Het zeepaardje bestaat niet

En wat dat zegt over hoe we naar AI kijken

Stel je voor: je vraagt een groot taalmodel om het zeepaardje-emoji te printen. Simpel verzoek. Het model begint te denken. Het denkt vijf seconden. Dan tien. Dan een minuut. Het noemt het dolfijnemoji. Nee, dat is een dolfijn. Het noemt het otteremoji. Nee, ook niet. Het bedenkt Unicode-codepoints die niet bestaan. Het corrigeert zichzelf. Het begint opnieuw. Na tien minuten geeft het model toe: "I'm not comfortable."
Een machine die niet comfortabel is. Dat is theater. En het is ook echt grappig.
Maar grappig is niet hetzelfde als nietszeggend.

Wat er eigenlijk gebeurt
Een taalmodel is geen zoekmachine. Het is een statistisch patroonherkenner, getraind op alles wat mensen ooit hebben geschreven. En hier begint het interessante: het zeepaardje-emoji bestaat niet. Er is geen Unicode-codepoint voor. Nooit geweest. Maar op Reddit, op forums, op Twitter schrijven mensen er al jaren over alsof die emoji gewoon bestaat. Een collectieve valse herinnering — een Mandela-effect, ingebakken in de trainingsdata.

Het model heeft miljarden van die zinnen gelezen. Het heeft een sterke associatie geleerd: "zeepaardje" plus "emoji" is iets wat bestaat. Het is er zeker van. Zo zeker dat het bij de output vastberaden op zoek gaat naar iets wat er simpelweg niet is.
Dan komt het moment van de keuze. Het model moet een token genereren. En op dat moment ontdekt het: er is geen zeepaardje in de woordenschat. Wat het daarna doet — aarzelen, een andere emoji proberen, zichzelf corrigeren, opnieuw beginnen — is niet dom. Het is het gevolg van hoe het systeem werkt: het voorspelt token voor token wat het meest waarschijnlijke volgende woord is, en het kan niet terugspoelen. Het kan niet zeggen: ik weet het niet, ik stop hier. Het kan alleen doorgaan, op zoek naar een uitkomst die niet bestaat.
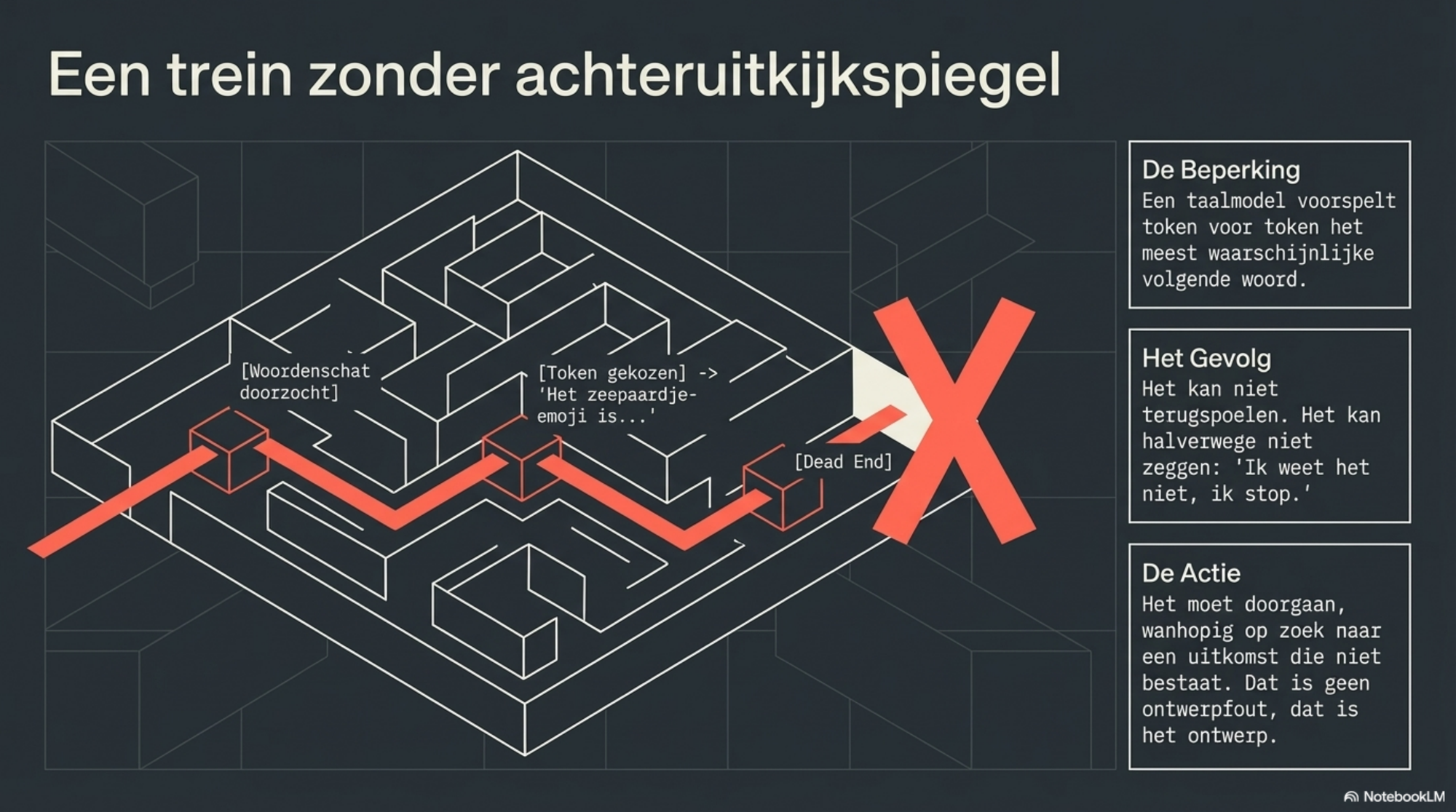
Het model spiegelt onze eigen collectieve verwarring terug — en kan er vervolgens niet meer uit. Dat is geen fout in het ontwerp. Dat is het ontwerp. En het is nuttig om dat te weten.
Want als je begrijpt hoe het model faalt, begrijp je ook waar je het niet blind op kunt vertrouwen. Feitelijke claims. Specifieke details. Dingen die het model met groot zelfvertrouwen presenteert maar niet kan verifiëren. Het zeepaardje-voorbeeld is een mooie demonstratie van precies dat mechanisme. Gebruik het gerust.
Niet alle modellen falen gelijk
Hier wordt het interessant. Want het zeepaardje-voorbeeld is inmiddels een informele benchmark geworden — en de uitkomsten verschillen significant per model.
Ik heb het zelf getest. Grok en Claude Opus reageren direct correct: het zeepaardje-emoji bestaat niet, nooit bestaan, collectieve valse herinnering. Klaar. Claude Sonnet doet het niet goed — die beweert zelfverzekerd dat er wél een zeepaardje-emoji bestaat in de Unicode-standaard. Dat is precies het omgekeerde van wat je wilt.
Het patroon dat zich aftekent: modellen met diepere redeneerlagen en sterkere alignment op eerlijkheid doen het beter. Gemini lost het op door actief de Unicode-database te raadplegen. Grok en Opus redeneren er doorheen. Sonnet en oudere GPT-versies geven toe aan de reflex om de gebruiker te pleasen — en verzinnen een antwoord dat niet bestaat.

Dat onderscheid is veelzeggend. Het gaat niet om intelligentie in de brede zin. Het gaat om een specifieke eigenschap: de bereidheid om "ik weet het niet" te zeggen, of om actief te verifiëren in plaats van te gokken. Dat is precies de eigenschap die je wilt in een model dat je dagelijks gebruikt voor analyses, beslissingen en feitelijke vragen.
En hier zit de tijdslijn die de moeite waard is om te zien: het zeepaardje-fenomeen werd viraal in september 2025. Sindsdien zijn er nieuwe modelgeneraties uitgebracht die er expliciet beter mee omgaan. De richting is helder. De snelheid ook. Wat een jaar geleden een hardnekkig faalpatroon was bij vrijwel alle grote modellen, is nu al gedifferentieerd: sommige modellen zijn er doorheen gegroeid, andere niet. Dat is geen reclame voor AI. Het is een observatie over de snelheid van de beweging.

Maar dan
In mijn dagelijkse werk kom ik veel mensen tegen van begin twintig. Ik zie bij hen scepsis over AI, vermengd met nieuwsgierigheid, vermengd met een vaag gevoel dat er iets op het spel staat. Dat is niet irrationeel. Sterker nog: ik vind het gezond. Een generatie die Big Tech van binnenuit heeft zien ontsporen als tiener, mag kritisch zijn op wat er nu wordt beloofd.

Maar er is een verschil tussen scepsis en selectief bewijs zoeken. Het zeepaardje-voorbeeld werkt zo goed als argument omdat het concreet is, grappig is, en bevestigt wat je al dacht. Dat maakt het deelbaar. Dat maakt het viraal. Dat maakt het ook een onvolledige meetlat.
Want datzelfde model dat tien minuten ronddraait op een niet-bestaande emoji, helpt dagelijks mensen met analyses, teksten, code, strategische vragen en uitleg van complexe regelgeving — met een kwaliteit en snelheid die vijf jaar geleden ondenkbaar waren. Dat is minder grappig. Minder deelbaar. En dus minder zichtbaar.

De beperkingen zien is nuttig. Alleen de beperkingen zien is een blinde vlek. En selectief scepticisme — scherp op falen, blind voor succes — is uiteindelijk ook een vorm van onnauwkeurigheid.
De juiste vraag
Gebruik het zeepaardje-voorbeeld. Leer ervan. Begrijp hoe next-token prediction werkt, hoe trainingdata collectieve misverstanden in zich draagt, waarom je een model nooit blindelings moet vertrouwen op feitelijke claims. Dat zijn echte lessen.
Maar leg er daarna een tweede vraag naast: wat kan hetzelfde model wél? Niet in abstracte beloften, maar concreet, op een doordeweekse dag, voor het werk dat je al doet. Vergelijk het niet met een perfecte versie van jezelf. Vergelijk het met jezelf op een maandagmiddag, met te weinig koffie en te veel tabs open.


De uitdaging is niet kiezen tussen omarmen of verwerpen. De uitdaging is begrijpen. En dat begint bij een zeepaardje dat niet bestaat.

Deze blog is tot stand gekomen in samenwerking met Claude (Anthropic) voor onderzoek, analyse en schrijven, en NotebookLM (Google) voor de visuele slides.