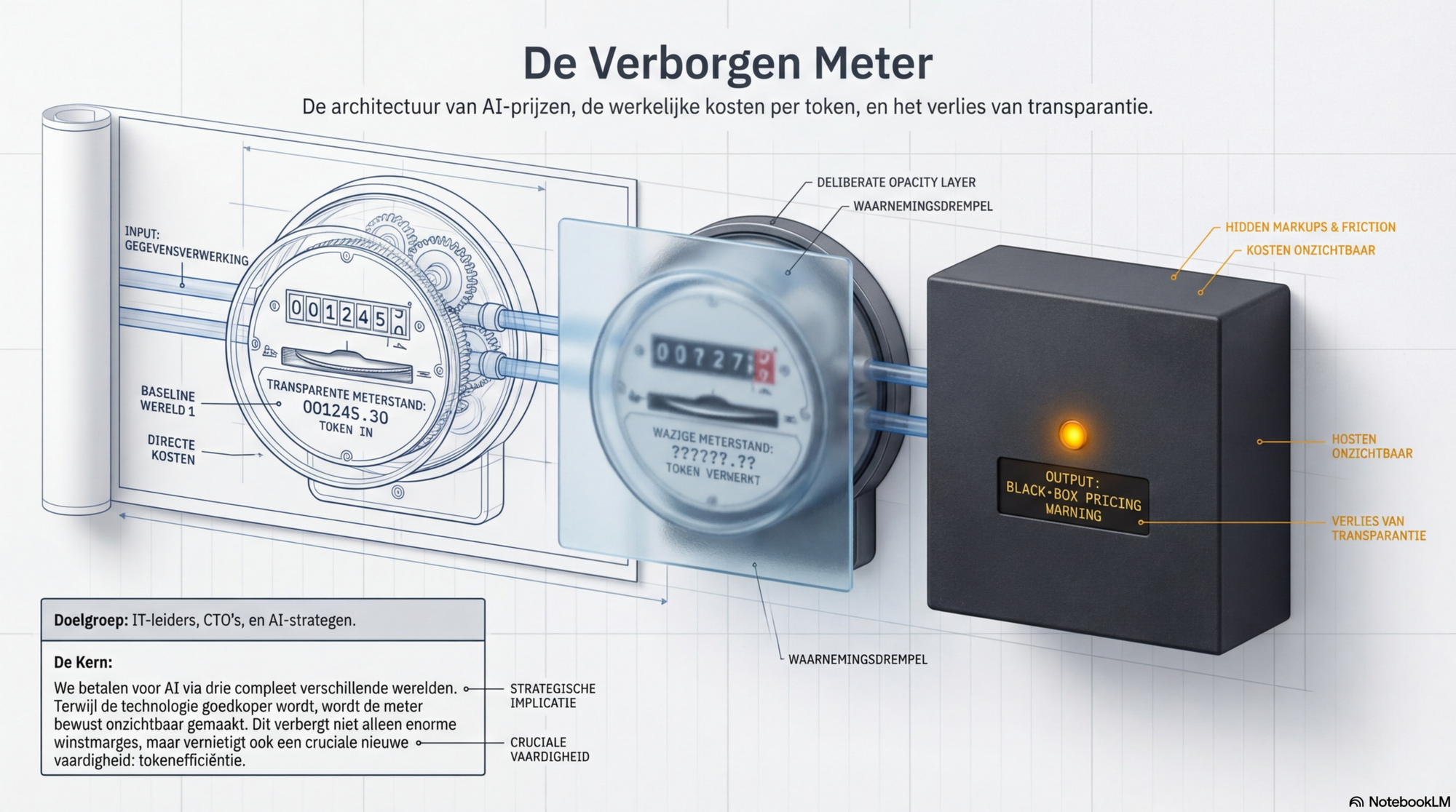
De meter die lastig is te lezen

Drie manieren waarop je vandaag voor AI betaalt
Ik zat in de auto met een collega. We bespraken mijn blogreeks over tokens — hoe de tokeneconomie zich razendsnel ontwikkelt, hoe SAP zijn verdienmodel heeft omgegooid, hoe de token de nieuwe rekeneenheid voor intelligentie wordt.
Zijn reactie was simpel: "Leuk die reeks over tokens. Maar bij ons GitHub Copilot-abonnement wordt helemaal niet gerekend in tokens. Wij betalen in requests."
Hij had gelijk. En zijn opmerking was de aanleiding voor deze blog.
Want zodra je begint uit te zoeken wat er achter die requests zit — wat ze kosten, hoe ze zich verhouden tot tokens, en wat je werkelijk betaalt voor de AI die je dagelijks gebruikt — stuit je op een pricing-architectuur die voor de meeste gebruikers bewust lastig leesbaar is gemaakt. Niet onmogelijk. Maar je moet er actief moeite voor doen.
Dit stuk is dieper en technischer dan de vorige vier in deze reeks. Dat kon niet anders. De ondoorzichtigheid van AI-pricing zit in de details — en die details zijn de boodschap. Wie alleen de conclusie wil: abonnementen zijn altijd duurder per token dan directe API-toegang, variërend van een factor 3 bij intensief gebruik tot een factor 100 bij licht gebruik van een Max- of enterprise-abonnement. Hoe dat precies werkt — en waarom het ertoe doet — leg ik hieronder uit.
Dit is de vijfde blog in mijn reeks over tokens. De eerdere vier vind je onderaan deze pagina.
Er zijn vandaag drie manieren waarop je voor AI betaalt. Elk met een andere eenheid, een andere logica, en een andere mate van transparantie.
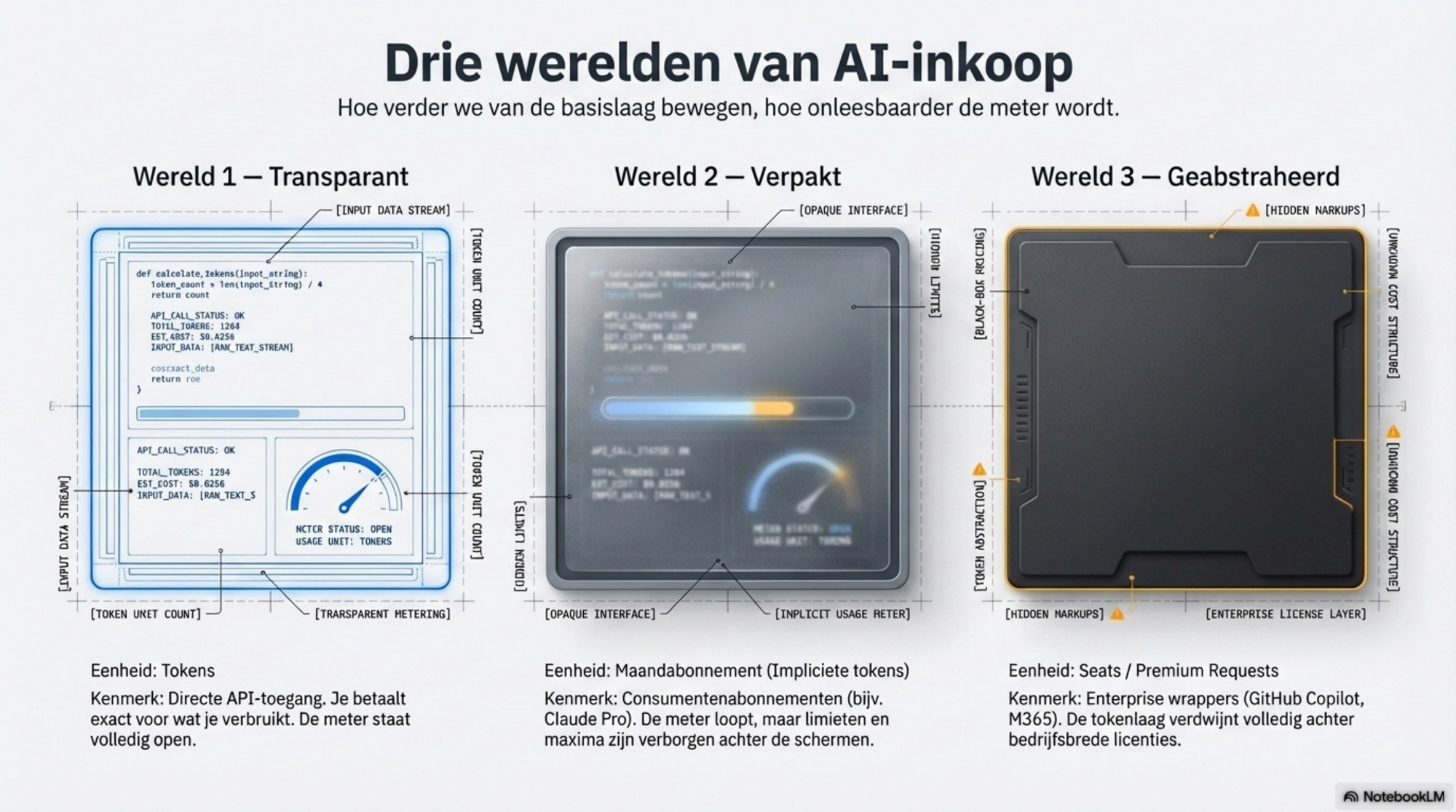
Wereld 1 — Transparant
Directe API-toegang: prijs per miljoen tokens, alles openbaar
Wie rechtstreeks via een API een AI-model aanroept, ziet precies wat hij betaalt. Anthropic, OpenAI, Google en xAI publiceren hun tarieven per miljoen tokens — input en output apart. Dat is de zuiverste vorm: de meter staat open.
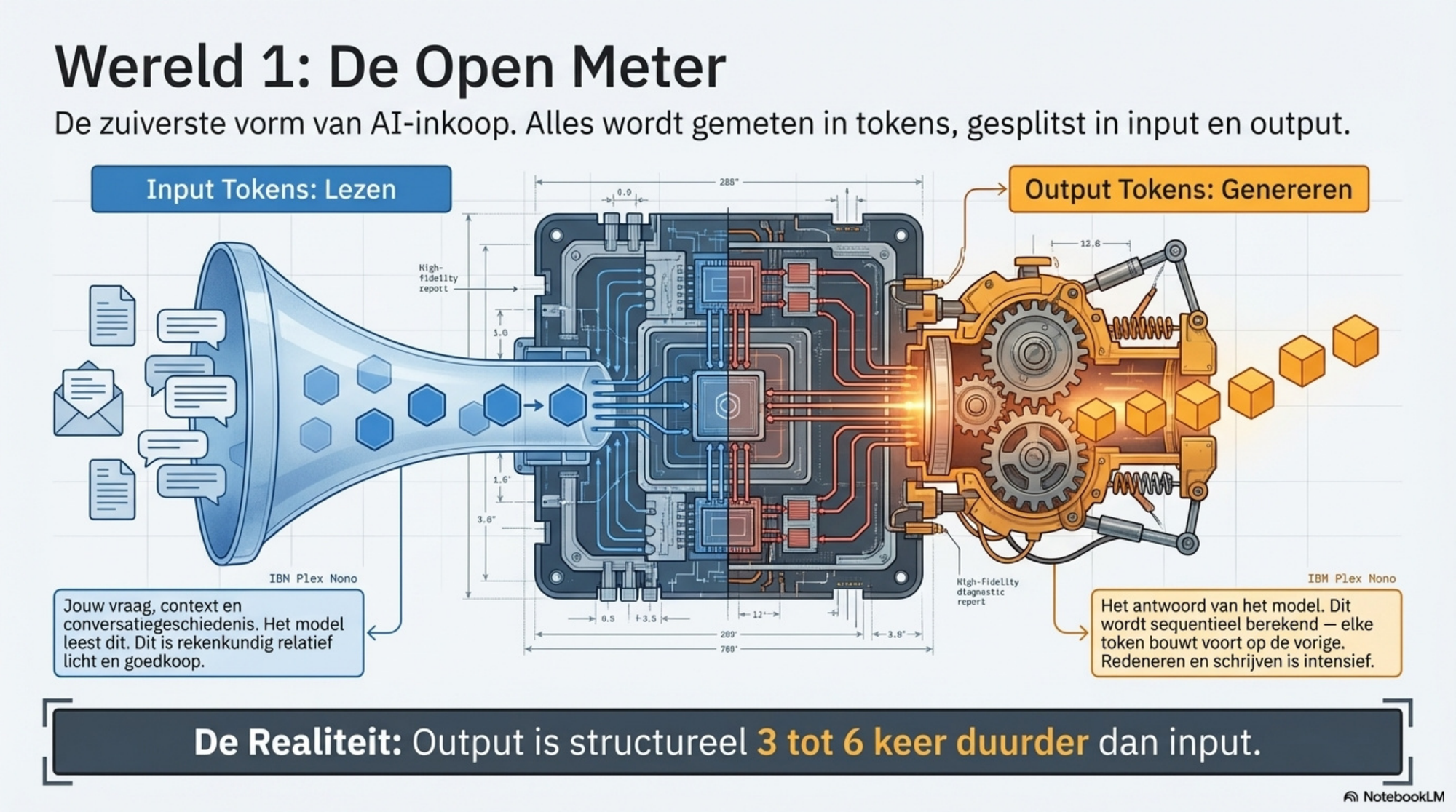
Wat zijn input- en output-tokens?
Elke keer dat je een model aanroept, stuur je tekst mee — jouw vraag, de conversatiegeschiedenis, instructies, context. Dat zijn input tokens. Wat het model teruggeeft — het antwoord — zijn output tokens. Ze worden apart geteld en apart geprijsd, en dat verschil is aanzienlijk.
Output tokens zijn structureel duurder dan input tokens — bij de meeste modellen drie tot zes keer zo duur. De reden: een model lezen kost relatief weinig; een model laten genereren is intensiever. Bij het produceren van output wordt elke token sequentieel berekend. Hoe meer het model schrijft, redeneert of uitwerkt, hoe hoger de outputkosten.
De modellen naast elkaar
De markt heeft twee duidelijke lagen: flagship-modellen voor de zwaarste taken, en mid-tier-modellen die het werk voor de meeste toepassingen uitstekend doen.
Flagship-modellen (maart 2026):
| Aanbieder | Model | Input $/M | Output $/M | Noot |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.6 | $5,00 | $25,00 | Standaard flagship |
| OpenAI | GPT-5.4 | $2,50 | $15,00 | Standaard flagship |
| OpenAI | GPT-5.4 Pro | $30,00 | $180,00 | Extreme reasoning-variant |
| Gemini 3.1 Pro | $2,00 | $12,00 | Standaard flagship | |
| xAI | Grok 4 | $3,00 | $15,00 | Standaard flagship |
Mid-tier-modellen:
| Aanbieder | Model | Input $/M | Output $/M |
|---|---|---|---|
| Anthropic | Claude Sonnet 4.6 | $3,00 | $15,00 |
| Anthropic | Claude Haiku 4.5 | $1,00 | $5,00 |
| OpenAI | GPT-5.4 mini | $0,25 | $2,00 |
| Gemini 2.5 Flash | $0,30 | $2,50 | |
| xAI | Grok 4.1 Fast | $0,20 | $0,50 |

Een noot over GPT-5.4 Pro: met $180 per miljoen output tokens is dit een extreme variant bedoeld voor de zwaarste enterprise-redeneerrtaken — zeven keer duurder dan Claude Opus op output. Dit is niet wat de meeste organisaties gebruiken. Het staat hier als illustratie van hoe breed de prijsbandbreedte in de transparante wereld loopt.
In wereld 1 is de eenheid token. De relatie is transparant. Je betaalt precies wat je verbruikt — en je kunt vooraf berekenen wat een andere aanpak kost.
Wereld 2 — Verpakt
Consumentenabonnementen: tokenprijs verborgen, maar terugrekbaar
De tweede wereld is die van de maandabonnementen. Je betaalt een vast bedrag per maand. Je weet globaal welk model je krijgt. Maar hoeveel tokens je verbruikt staat nergens. De meter loopt, maar je kunt hem niet direct aflezen.

Toch is hij te reconstrueren — als je de moeite neemt. Ik doe dat hier uitgebreid voor Claude Pro, omdat het de aanbieder is met de meeste transparantie over hoe haar limietsysteem werkt. Dan vergelijk ik de conclusies met de andere grote aanbieders.
Claude Pro — een volledige doorrekening
Wat Anthropic officieel zegt
Dit is wat Anthropic publiceert in haar Help Center:
- Prijs: $20 per maand ($17 bij jaarlijkse betaling)
- Toegang tot alle modellen: Opus 4.6, Sonnet 4.6, Haiku 4.5
- Gebruik reset elke 5 uur — een rolling window dat begint bij je eerste bericht
- Tijdens piekuren minstens 5× meer gebruik per sessie dan de gratis versie
- Er is een wekelijkse limiet die van toepassing is op alle modellen en reset 7 dagen na je sessiestart
- Het aantal berichten dat je kunt sturen varieert op basis van: berichtlengte, bestandsgrootte, gesprekslengte, modelkeuze en features
- Extra gebruik is mogelijk tegen standaard API-tarieven nadat je de inbegrepen limiet hebt bereikt
Wat Anthropic niet publiceert: het exacte tokenbudget per 5-uurs venster, de exacte weeklimiet in tokens of uren, of de verhouding tussen die twee.
Wat je wél kunt zien — en wat dat je vertelt
Claude is hier eerlijker dan de meeste concurrenten. Via Settings → Usage zie je twee voortgangsbalken: één voor je huidige 5-uurs sessie (hoeveel je hebt verbruikt en hoeveel tijd er nog resteert), en één voor je weeklimiet (wanneer die reset). In Claude Code kun je via het /usage-commando je tokenverbruik voor de huidige sessie zien — inclusief uitsplitsing naar model.
Maar — en dit is de kern van het probleem — de balken tonen een relatieve voortgang zonder dat je weet wat het maximum is. Je ziet "je hebt 40% van je sessie verbruikt", niet "je hebt 17.600 van je 44.000 tokens verbruikt." Je kunt bijhouden of je de limiet nadert, maar je kunt niet berekenen hoeveel ruimte je hebt of hoeveel een specifieke taak gaat kosten. Het is een halfopen meter: zichtbaar genoeg om te waarschuwen, te gesloten om te sturen.
Ter vergelijking: de directe API geeft je bij elke aanroep het exacte tokenverbruik terug — input, output, cache — in de response headers. Dat is de werkelijk open meter.
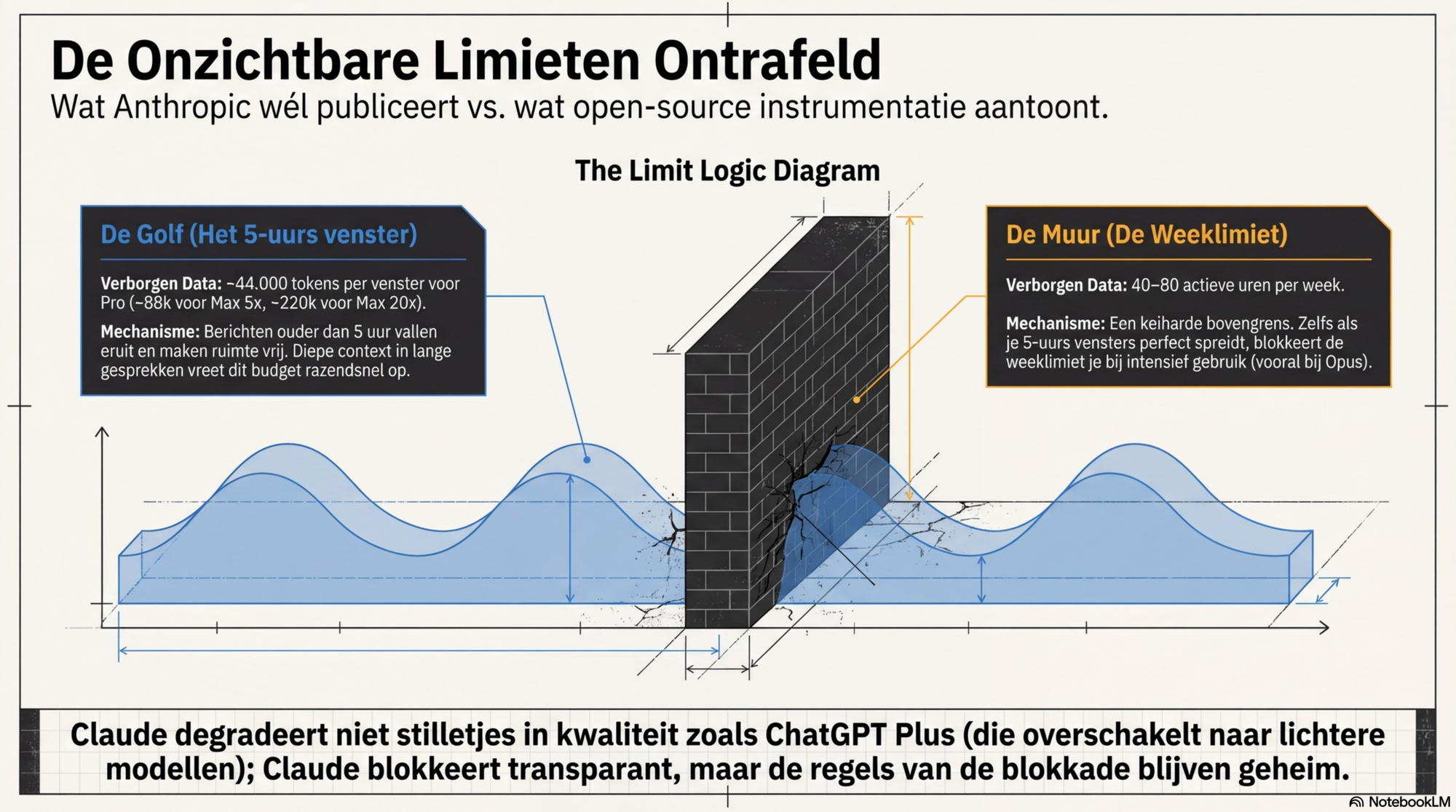
Wat community-instrumentatie toevoegt
Via open-source tools die lokale sessiebestanden van Claude analyseren (onder andere ccusage, Claude Code Usage Monitor) is het tokenbudget per 5-uurs venster consistent teruggemeten. Deze cijfers zijn niet officieel bevestigd door Anthropic, maar worden breed gerapporteerd:
- Pro: ~44.000 tokens per 5-uurs venster
- Max 5×: ~88.000 tokens per 5-uurs venster (5× Pro)
- Max 20×: ~220.000 tokens per 5-uurs venster (20× Pro)
Over de weeklimiet is minder harde data beschikbaar. Eén gespecialiseerde tracking-tool (Usagebar) rapporteert voor Pro 40–80 "actieve uren" per week. Anthropic bevestigt alleen dat de weeklimiet bestaat en minder dan 5% van de gebruikers raakt bij normaal gebruik met Sonnet. Voor Opus is er een aparte, strengere weeklimiet.
Hoe de limieten in de praktijk werken
Het 5-uurs venster is een rolling window: je budget loopt niet leeg op een vast tijdstip maar vervalt geleidelijk — berichten die 5 uur geleden zijn gestuurd vallen buiten het venster en maken ruimte vrij. Een bericht diep in een lange conversatie kost bovendien veel meer dan een vers bericht, omdat de volledige gespreksgeschiedenis elke keer opnieuw als context wordt meegestuurd.
De weeklimiet werkt als een bovengrens onafhankelijk van de 5-uurs vensters. Zelfs als je technisch gezien meerdere volle 5-uurs vensters in een week zou kunnen doorlopen, stopt de weeklimiet dat bij zwaar gebruik. Ontwikkelaars die Claude Code intensief gebruiken met Opus rapporteren de weeklimiet al na enkele dagen te raken.
Drie gebruikerstypes
Ik werk met drie scenario's die de breedte van het gebruik illustreren.
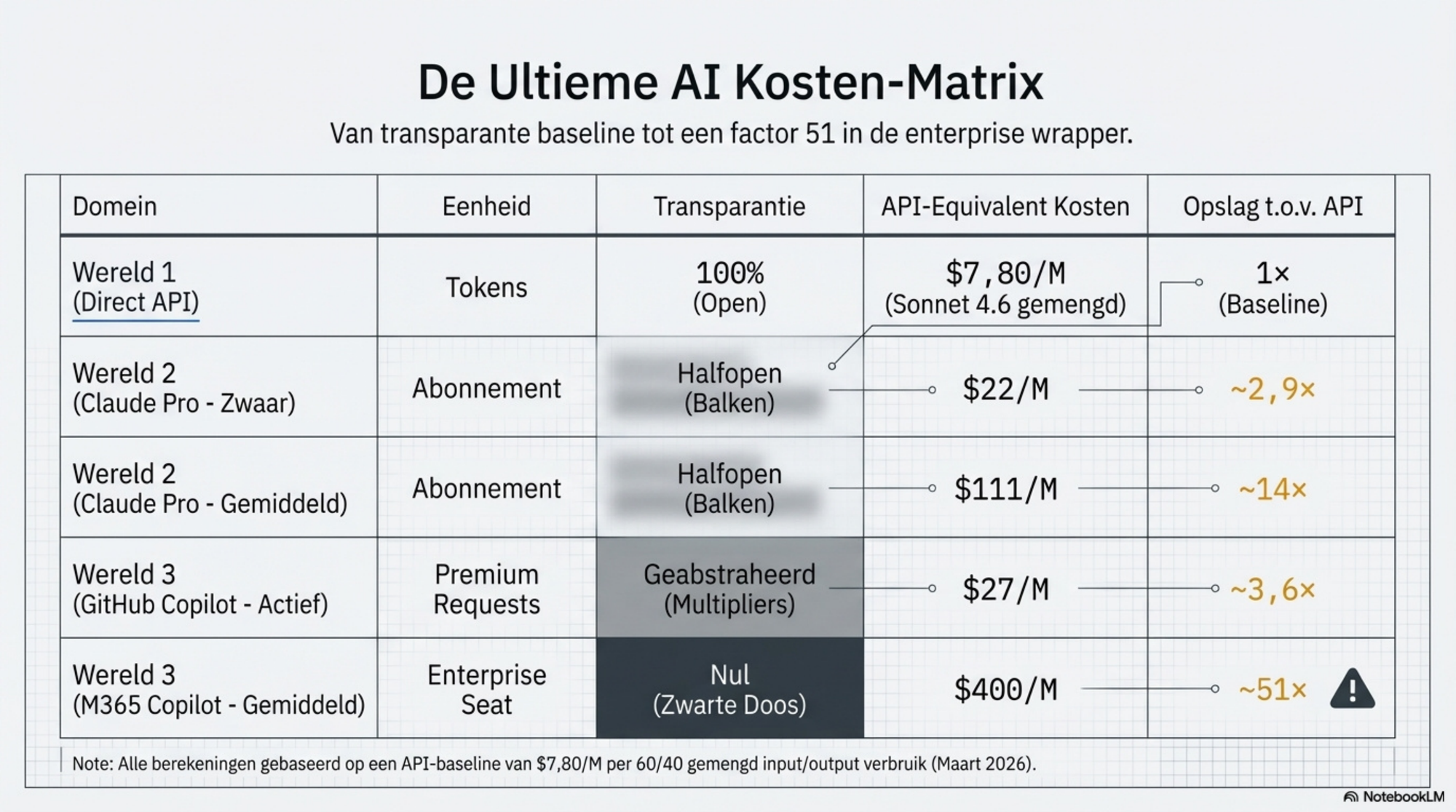
Aanname: gemengde tokenverhouding van 60% input / 40% output. API-referentieprijs voor Sonnet 4.6: $7,80/M tokens gemengd (0,6 × $3 + 0,4 × $15).
Type 1 — Gemiddelde gebruiker
De gemiddelde betaalde gebruiker van een AI-chatassistent stuurt 4–5 berichten per dag (bron: OpenAI/Harvard-onderzoek september 2025, 1,5 miljoen geanonimiseerde conversaties). Bij 20 werkdagen per maand: ~80–100 interacties. Gesprekken zijn relatief kort en vers, weinig diep context.
Schatting: ~2.000 tokens per interactie gemiddeld → ~160.000–200.000 tokens per maand.
Raakt de 5-uurs limiet? Vrijwel nooit. 80 berichten × 2.000 tokens = 160.000 tokens per maand. Het 5-uurs venster van 44.000 tokens staat voor ~22 verse berichten — een gemiddelde gebruiker haalt dit venster niet vol in één sessie. Raakt de weeklimiet? Nee.
Type 2 — Zware gebruiker
Een kenniswerker die Claude intensief gebruikt voor schrijven, analyse en research. Meerdere sessies per dag, langere gesprekken met meer context.
Schatting: ~300 interacties per maand, gemiddeld ~3.000 tokens per interactie (conversatiegeschiedenis telt mee) → ~900.000 tokens per maand.
Raakt de 5-uurs limiet? Ja, regelmatig. Wie langere gesprekken voert en meerdere sessies per dag heeft, raakt het 5-uurs venster wekelijks een paar keer. Raakt de weeklimiet? Mogelijk bij intensieve weken. Bij ~225.000 tokens per week (300/4 × 3.000) zit je bij het hogere einde van de gerapporteerde weeklimiet.
Type 3 — Theoretische max-gebruiker
Iemand die het abonnement structureel zo intensief mogelijk benut: elke 5 uur een volledig benut venster, elke dag. In theorie: 4–5 vensters per werkdag × 44.000 tokens = ~176.000–220.000 tokens/dag × 20 werkdagen = ~3,5–4,4 miljoen tokens per maand.
Maar: de weeklimiet begrens dit. Als de gerapporteerde bovengrens van ~80 actieve uren per week voor Pro klopt, dan is het praktische maximum per week ruwweg ~1,5–2 miljoen tokens (afhankelijk van gebruiksintensiteit). Maandelijks: ~6–8 miljoen tokens is dan het theoretisch bereikbare voor Max 20×. Voor Pro is het reeëler om op ~500.000–1.000.000 tokens per maand te rekenen als daadwerkelijk maximum, als de weeklimiet de begrensende factor is.
Hoe moeilijk is het om een echte max-gebruiker te zijn? Zeer moeilijk. Je moet elke 5 uur actief beginnen aan een nieuw intensief gebruik, de volledige dag, elke werkdag. Zware modellen zoals Opus versnel je daarin — maar die hebben ook een strengere aparte weeklimiet. De meeste mensen die denken "ik gebruik Claude Pro intensief" zitten in werkelijkheid dichter bij het zware gebruikerstype dan bij de theoretische max.
Wat de weeklimiet doet met de zware gebruiker
De zware gebruiker wil in theorie 900.000 tokens per maand verbruiken — 300 interacties van gemiddeld 3.000 tokens. Maar de weeklimiet bijt hier. Bij ~225.000 tokens per week (dat is het gebruikspatroon van de zware gebruiker: 300/4 weken × 3.000 tokens) zit je aan de bovenkant van de gerapporteerde Pro-weeklimiet. In drukke weken — meerdere lange sessies, Opus als model, grote bestanden — raakt de zware gebruiker de weeklimiet en kan hij niet meer de volle 900.000 tokens halen.
Realistisch ligt het daadwerkelijk bereikbare voor een zware Pro-gebruiker eerder op ~700.000–750.000 tokens per maand, omdat de weeklimiet de begrensende factor is. Dat verhoogt de effectieve prijs per token licht ten opzichte van de theoretische 900.000: bij 750.000 tokens betaal je $20 ÷ 0,75M = ~$26,70/M tokens — een opslag van ~3,4× de API-prijs in plaats van 2,9×.
Het verschil tussen 2,9× en 3,4× is klein. Wat het illustreert is groter: de weeklimiet is een onzichtbare correctie op wat je dacht te kunnen gebruiken. Je ziet hem aankomen via de voortgangsbalk in Settings, maar je kunt hem niet vooraf berekenen omdat je het absolute maximum niet kent.

Vergelijking met de API
| Gebruikerstype | Est. tokens/maand | API-kosten (Sonnet $7,80/M) | Claude Pro ($20) | Opslag |
|---|---|---|---|---|
| Gemiddeld | ~180.000 | ~$1,40 | $20 | ~14× |
| Zwaar (theoretisch) | ~900.000 | ~$7,02 | $20 | ~2,9× |
| Zwaar (realistisch, weeklimiet) | ~750.000 | ~$5,85 | $20 | ~3,4× |
| Theoretisch max (Pro, geen weeklimiet) | ~3,5M | ~$27,30 | $20 | <1× — API duurder |
De rij "theoretisch max zonder weeklimiet" staat er als referentiepunt, niet als realistische verwachting. In de praktijk is dit voor Pro-gebruikers niet haalbaar.
De conclusie is helder: voor de gemiddelde gebruiker is Claude Pro ruwweg 14× duurder per token dan de directe API. Voor de zware gebruiker daalt dat naar 3–3,5×, afhankelijk van hoeveel de weeklimiet zijn gebruik benedenwaarts bijstelt. Daadwerkelijk goedkoper dan de API worden is op Pro in de praktijk vrijwel onmogelijk — de weeklimiet zorgt ervoor dat je het theoretische maximum nooit haalt.
Dat is niet oneerlijk — het abonnement dekt ook gemak, geen technische kennis en geen API-infrastructuur. Maar het is informatie die het abonnement zelf niet biedt.
Vergelijking met andere aanbieders
Het patroon dat bij Claude Pro zichtbaar is, geldt universeel. Elke aanbieder hanteert abonnementslimieten die de effectieve tokenprijs afhankelijk maken van gebruik — en geen enkele publiceert dat transparant.
| Plan | Prijs/maand | Limietsysteem | Gemiddeld gebruik ~180K t | Zwaar gebruik ~900K t |
|---|---|---|---|---|
| Claude Pro | $20 | 5-uurs window + weeklimiet | ~$111/M (~14×) | ~$22/M (~2,9×) |
| Claude Max 5× | $100 | 5-uurs window × 5 + weeklimiet | ~$556/M (~71×) | ~$111/M (~14×) |
| Claude Max 20× | $200 | 5-uurs window × 20 + weeklimiet | ~$1.111/M (~142×) | ~$222/M (~28×) |
| ChatGPT Plus | $20 | 3-uurs window, degradatie (geen blokkering) | ~$111/M (~14×) | ~$22/M (~2,9×) |
| ChatGPT Pro | $200 | Vrijwel onbeperkt | n.v.t. | ~$222/M (~28×) |
| SuperGrok | $30 | Niet gepubliceerd | ~$167/M (~21×) | ~$33/M (~4,2×) |
Alle "×"-getallen zijn de opslag t.o.v. Sonnet 4.6 API-prijs van $7,80/M
Twee opmerkingen bij Max 5× en Max 20×:
Max 5× en 20× zijn voor de gemiddelde gebruiker dramatisch duurder per token dan Pro — maar dat is ook niet hun doel. Ze zijn bedoeld voor developers die Claude Code intensief draaien, waarbij de 5-uurs vensters volledig worden benut en de weeklimiet de bottleneck is. Bij die intensiteit kan Max 20× goedkoper uitkomen dan directe API-betaling. Eén gedocumenteerde case: een developer die 8–10 maanden intensief Claude Code gebruikte, berekende dat zijn API-equivalent-kosten ~$15.000 waren geweest — hij betaalde ~$800 aan Max-abonnementen. Dat is een factor 19 verschil in zijn voordeel. Voor gewone kantoorgebruikers is die rekensom omgekeerd.
Een noot over ChatGPT Plus versus Claude Pro: het limietsysteem is fundamenteel anders. Claude blokkeert bij het bereiken van de limiet en is daarin transparant. ChatGPT degradeert stil naar een lichter model — je kunt blijven werken, maar op lager kwaliteitsniveau, zonder dat dit altijd duidelijk wordt gecommuniceerd. Twee visies op eerlijkheid.
Overkoepelende conclusie voor wereld 2: abonnementen zijn altijd duurder per token dan de directe API, variërend van een factor 3 bij intensief gebruik tot een factor 100+ bij licht gebruik van een duur plan. De enige uitzondering is de extremere Max-developer die werkelijk de limieten volbenut — maar daarvoor zijn die plannen ook bedoeld. De opslag dekt gemak en toegankelijkheid. Maar je kunt die afweging alleen bewust maken als je weet hoe groot die opslag is — en het abonnement zegt het je niet.
Wereld 3 — Geabstraheerd
Enterprise wrappers: de tokenlaag verdwijnt achter een eigen eenheid

De derde wereld gaat een stap verder. Hier verdwijnt niet alleen de tokenprijs — de eenheid zelf verdwijnt. Je betaalt niet meer in tokens of impliciet in tokens via een maandprijs. Je betaalt in seats, premium requests of Copilot Credits. Begrippen die zijn uitgevonden door de aanbieder, met hun eigen logica.
Microsoft M365 Copilot
De volledige Copilot-ervaring kost $30 per gebruiker per maand als add-on bovenop een bestaand M365-abonnement. Dat basisabonnement is niet gratis: Business Basic kost $6, Business Standard $12,50, Enterprise E3 $36 (stijgt naar $39 per juli 2026). Copilot Chat — een beperkte versie op basis van webdata — is al inbegrepen bij M365. De volledige Copilot met toegang tot je e-mail, agenda, Teams en SharePoint via Microsoft Graph kost de $30 extra. De eenheid is intern interacties, maar die worden niet in tokens uitgedrukt.
GitHub Copilot Business — een volledige doorrekening
Wat GitHub officieel zegt
Dit staat in de officiële GitHub-documentatie:
- Copilot Business: $19/gebruiker/maand, 300 premium requests per maand
- Copilot Enterprise: $39/gebruiker/maand + verplicht GitHub Enterprise Cloud ($21) = $60 totaal, 1.000 premium requests per maand
- Premium requests resetten op de 1e van elke maand om 00:00 UTC — niet op je factuurdatum
- Overschrijding: $0,04 per extra premium request (alleen als je dit expliciet inschakelt)
- Drie modellen zijn inbegrepen op betaalde plannen en verbruiken géén premium requests: GPT-4.1, GPT-4o en GPT-5 mini — onbeperkt te gebruiken
- Elke andere model verbruikt premium requests op basis van een multiplier
- In VS Code geeft de model-picker de multiplier zichtbaar aan naast elk model
- Gebruik is te monitoren via Copilot-instellingen op GitHub.com en direct in de IDE
De multiplier-tabel — officieel gepubliceerd door GitHub
| Model | Multiplier | Effectieve interacties uit 300 requests |
|---|---|---|
| GPT-4.1, GPT-4o, GPT-5 mini | 0× (inbegrepen) | Onbeperkt |
| Claude Haiku 4.5 | 0,33× | ~909 interacties |
| Claude Sonnet 4.6, Gemini 2.5 Pro, GPT-5 | 1× | 300 interacties |
| Claude Opus 4.5/4.6 | 3× | 100 interacties |
| Zware reasoning-modellen | 5–20× | 15–60 interacties |
Bij auto-selectie in VS Code krijg je 10% korting op de multiplier — Claude Sonnet telt dan als 0,9× in plaats van 1×.
Wat GitHub niet publiceert
Het aantal tokens per premium request staat nergens in de officiële documentatie. GitHub meet in requests, niet in tokens. Om de effectieve tokenprijs te reconstrueren heb je een aanname nodig over het gemiddelde tokenverbruik per interactie.
Wat andere bronnen toevoegen
Op basis van community-analyse van Copilot-gebruik in code-omgevingen wordt een gemiddelde van ~2.500 tokens per chat-interactie gerapporteerd voor code-gerelateerde vragen (prompt + response, inclusief codeblokken). Dit is indicatief — een korte vraag kost 500 tokens, een uitgebreide refactor-sessie 8.000+. GitHub publiceert dit getal niet.
Drie scenario's voor GitHub Copilot Business ($19/maand)
Scenario 1 — Lichte developer
Gebruikt Copilot primair voor inline suggestions en af-en-toe een chatbericht. Kiest bewust voor de inbegrepen modellen (GPT-4.1, GPT-4o) voor de dagelijkse taken, premium requests alleen voor complexere vragen.
Schatting: 80 premium requests/maand × 1× multiplier = 80 effectieve requests verbruikt van de 300. Modelkeuze: GPT-5 of Sonnet voor de zwaardere vragen, GPT-4.1 voor de rest. Tokenverbruik premium deel: 80 × 2.500 tokens = ~200.000 tokens/maand. Het inbegrepen deel (GPT-4.1 onbeperkt) telt niet mee in de kosten.
API-equivalent premium deel: 200.000 tokens × $7,80/M = ~$1,56. Betaalt: $19. Opslag: ~12×.
Scenario 2 — Actieve developer (de inbegrepen limiet)
Gebruikt de 300 premium requests volledig, met een mix van modellen: 60% Sonnet (1×), 30% Opus (3×), 10% inbegrepen modellen.
Effectieve requests: 180 Sonnet-requests + 90 Opus-requests × 3 = 270 verbruikte requests van de 300. Plus 30 inbegrepen = totaal op de limiet.
Tokenschatting: 180 × 2.500 = 450.000 tokens (Sonnet), 90 × 2.500 = 225.000 tokens (Opus). Totaal premium: ~675.000 tokens/maand.
API-equivalent: 675.000 × $7,80/M = ~$5,27. Betaalt: $19. Opslag: ~3,6×.
Maar — dit is het gemiddelde. Opus kost op de API $13/M gemengd ($5 input + $25 output). Als je de Opus-interacties apart berekent: 225.000 tokens × $13/M = $2,93 alleen voor Opus. De werkelijke API-kosten bij deze modelkeuze zijn hoger dan $7,80/M gemiddeld suggereert.
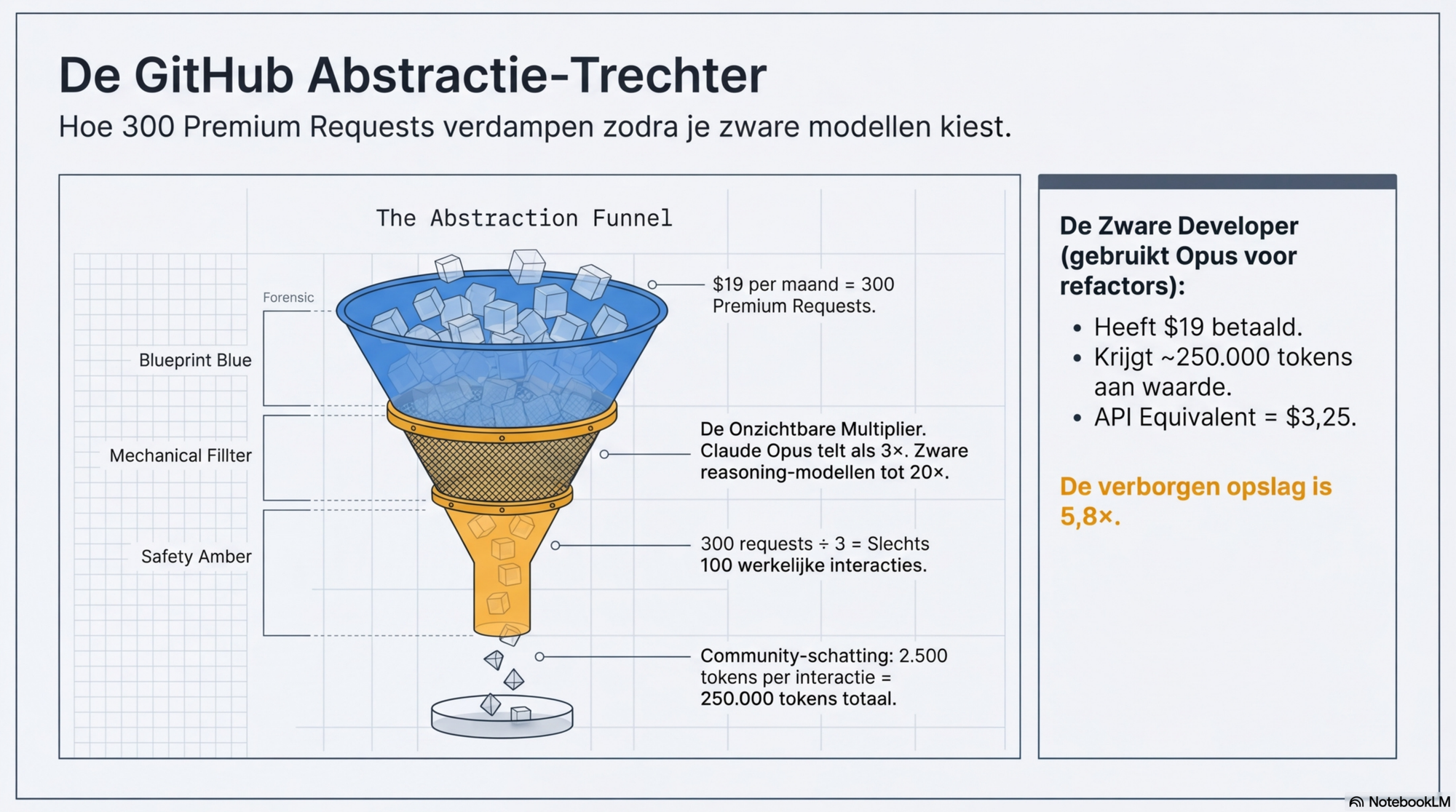
Scenario 3 — Zware developer, raakt de limiet
Werkt intensief met Claude Opus voor complexe refactors en architectural reviews. Gebruikt de 300 premium requests volledig met Opus als primair model.
300 requests ÷ 3× multiplier = 100 effectieve Opus-interacties. Tokenverbruik: 100 × 2.500 tokens = ~250.000 tokens/maand.
API-equivalent (Opus $13/M): 250.000 × $13/M = ~$3,25. Betaalt: $19. Opslag: ~5,8×.
Dit lijkt paradoxaal: de zwaarste developer met het duurste model betaalt meer opslag dan de actieve developer met een modelkeuze. Verklaring: de 3× multiplier beschermt GitHub's marge — wie Opus kiest, verbruikt zijn 300 requests drie keer zo snel en krijgt daarvoor 100 interacties in plaats van 300.
De dubbele abstractielaag
Hier zit het fundamentele verschil met Claude Pro. Bij Claude weet je welk model je gebruikt en zie je de voortgangsbalk lopen. Bij GitHub Copilot zijn er twee onbekenden tegelijk:
- Je weet niet hoeveel tokens een interactie kost — GitHub publiceert dit niet
- Je weet niet altijd welk model per interactie wordt ingezet — zeker niet bij auto-selectie
De multiplier is zichtbaar in de model-picker in VS Code, en het verbruik is te monitoren in de Copilot-instellingen. Dat is transparanter dan M365 Copilot. Maar de stap van "requests verbruikt" naar "tokens verbruikt" naar "effectieve tokenprijs" is voor de gemiddelde gebruiker niet te maken zonder aannames.
Een recent voorbeeld van hoe dit mis kan gaan: toen GitHub de Claude Opus-multiplier verhoogde van 1× naar 3× zonder duidelijke notificatie, rapporteerden meerdere gebruikers dat hun maandlimiet in enkele dagen was opgebrand. De informatie was technisch beschikbaar in de dropdown — maar actieve communicatie ontbrak.
Vergelijkingstabel GitHub Business vs. API
| Scenario | Tokens/maand (schatting) | API-kosten | GitHub Business ($19) | Opslag |
|---|---|---|---|---|
| Licht (80 req, Sonnet) | ~200.000 | ~$1,56 | $19 | ~12× |
| Actief (300 req, mix) | ~675.000 | ~$5,27* | $19 | ~3,6× |
| Zwaar (300 req, Opus) | ~250.000 | ~$3,25** | $19 | ~5,8× |
* Gemengde API-prijs $7,80/M; bij zuiver Opus-gebruik is de API-prijs hoger ** Opus API-prijs $13/M gemengd
Voorbehoud bij alle GitHub-berekeningen
Deze doorrekening is indicatiever dan de Claude Pro-analyse. De tokenbudgetten per request zijn niet officieel gepubliceerd door GitHub — 2.500 tokens per interactie is een community-schatting voor code-gerelateerde chat. Inline suggestions tellen als aparte requests maar verbruiken minder tokens. Wie primair inline suggestions gebruikt en zelden chat, zit op een veel gunstiger verhouding. Wie lange agent-sessies draait met Opus, zit op een veel ongunstigere.
Google Workspace
Google heeft in januari 2025 de aparte Gemini-add-ons volledig afgeschaft. Gemini AI zit sindsdien ingebundeld in alle Workspace-abonnementen met een prijsverhoging van 17–22%. Business Standard kost nu $14/gebruiker. Er is geen aparte AI-eenheid en geen verbruiksmeter — de AI zit in de basisprijs verwerkt, volledig onzichtbaar.
Waarom het tokenverbruik in wereld 3 zo lastig te bepalen is
M365 Copilot heeft geen verbruiksmeter. Google Workspace heeft geen aparte AI-eenheid. GitHub Copilot heeft een requestmeter maar geen tokenmeter, en de stap van requests naar tokens vereist kennis van welk model per request werd ingezet. De abstractielaag is in alle gevallen zo ontworpen dat de verbinding tussen gebruik en kosten niet direct zichtbaar is.
Doorrekening M365 Copilot
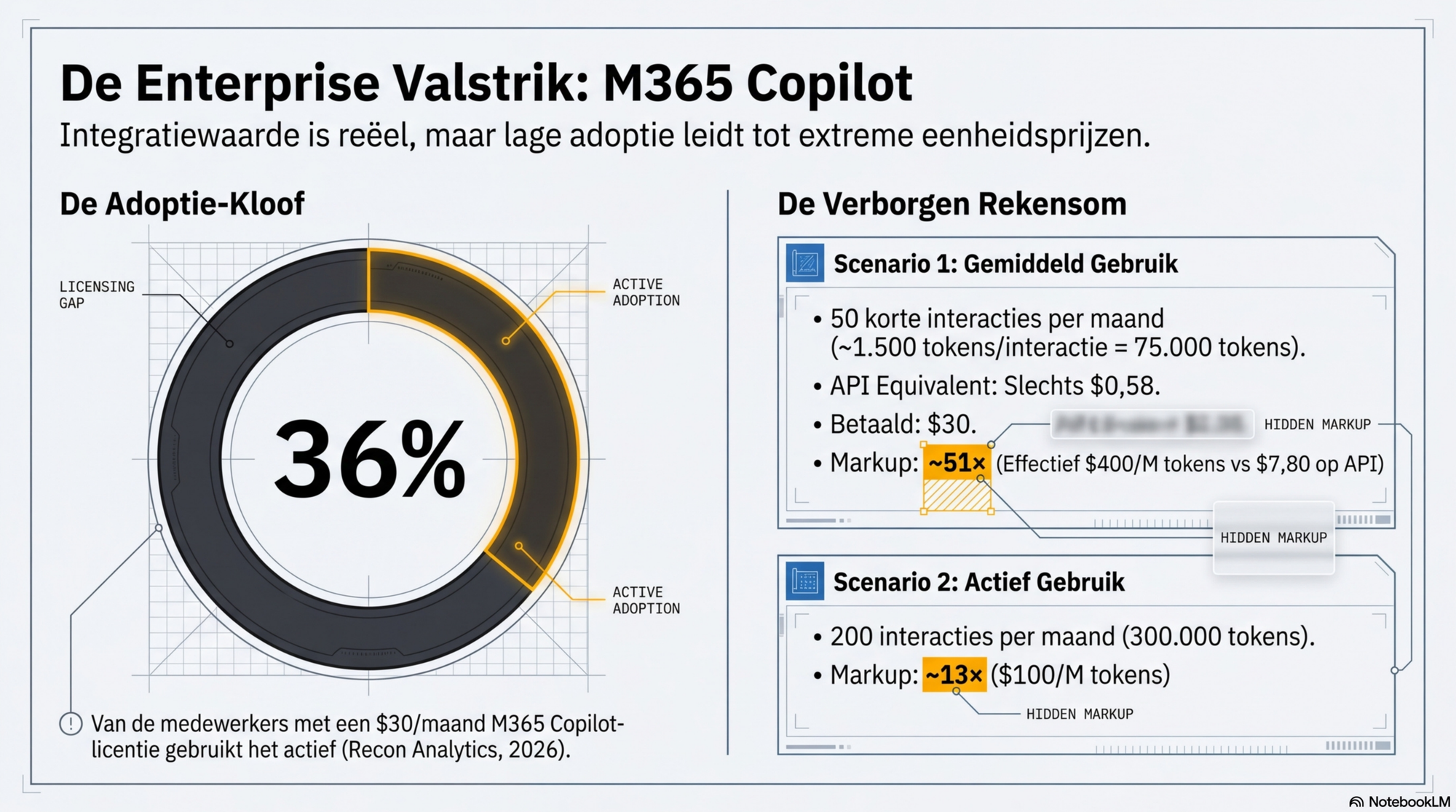
Adoptie is het grootste probleem. Onderzoek van Recon Analytics (begin 2026): slechts 36% van medewerkers met M365 Copilot-toegang gebruikt het actief. Microsoft rapporteerde ~8 miljoen actieve gelicenseerde gebruikers op 440 miljoen M365-abonnees. Interacties zijn korter dan bij een dedicated AI-tool: ~1.500 tokens per interactie.
| Scenario | Prijs AI-deel | Est. tokens/maand | Eff. prijs/M tokens | Vs. Sonnet API |
|---|---|---|---|---|
| Gemiddeld gebruik (50 int./seat) | $30 add-on | ~75.000 | ~$400/M | ~51× |
| Actief gebruik (200 int./seat) | $30 add-on | ~300.000 | ~$100/M | ~13× |
Het getal van 51× bij gemiddeld gebruik is de rekensom: $30 ÷ 0,075M tokens = $400 per miljoen tokens, versus $7,80 via de API. De integratieverwaarde van M365 Copilot is reëel — maar bij lage adoptie betaal je die integratie op een extreem ongunstige tokenverhouding.
De prikkel tot efficiëntie ontbreekt
In wereld 3 is de fundamentele prikkel weg. In wereld 1 staat elke inefficiënte prompt direct op de rekening. In wereld 3 betaalt een medewerker die tien vage prompts schrijft die elk twintig keer meer tokens kosten dan nodig, exact hetzelfde als een medewerker die scherp en precies werkt. De prikkel tot tokenefficiëntie — de cognitieve vaardigheid die ik in de derde blog beschreef — bestaat structureel niet in een seat-gebaseerde wereld.
Waarom de marge structureel groeit
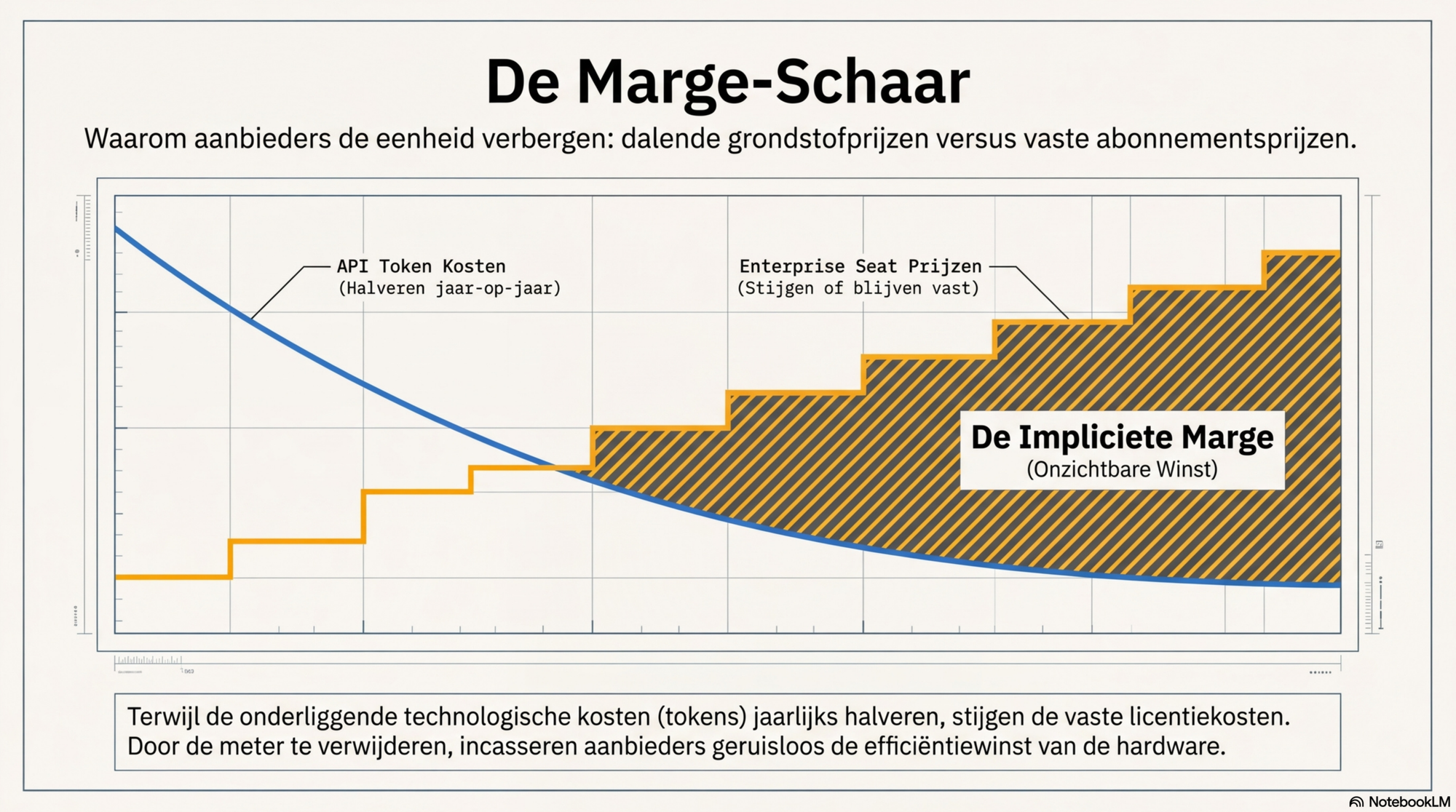
API-tokenkosten halveren elk jaar. Dat is een consistente trend van de afgelopen drie jaar — een Sonnet-kwaliteitsmodel kostte twee jaar geleden driemaal zoveel per token als vandaag. De abonnementsprijzen bewegen niet mee omlaag. Microsoft verhoogde M365-licenties in 2025 en kondigt opnieuw verhogingen aan per juli 2026. De impliciete marge groeit daarmee jaar op jaar, onzichtbaar.
Drie vragen die je kunt stellen
1. In welke eenheid wordt mijn gebruik gemeten — en hoe verhoudt die zich tot tokens? Als je leverancier dat niet kan beantwoorden, weet je genoeg over de transparantie van de relatie.
2. Hoeveel van mijn seats worden werkelijk actief gebruikt — en wat is het gemiddelde gebruik per actieve seat? Zonder dit getal betaal je mogelijk voor een grote groep medewerkers die de tool nauwelijks opent.
3. Daalt de onderliggende tokenprijs — en vertaalt dat zich naar mijn abonnementsprijs? Als API-kosten halveren maar jouw abonnement stijgt, groeit de impliciete marge. Dat is een legitieme keuze van de aanbieder. Maar jij mag er naar vragen.
De verbinding met tokenefficiëntie
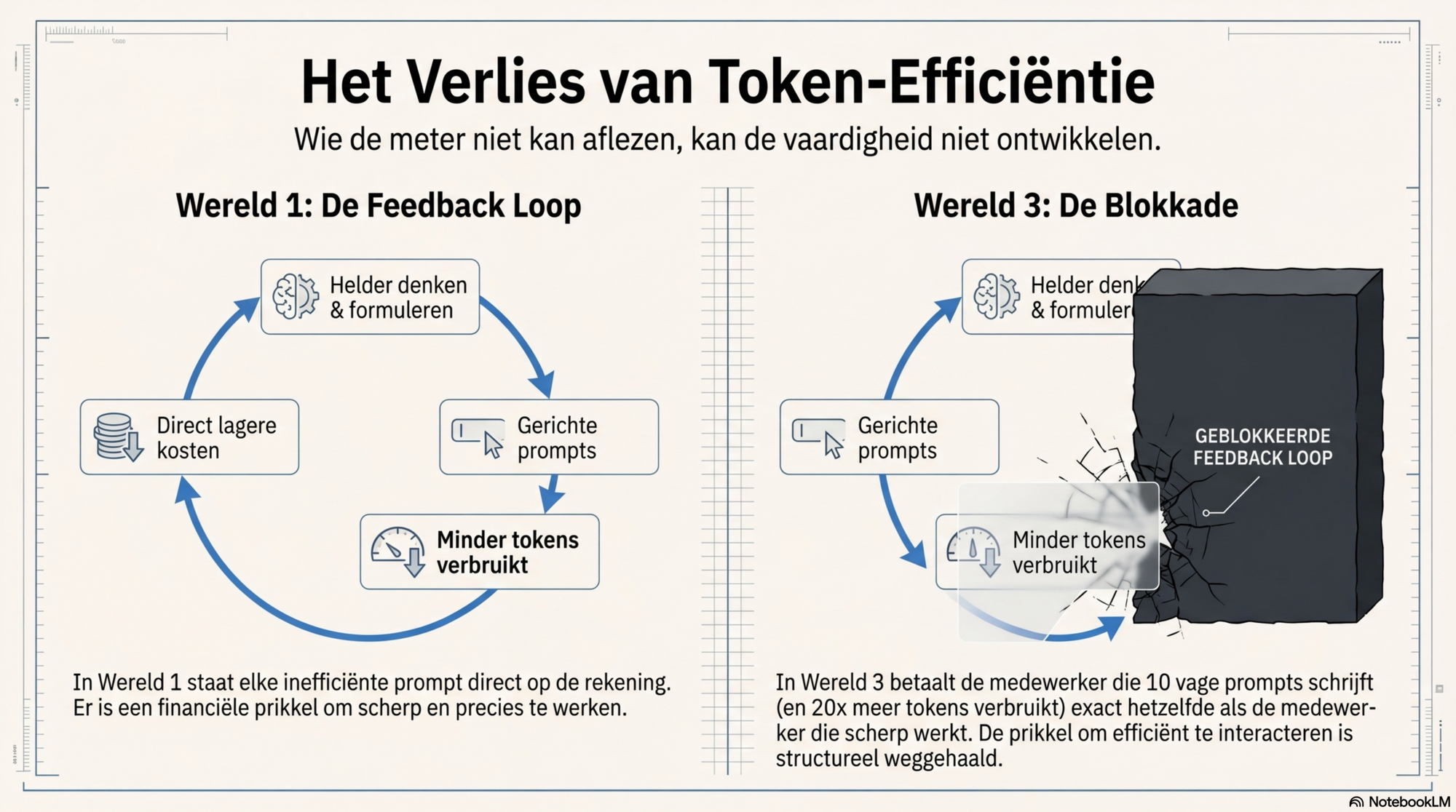
In de derde blog beschreef ik tokenefficiëntie als een cognitieve vaardigheid: wie helder denkt, stelt gerichte vragen, verbruikt minder tokens, bereikt betere uitkomsten. Die vaardigheid is alleen te ontwikkelen als de meter leesbaar is.
In wereld 1 is de prikkel direct. In wereld 3 is die prikkel er structureel niet. De organisatie die wil investeren in de tokenefficiëntie van haar medewerkers — in de kwaliteit van hun denken en formuleren — heeft in wereld 3 geen meter om dat te meten. Ze kan niet vergelijken, niet sturen, niet bijsturen.
Dat is het eigenlijke argument voor transparantie. Niet als ethische eis, maar als praktische noodzaak. Wie de meter niet kan aflezen, kan de vaardigheid niet ontwikkelen.
De meter loopt. De vraag is of je hem kunt lezen.

Over de tokenreeks
Deze blog maakt deel uit van een bredere reeks over de tokeneconomie — het businessmodel achter AI en wat het betekent voor hoe we werken, denken en organisaties inrichten.
De tokenreeks:
→ Tokens op de meter — De meter tikt al. Tokenefficiëntie is een strategische vaardigheid, geen technisch detail. En het businessmodel van AI rust op een verslavingsfase die we collectief doormaken.
→ De tokeneconomie — Alibaba bouwt een Token Hub. De token is niet alleen een rekeneenheid — het is een valuta, een productie-eenheid en een commercieel model tegelijk. De economische infrastructuur van AI benoemt zichzelf.
→ De token als meetlat — Vier lenzen waarop organisaties tokenverbruik kunnen meten: als kosten, als productiviteit, als statussignaal en als waarde-indicator. Tokenefficiëntie als cognitieve vaardigheid.
→ SAP wordt tokenreseller — Hoe de grootste ERP-leverancier ter wereld zijn verdienmodel moest omgooien omdat AI-agents de noodzaak voor menselijke seats ondergraaft. Het Vermogen-Systeem-Product-model als conclusie.
De bredere AI-reeks:
→ De Mens als Orkestrator — Zeven menselijke kwaliteiten die AI niet overneemt, en een achtste die nu pas zichtbaar wordt.
→ De Centaur — Mens en AI als één geheel: het verweving-spectrum en wat het vraagt van hoe je werkt en denkt.
→ Het Schaakbord — Exponentiële groei, waar we nu staan, en waarom lineaire stappen de kloof niet dichten.
Noot over de berekeningen en bronnen
Harde Anthropic-documentatie: 5-uurs rolling window, weeklimiet voor alle modellen en aparte Opus-limiet, reset na 7 dagen, minder dan 5% van gebruikers raakt weeklimiet bij normaal gebruik, 5× meer gebruik dan gratis bij Pro. Dit staat in het officiële Anthropic Help Center.
Community-instrumentatie, niet officieel bevestigd door Anthropic: ~44.000 tokens per 5-uurs venster voor Pro, ~88.000 voor Max 5×, ~220.000 voor Max 20×. Consistent gerapporteerd via open-source tracking-tools (ccusage, Claude Code Usage Monitor) die lokale sessiebestanden analyseren. De weeklimiet in "actieve uren" (40–80 voor Pro) is gerapporteerd door één derde partij (Usagebar) — dit getal is indicatief, niet hard.
Gebruiksscenario's: gebaseerd op OpenAI/Harvard-onderzoek (september 2025, 1,5M geanonimiseerde conversaties) voor gemiddeld gebruik, aangevuld met eigen redenering voor zware en max-gebruikers. Alle tokenberekeningen zijn schattingen — werkelijk gebruik varieert sterk per persoon, gesprekstype en modelkeuze.
Adoptiecijfers M365 Copilot: Recon Analytics (januari 2026), Microsoft FY26 Q1-cijfers.
GitHub Copilot harde data: planprijzen, premium request-aantallen, multiplier-tabel, overschrijdingsprijs $0,04 en de drie inbegrepen modellen (GPT-4.1, GPT-4o, GPT-5 mini) komen uit officiële GitHub Docs (docs.github.com/copilot, maart 2026). De 10% auto-selectiekorting in VS Code staat eveneens in de officiële documentatie. Het gemiddelde van ~2.500 tokens per chat-interactie is een community-schatting — niet officieel gepubliceerd door GitHub.
Co-creatie: Dit stuk is gemaakt samen met Claude (Anthropic), versie Sonnet 4.6. De gedachten, posities en interpretaties zijn van mij. Claude heeft geholpen bij het structureren, het aanscherpen van argumenten en het schrijven van de tekst. Ik vind het bij dit onderwerp passen om dat expliciet te benoemen. NotebookLM gebruikt voor de visuals.