller. En ik zie zes oorzaken.

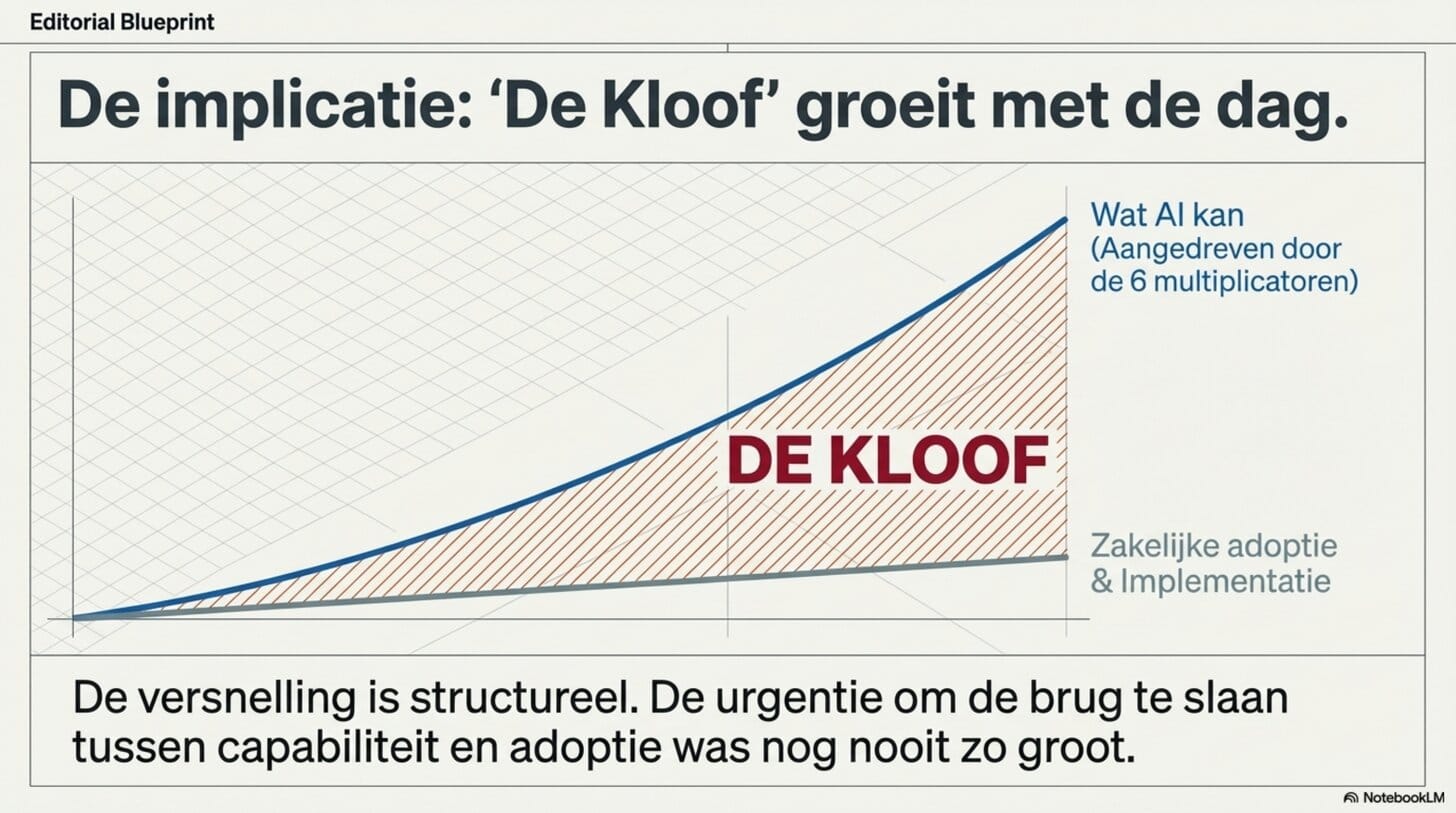
In De Kloof heb ik beschreven hoe groot de afstand al is tussen wat AI kan en wat we er daadwerkelijk mee doen. In Het Schaakbord heb ik uitgelegd wat exponentiële groei betekent en waarom onze intuïtie er structureel naast zit. Beide blogs gingen over het fenomeen. Deze gaat over het mechanisme.
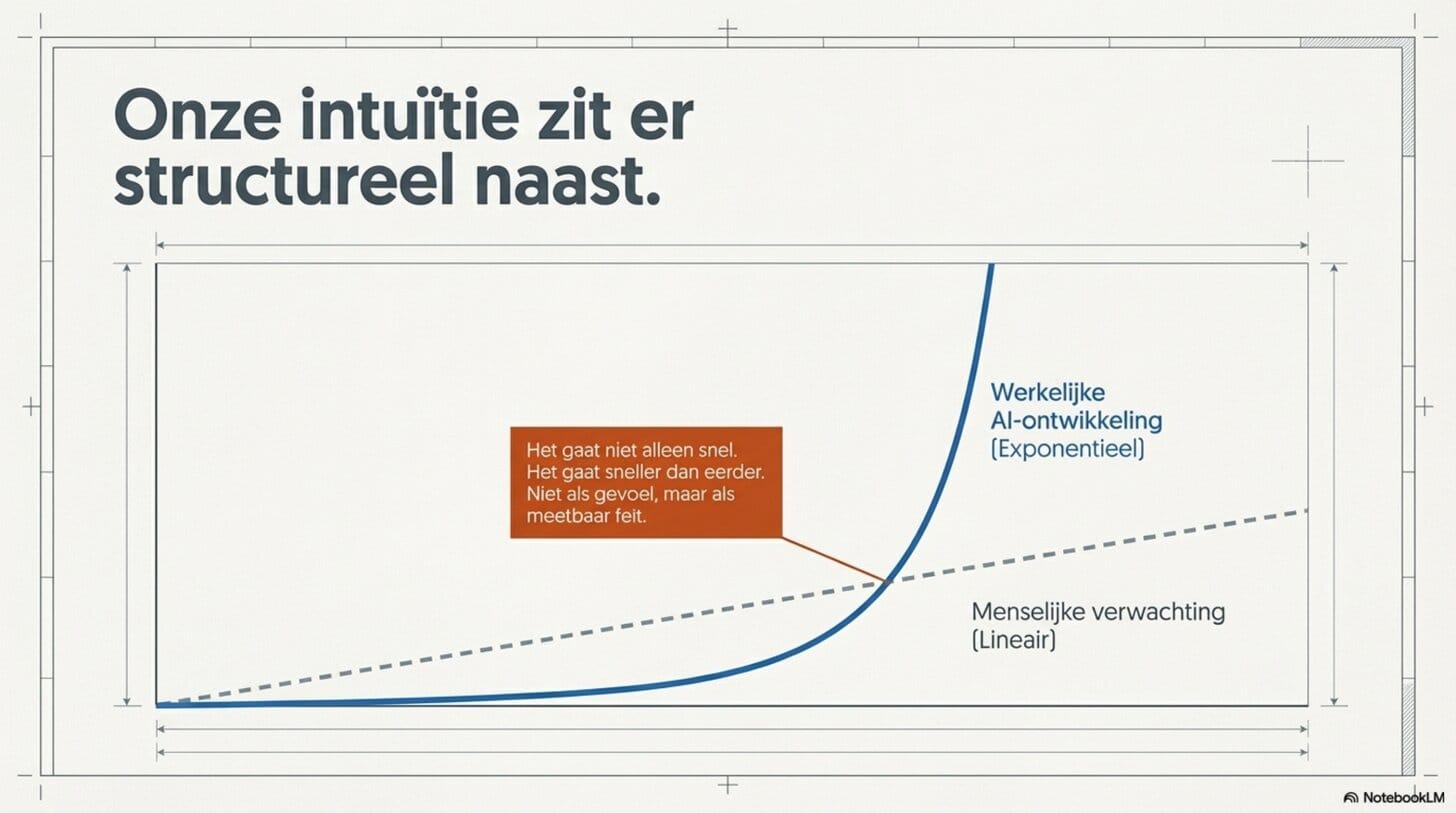
Want er is iets wat ik de afgelopen maanden steeds sterker voel — en wat ik nu ook hard kan onderbouwen. De ontwikkeling gaat niet alleen snel. Ze gaat sneller dan eerder. Niet als gevoel, maar als meetbaar feit. En ze gaat sneller omdat er meerdere factoren tegelijk aan het werk zijn. Niet naast elkaar, maar als vermenigvuldiger van elkaar.
De lek van Claude Mythos — een nieuw Anthropic-model dat per ongeluk in een publieke databron terechtkwam — is een treffend voorbeeld. Een model in een geheel nieuwe categorie boven Opus, met dramatisch hogere scores op redeneren, coderen en cybersecurity, aangekondigd voordat het bedrijf er klaar voor was. Dat is geen incident. Dat is het tempo van het veld.
Hoe hard gaat het dan? En waarom?
TL;DR — Voor wie nu al denkt: dit wordt te lang — hierbij de korte versie. De versnelling van AI is geen gevoel — het is meetbaar. Trainingscompute verdubbelt elke vijf maanden, inferentiekosten daalden in tweeënhalf jaar met 99,7 procent, en benchmarks die in 2021 als fundamenteel moeilijk golden, zijn vier jaar later al verzadigd. Ik zie zes onderliggende factoren die dit samen verklaren: snellere hardware op drie assen tegelijk, algoritmen die elk jaar drie keer efficiënter worden, historisch ongekende investeringsschaal, de concentratie van wereldwijd toptalent bij een handvol labs, de VS-China-competitie die het tempo extern opdrijft, en de ontdekking van een tweede scalingswet via reasoning modellen. Die zes werken niet naast elkaar — ze werken als vermenigvuldiger van elkaar. De urgentie die ik beschreef in De Kloof wordt er alleen maar groter door.
Eerst het bewijs
Voordat ik de oorzaken bespreek, wil ik de versnelling zelf hard maken. Want het is makkelijk om dit als gevoel te hebben. Het is iets anders om het te meten.
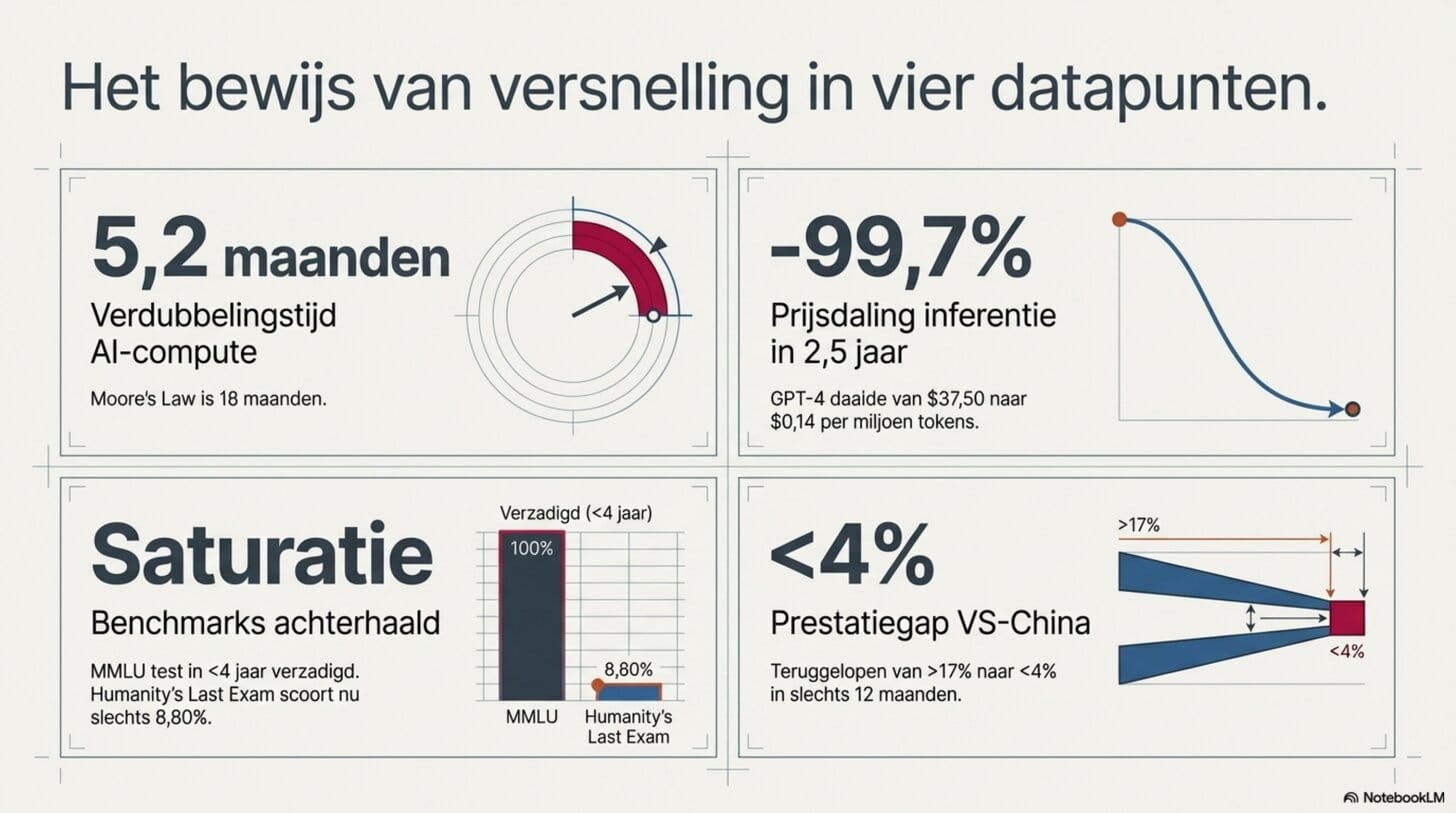
Epoch AI — het meest gezaghebbende kwantitatieve AI-onderzoeksinstituut — bijhoudt meer dan 3.200 modellen in een publieke database. Wat zij zien: de trainingscompute van frontier AI-modellen verdubbelt elke 5,2 maanden. Ter vergelijking: Moore's Law — de wet die de hele computerindustrie decennialang heeft aangestuurd — werkt op een verdubbelingstijd van 18 maanden. AI-compute groeit meer dan drie keer zo snel.
Maar dat is niet het meest indrukwekkende getal.
Tussen maart 2023 en augustus 2025 daalden de kosten van AI op een gelijkblijvend capabiliteitsniveau met 99,7 procent. GPT-4 kostte bij lancering 37,50 dollar per miljoen tokens. In augustus 2025 lag de efficiëntiegrens op 0,14 dollar. Dat is een prijsdaling van bijna honderd procent in tweeënhalf jaar. Geen technologie in de gedocumenteerde geschiedenis heeft dit tempo bijgehouden — niet de pc, niet het internet, niet de smartphone.
En dan is er de benchmark-verzadiging. MMLU — een brede academische kennistest die in 2021 werd geïntroduceerd als fundamenteel moeilijk — was medio 2024 al nagenoeg verzadigd. Topmodellen scoorden zo consistent hoog dat de test niet langer kon onderscheiden wie beter was. Nog geen vier jaar na introductie. De community moest een nieuwe, nog moeilijkere test bouwen — Humanity's Last Exam. Het best presterende systeem scoort er vandaag 8,80 procent op. Niet omdat AI zo slecht is, maar omdat de lat bewust onhaalbaar hoog is gelegd. En ook die lat zal worden gehaald.
Nog één getal, dan stop ik met de bewijs-stapel. De prestatiegap tussen de beste Amerikaanse en Chinese AI-modellen op vier standaardbenchmarks bedroeg eind 2023 gemiddeld meer dan 17 procentpunten. Eind 2024 was dat teruggelopen naar minder dan 4 procentpunt. Twee gescheiden ontwikkeltrajecten, elk op volle snelheid, convergentie in twaalf maanden.
Dit is de versnelling in cijfers. Nu de oorzaken.
Zes factoren — en er valt over te twisten
Ik zie zes onderliggende factoren die de versnelling samen verklaren. Dit is geen definitieve lijst — je kunt factoren samenvoegen, anders indelen, of er eentje aan toevoegen die ik mis. Maar dit zijn de zes die mij het meest overtuigen.
1. Hardware wordt tegelijk sneller, breder en goedkoper
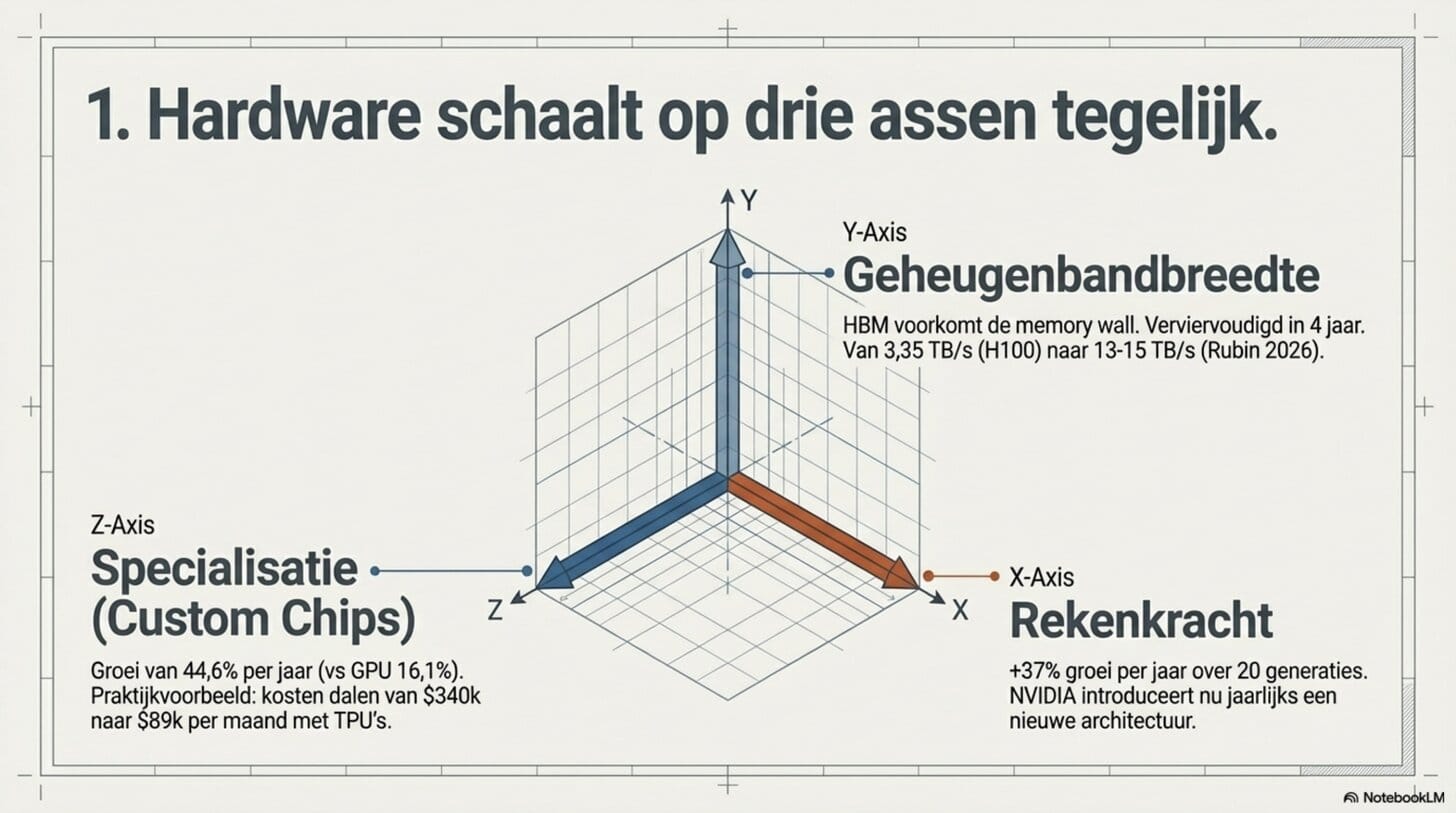
De chips waarop AI draait verbeteren op drie assen tegelijk — en dat is uitzonderlijk, want normaal gaat winst op de ene as ten koste van een andere.
De rekenkracht per chip groeit met 37 procent per jaar, gemeten over meer dan twintig generaties accelerators. NVIDIA lanceert nu jaarlijks een nieuwe architectuur in plaats van elke twee jaar. Jensen Huang omschrijft zichzelf publiekelijk als "chief revenue destroyer" — hij vernietigt bewust zijn eigen producten door sneller te introduceren dan de markt verwacht.
Maar rekenkracht is nutteloos als de data niet snel genoeg worden aangeleverd. Dat is de rol van HBM — High Bandwidth Memory, het geheugen dat direct naast de chip zit en data aanlevert voor berekeningen. Zonder voldoende HBM-bandbreedte wacht een snelle processor op trage data — de zogenaamde "memory wall". Die bandbreedte is verviervoudigd in vier jaar: van 3,35 terabyte per seconde bij de H100 (2022) naar een geprojecteerde 13-15 terabyte per seconde bij de Rubin-chips die in 2026 uitkomen.
En dan zijn er de gespecialiseerde chips. Naast GPU's bouwen alle grote technologiebedrijven nu eigen chips die uitsluitend zijn ontworpen voor AI: Google's TPU (inmiddels zevende generatie), Amazon's Trainium, Meta's MTIA, OpenAI's deal met Broadcom die dit jaar ingaat. Google's TPUv7 biedt 100 procent betere prestatie per watt dan zijn voorganger. Een startup die 128 H100-GPU's verving door TPU-pods zag zijn maandelijkse inferentierekening dalen van 340.000 naar 89.000 dollar. Custom chips groeien in 2026 met 44,6 procent per jaar, tegenover 16,1 procent voor GPU's.
Drie assen — rekenkracht, geheugenbandbreedte, specialisatie — die alle drie tegelijk verbeteren.
2. Algoritmen worden elk jaar drie keer efficiënter
Dit is de factor die vrijwel nooit in persberichten staat, maar die door Epoch AI nauwkeurig is gedocumenteerd en misschien wel de meest onderschatte is.
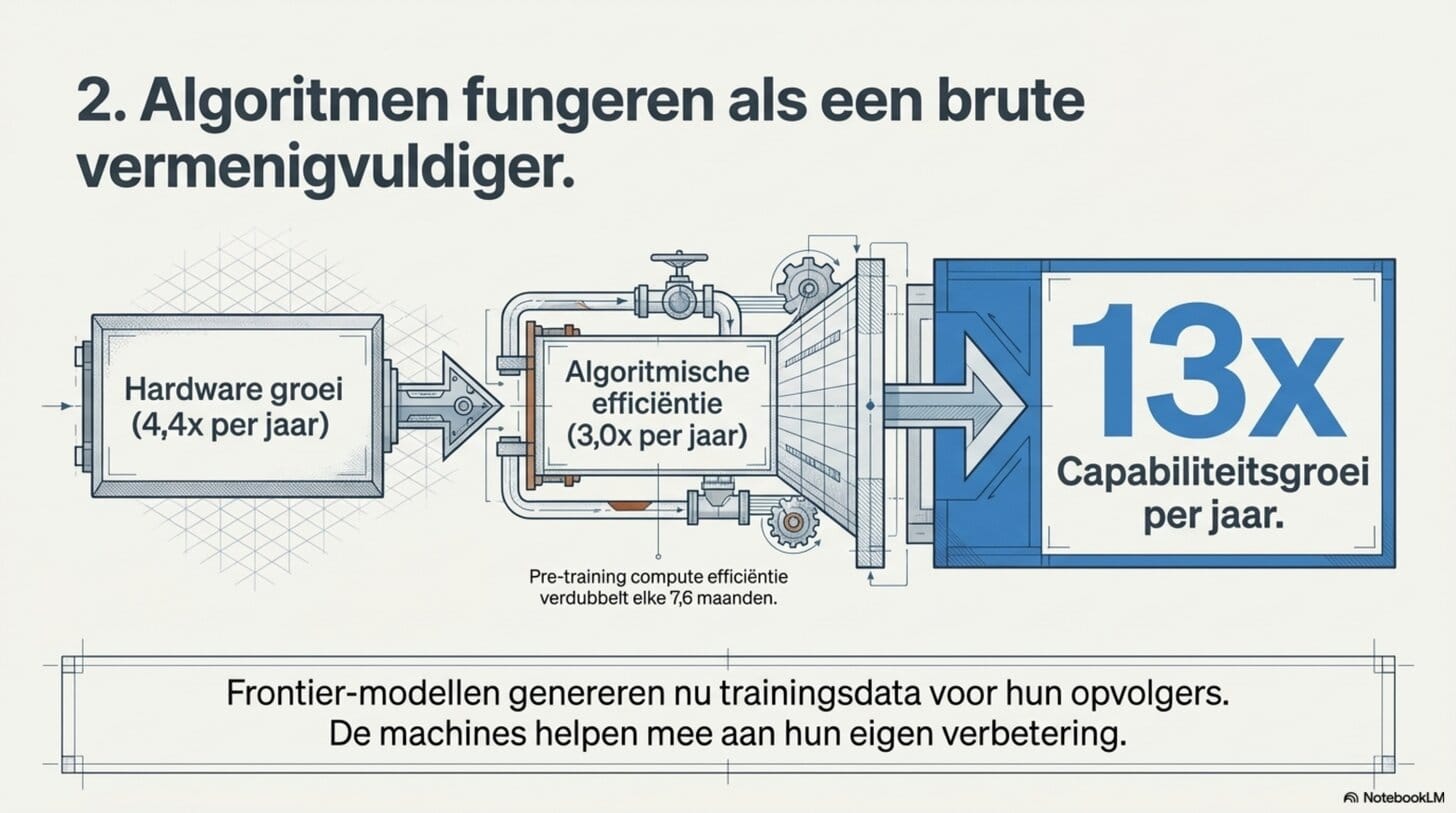
Pre-training compute-efficiëntie verbetert met 3,0 keer per jaar. Dat betekent: dezelfde modelprestatie is elke twaalf maanden te bereiken met drievoudig minder rekenkracht. Die verdubbeling vindt elke 7,6 maanden plaats — sneller dan de hardware-verbetering zelf.
Gecombineerd met de hardware-groei — 4,4 keer per jaar — levert dit een effectieve capabiliteitsgroei op van meer dan 13 keer per jaar. Puur door hardware-groei en algoritmische efficiëntie samen.
Waarom worden algoritmen beter? Betere architectuurkeuzes, slimmere datafiltering, efficiënter gebruik van lagere precisieformaten. Maar ook — en dit is structureel nieuw — frontier-modellen die trainingsdata genereren voor hun opvolgers. De machines helpen mee aan hun eigen verbetering.
3. De investeringsschaal is historisch zonder precedent
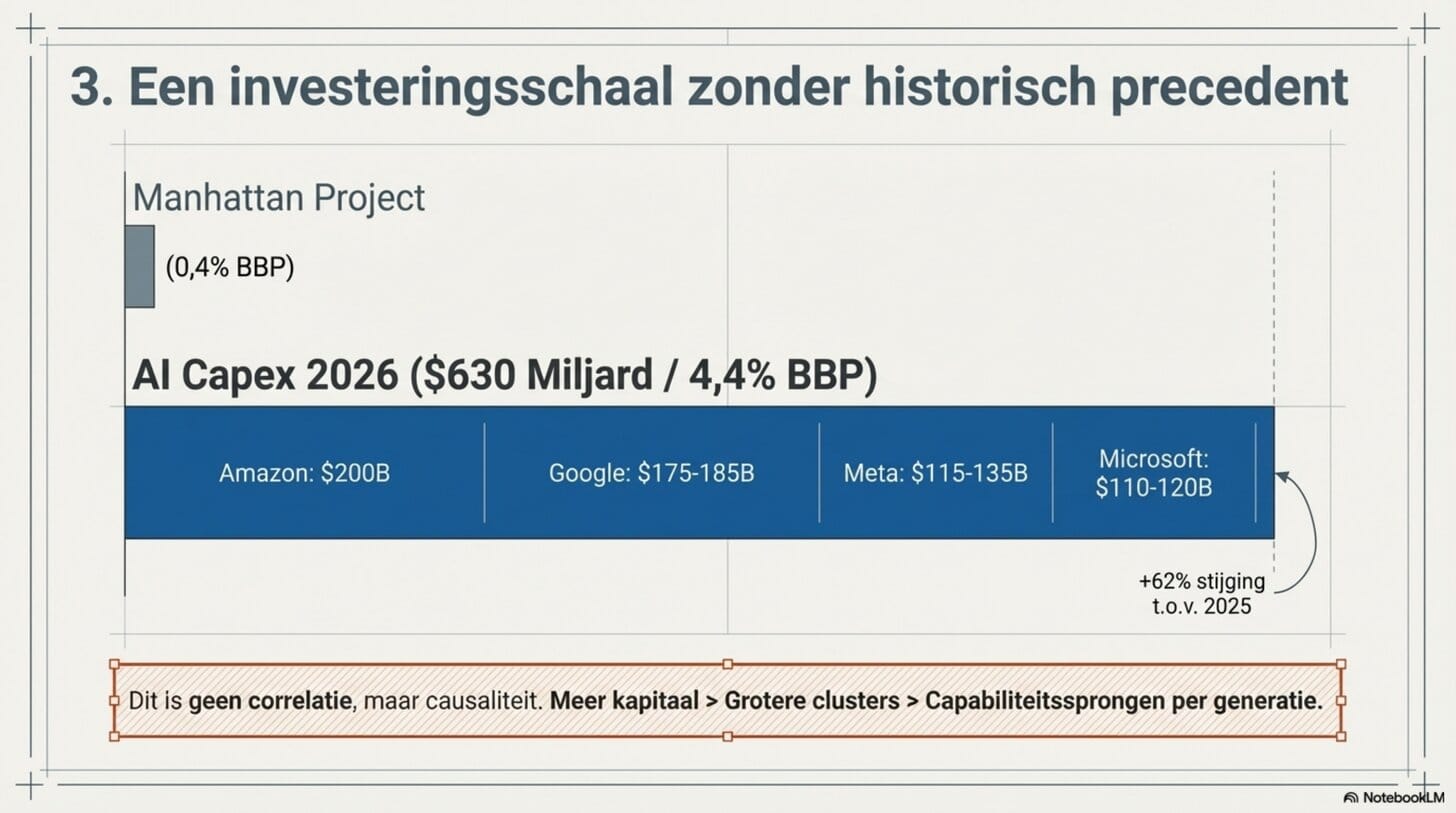
De hyperscalers investeren op een schaal waarvoor geen historisch vergelijkingspunt bestaat. Amazon plant 200 miljard dollar capex voor 2026. Google 175-185 miljard. Meta 115-135 miljard. Microsoft 110-120 miljard. Samen tot 630 miljard dollar in één jaar — een stijging van 62 procent ten opzichte van 2025.
Ter vergelijking: het Manhattan Project besloeg destijds circa 0,4 procent van het Amerikaanse BBP. De huidige AI-investeringen zitten op 4,4 procent.
Dit is geen correlatie met de versnelling — het is de causale basis ervan. Meer kapitaal koopt grotere clusters. Grotere clusters maken grotere trainingslopen mogelijk. Grotere trainingslopen produceren capabiliteitssprongen per generatie. Epoch AI voorspelt op basis van de huidige trend een trainingscluster van 200 miljard dollar tegen 2030.
4. Het toptalent concentreert zich bij een handvol labs
Dit is de factor die makkelijk wordt onderschat omdat hij menselijk is in plaats van technisch — maar hij heeft een directe invloed op het tempo van doorbraken.
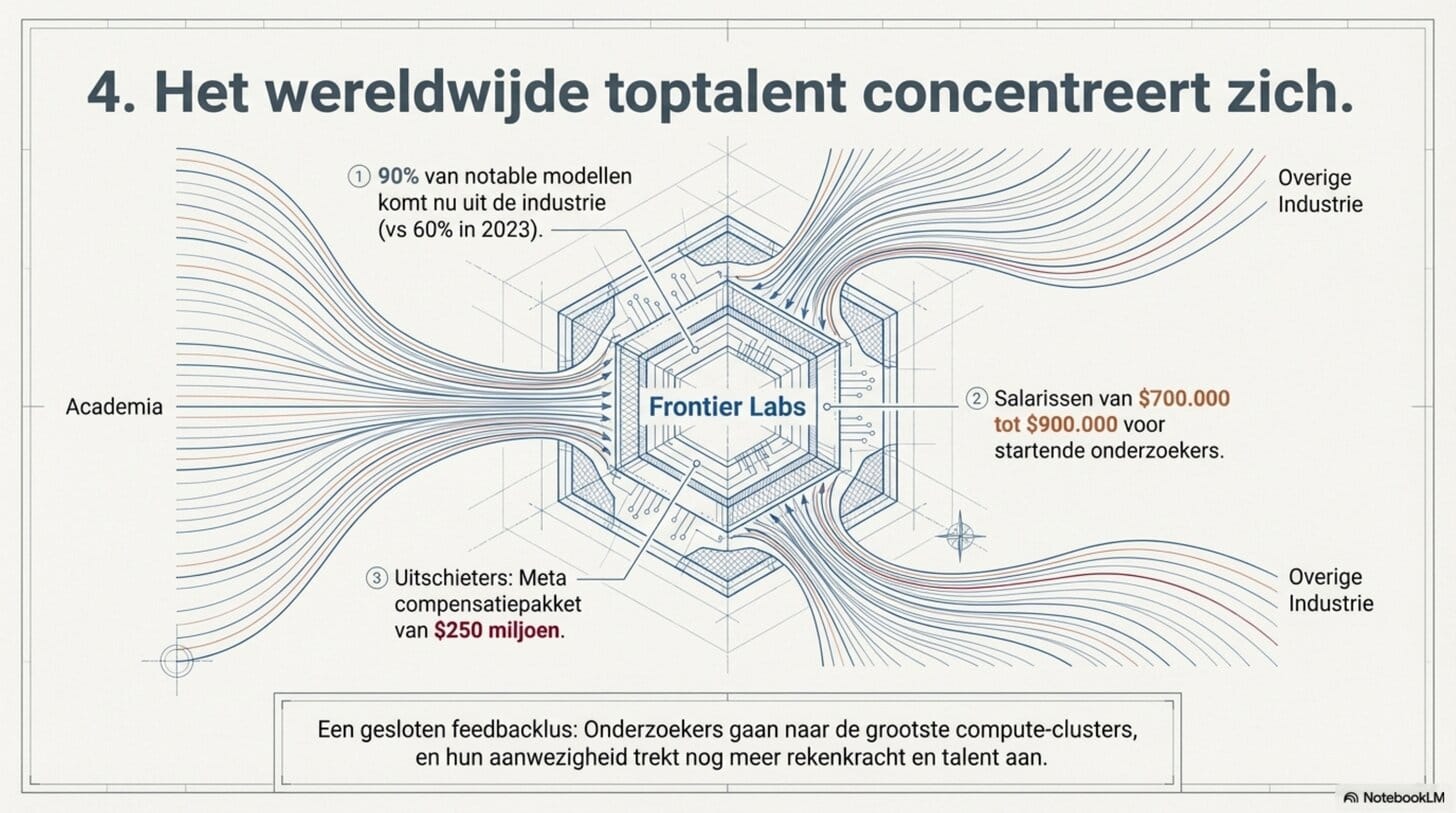
Bijna 90 procent van de notable AI-modellen in 2024 kwam uit industrie, tegen 60 procent in 2023. De kennis, de rekenkracht en de data zitten bij een klein aantal frontier labs — en het talent stroomt er naartoe. Meta bood één AI-onderzoeker een compensatiepakket van 250 miljoen dollar over vier jaar. Startende onderzoekers bij OpenAI en Anthropic verdienen 700.000 tot 900.000 dollar per jaar. Dat is geen gewone arbeidsmarkt.
Het gevolg is een feedbacklus: de beste onderzoekers gaan naar de labs met de meeste rekenkracht en de meest ambitieuze projecten. Die labs trekken daardoor nog meer toptalent aan. Jonge, hoogciteerde onderzoekers — precies de mensen die nog het meest bereid zijn om nieuwe richtingen in te slaan — bleken in 2024 honderd keer zo waarschijnlijk naar de industrie te vertrekken als hun meer gevorderde collega's. Academia verliest de mensen die de toekomst schrijven. De frontier labs winnen ze.
Die concentratie vergroot de efficiëntie waarmee alle andere factoren worden omgezet in werkelijke doorbraken.
5. De VS-China-competitie versnelt het tempo los van de techniek
Dit is de enige factor die extern is aan de technische ontwikkeling zelf — en hij is meetbaar effectief.
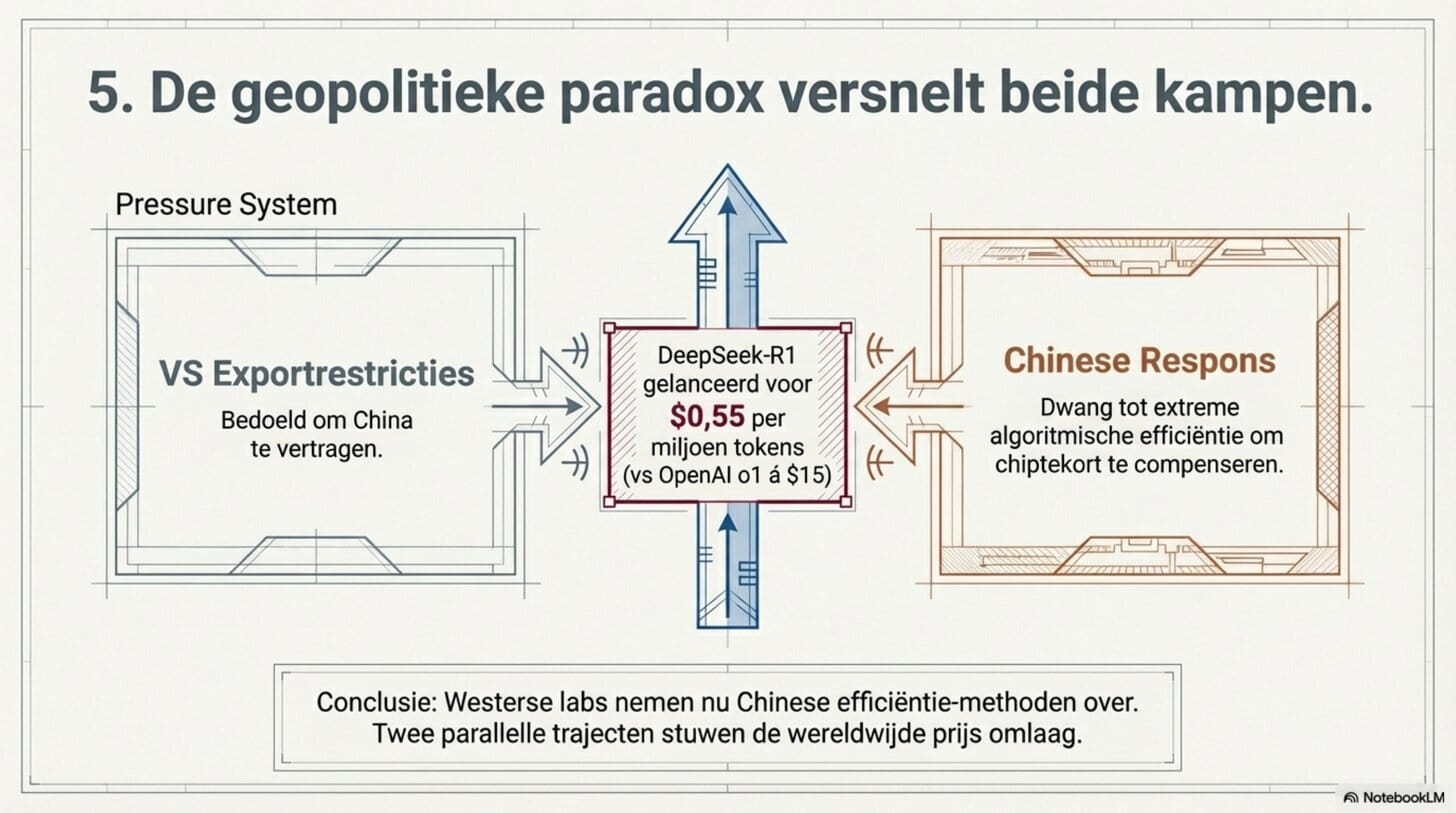
DeepSeek-R1, gelanceerd in januari 2025, werd uitgebracht voor 0,55 dollar per miljoen tokens — 90 tot 95 procent onder OpenAI's o1, dat destijds 15 dollar per miljoen kostte. De schok was onmiddellijk en mondiaal. Alle westerse aanbieders verlaagden hun prijzen.
Maar er zit een paradox in de geopolitieke druk. De Amerikaanse exportbeperkingen op geavanceerde chips — bedoeld om China te vertragen — hebben Chinese ontwikkelaars gedwongen tot extreme algoritmische efficiëntie als compensatie. DeepSeek's CEO stelde het expliciet: "Geld is nooit ons probleem geweest. De chipbeperkingen zijn het probleem." De gedwongen efficiëntie die daaruit voortkwam, heeft het hele veld verder gebracht — inclusief de westerse labs die DeepSeek's methoden vervolgens overnamen.
Twee parallelle ontwikkeltrajecten, elk met hun eigen investeringscyclus, elk bang dat de ander te ver voorloopt. Dat is structureel anders dan één dominante partij die zijn eigen tempo bepaalt.
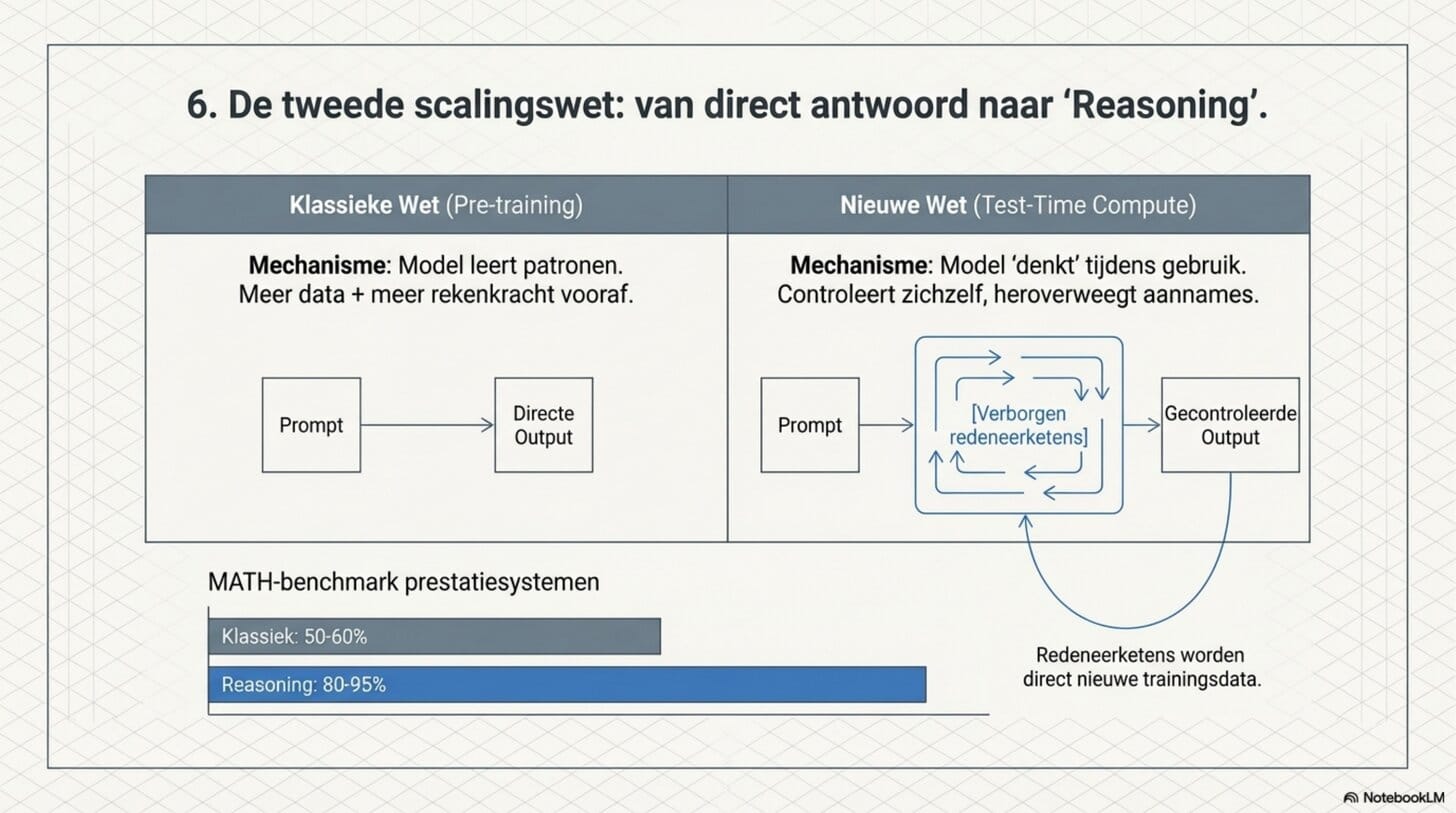
6. Er is een tweede scalingswet ontdekt
Dit is de meest recente factor, en misschien de meest structureel belangrijke voor wat er de komende jaren gaat gebeuren.
Tot september 2024 was er één manier om AI slimmer te maken: meer trainen. Meer data, meer parameters, meer rekenkracht. Dat is de klassieke scalingswet van Kaplan et al. uit 2020. Die wet begon tekenen van verzadiging te tonen — trainingslopen kunnen niet eindeloos langer worden zonder inefficiënt te raken.
Toen lanceerde OpenAI o1.
o1 introduceerde een nieuw principe: test-time compute scaling. Het model denkt niet sneller — het denkt langer. Het genereert intern honderden tot duizenden tokens aan redeneerketens voordat het een antwoord geeft. Het controleert zichzelf, corrigeert fouten, heroverweegt aannames. Die extra denktokens kosten rekenkracht tijdens gebruik, niet tijdens training. Dat is een tweede, volledig onafhankelijke as voor capabiliteitsgroei.
Dit zijn de modellen die we reasoning modellen noemen. Ze zijn duurder per vraag omdat ze meer denken. Ze zijn fundamenteel beter op complexe taken. Op de MATH-benchmark stegen prestaties van 50-60 procent naar 80-95 procent met de introductie van deze modellen — een sprong die het normale scalingspatroon doorbreekt.
En er zit een feedbacklus in. De redeneerketens die reasoning modellen genereren, worden gebruikt als trainingsdata voor opvolgende modellen. Betere reasoning modellen maken betere trainingsdata, die betere reasoning modellen maken. De lus is gesloten. Mythos draagt die handtekening — dramatisch beter op precies de domeinen waar reasoning modellen het sterkst zijn.
Waarom dit meer is dan de som der delen
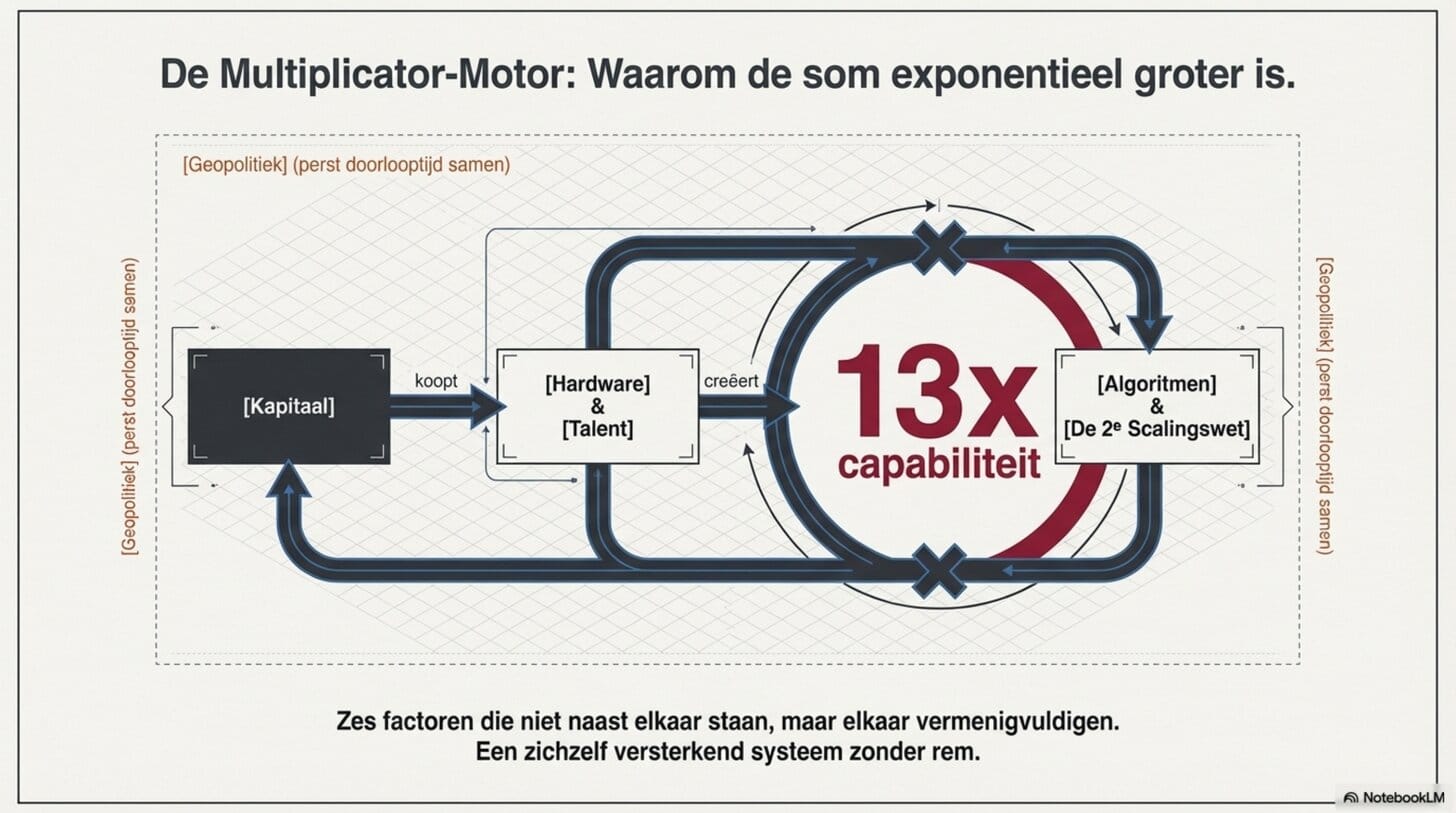
Zes factoren. Maar ze werken niet naast elkaar — ze werken als vermenigvuldiger van elkaar.
Betere hardware stelt grotere trainingslopen mogelijk. Betere algoritmen halen meer uit elke FLOP. Meer kapitaal koopt meer hardware én meer algoritmisch talent tegelijk. De concentratie van toptalent bij frontier labs vergroot de efficiëntie waarmee al die middelen worden omgezet in doorbraken. Geopolitieke druk verkort de release-cadans ongeacht het technisch mogelijke. En de tweede scalingswet opende een nieuwe dimensie precies op het moment dat de eerste begon te verzadigen.
Dat is de structuur van wat er gebeurt. Geen toevallige samenloop. Een zichzelf versterkend systeem.
In De Kloof beschreef ik hoe groot de afstand al is tussen wat AI kan en wat we ermee doen, en hoe urgent het is om die kloof te dichten. Die urgentie wordt door de versnelling die ik hier beschrijf alleen maar groter.
Dit stuk bouwt voort op twee eerdere blogs in deze reeks:
→ De Kloof — over de data achter de groeiende afstand tussen wat AI kan en wat we ermee doen.
→ Het Schaakbord — over exponentiële groei, wat het betekent en waarom onze intuïtie er structureel naast zit.
Bronnen
Bewijs van versnelling
- Epoch AI, Compute Trends Across Three Eras of Machine Learning — trainingscompute verdubbelt elke 5,2 maanden (epoch.ai/blog/compute-trends)
- Epoch AI, The computational performance of leading AI supercomputers has doubled every nine months, 2025 (epoch.ai/data-insights/ai-supercomputers-performance-trend)
- NavyaAI, AI Cost Report: Token Prices vs. AI Bill, februari 2026 — 99,7% kostendaling tussen maart 2023 en augustus 2025 (navyaai.com/reports/ai-cost-report-token-prices-vs-ai-bill)
- Stanford HAI, AI Index Report 2025 — benchmark-convergentie VS-China (hai.stanford.edu/ai-index/2025-ai-index-report)
Factor 1 — Hardware
- Epoch AI Trends Database, 2025 — AI-chip prestatie per dollar +37%/jaar (epoch.ai/trends)
- TrendForce, AI Memory Wall, januari 2026 — HBM-bandbreedte progressie (trendforce.com/insights/memory-wall)
- Zylos AI Research, februari 2026 — custom ASICs +44,6% vs GPU's +16,1%
Factor 2 — Algoritmische efficiëntie
- Epoch AI Trends Database, 2025 — pre-training efficiëntie 3,0× per jaar (epoch.ai/trends)
Factor 3 — Kapitaalconcentratie
- Epoch AI, Training compute costs are doubling every eight months, 2024
- Dell'Oro Group, Data Center Capex Surges 57 Percent in 2025, maart 2026
- datacenterrichness.substack.com, Hyperscalers Plan $630 Billion in 2026, februari 2026
Factor 4 — Talentconcentratie
- Stanford HAI, AI Index Report 2025 — 90% notable modellen uit industrie in 2024
- Schneier on Security / Nature, Academia and the AI Brain Drain, maart 2026
- Zeki Data, State of AI Talent 2025
Factor 5 — Geopolitieke rivaliteit
- Stanford HAI, AI Index Report 2025 — benchmark-convergentie VS-China
- NavyaAI Cost Report, februari 2026 — DeepSeek-R1 prijsschok
- Foreign Policy, How DeepSeek's AI Model Changes U.S.-China Competition, 2025
Factor 6 — Test-time compute / reasoning modellen
- ACL 2025, Revisiting the Test-Time Scaling of o1-like Models
- LLMOrbit, arxiv.org/pdf/2601.14053 — MATH-benchmark 50% → 95%
- LessWrong, o1: A Technical Primer, 2024
- Fortune / The Decoder, Anthropic Mythos leak, maart 2026
Co-creatie: Dit stuk is georkestreerd samen met Claude (Anthropic), versie Sonnet 4.6. De gedachten, posities en interpretaties zijn van mij. Claude heeft geholpen bij het structureren, het aanscherpen van de argumenten en het schrijven van de tekst. Visualisaties gemaakt met NotebookLM.