De prijs van intelligentie

De meetlat die je niet op de prijspagina vindt
Dit is de negende blog in mijn reeks over de tokeneconomie. Eerdere delen onderaan deze pagina met korte samenvatting.
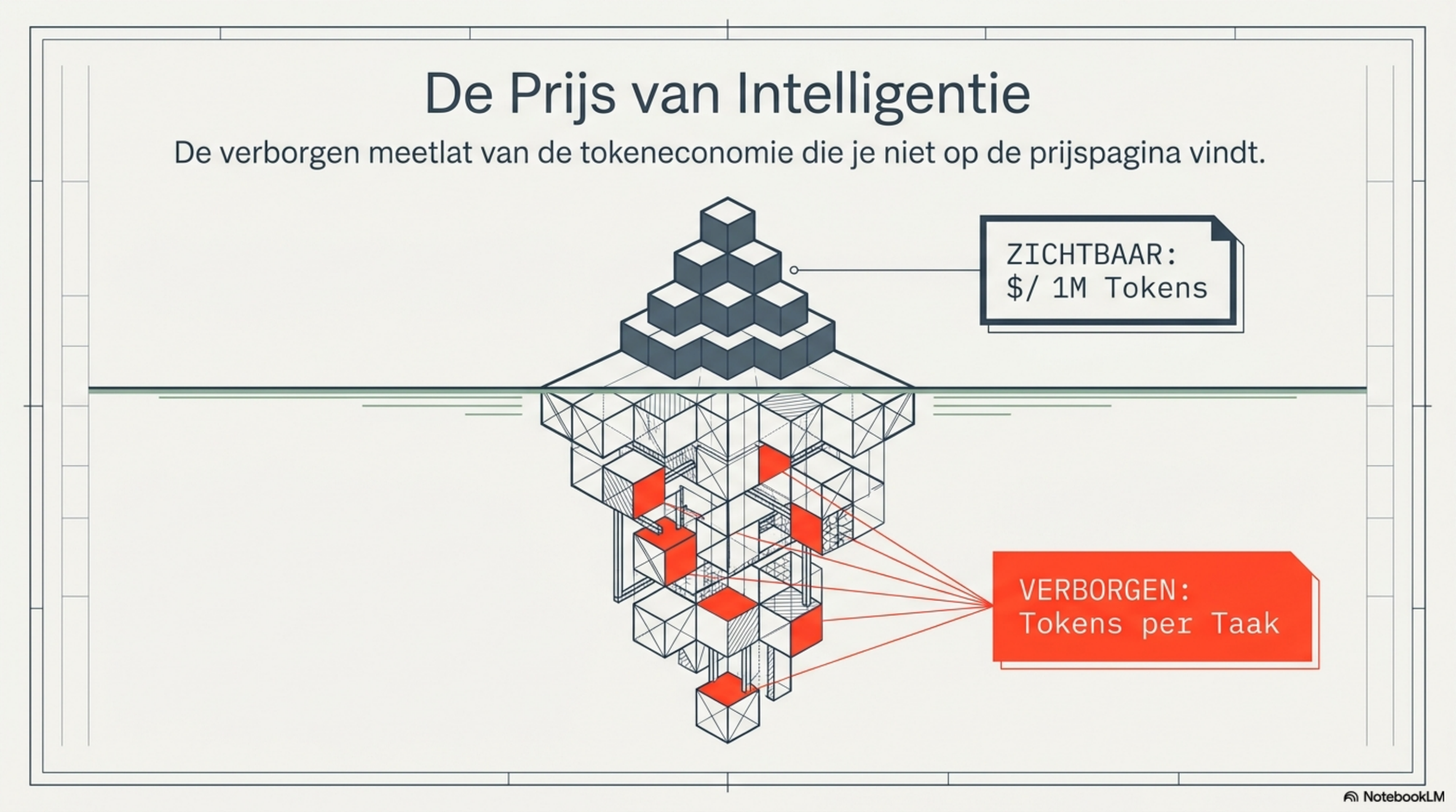
De prijs per miljoen tokens staat op de prijspagina. Zichtbaar, vergelijkbaar, neergeschreven in zwart op wit.
Wat je niet ziet, is hoeveel tokens een model nodig heeft om tot het goede antwoord te komen. En dat getal varieert — van model tot model, van taak tot taak, van effort-niveau tot effort-niveau — met een factor twee, vijf, of twintig.
De werkelijke rekening is het product van twee dingen: de prijs per token, en het aantal tokens per taak. De eerste staat op de prijspagina. De tweede bepaalt het model — niet jij.

Wat je zelf in de hand hebt — en wat niet
In de vorige blogs behandelde ik twee van de drie lagen die de tokenrekening bepalen los van de stickerprice.
De eerste is de prompt: hoe je je vraag formuleert, hoeveel context je meegeeft, hoe precies je het gewenste antwoord afbakent. Dat is de menselijke kant. Een scherpe prompt kost minder tokens en levert betere output. Dat is beïnvloedbaar — en het is een vaardigheid.
De tweede is de tokenizer: hoe het model jouw tekst opknipt in rekeneenheden. De tokenizer bepaalt welke tekenreeksen als één token worden herkend en welke in stukken worden gehakt. Dat hangt af van twee factoren.
De eerste is de architectuur: hoe groot is het vocabulaire van de tokenizer, en op welke data is hij getraind? Een groter vocabulaire betekent meer woorden die als één geheel worden herkend — efficiënter, compacter, goedkoper. OpenAI verdubbelde hun vocabulaire van 100.000 naar 200.000 items en werd daarmee 15–20% efficiënter. Anthropic veranderde de tokenizer bij Opus 4.7 — en die nieuwe tokenizer knipt dezelfde tekst op in 10 tot 35% méér tokens dan de vorige versie. Meer tokens voor dezelfde input, bij gelijkblijvende tokenprijs: een verborgen kostenstijging.
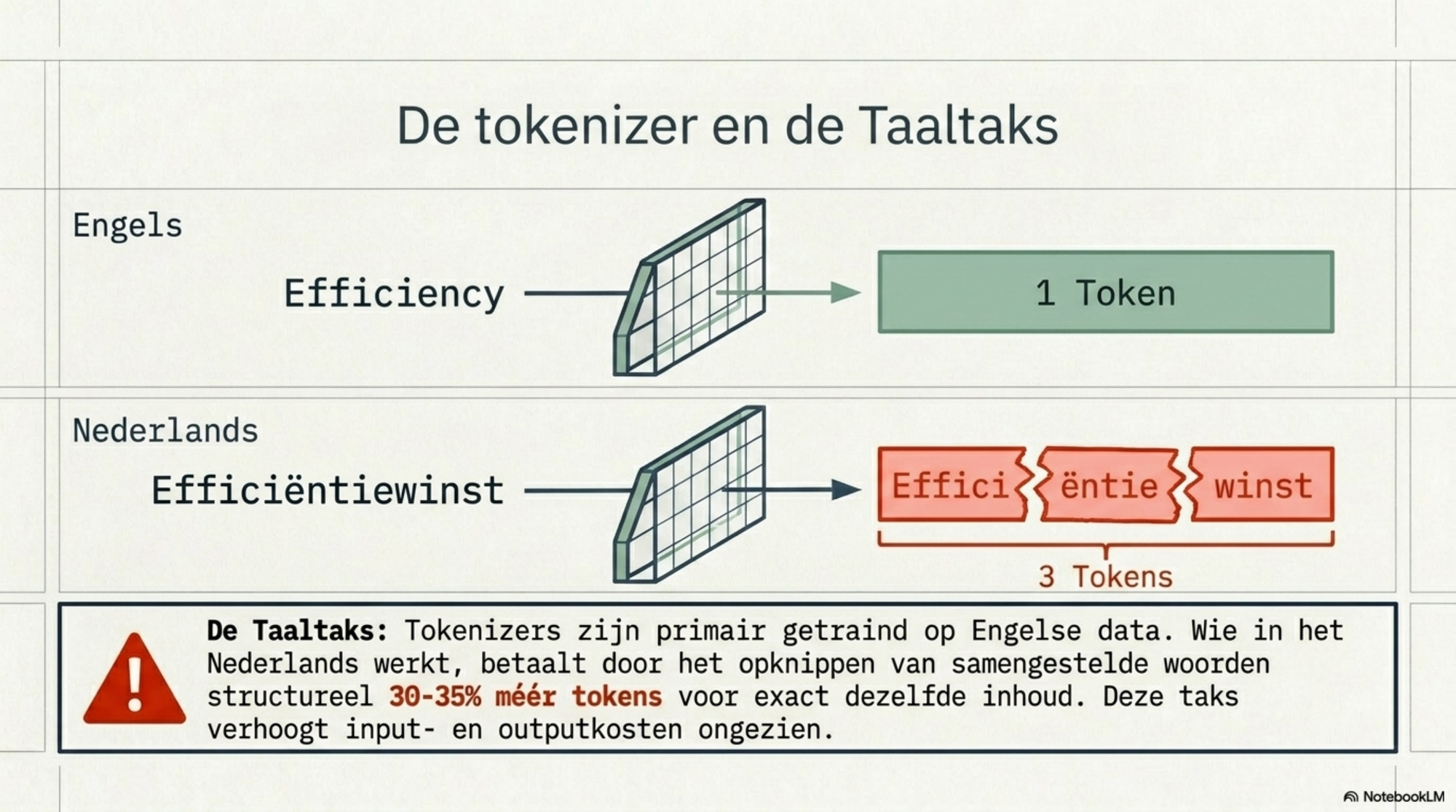
De tweede factor is de taal. Tokenizers zijn getraind op overwegend Engelstalige data. Engels is daardoor de meest efficiënte taal — het referentiepunt. Wie in het Nederlands werkt, betaalt structureel 30–35% meer tokens voor dezelfde inhoud, omdat samengestelde woorden en minder frequente tekenreeksen vaker in stukken worden gehakt. Dat is de taaltaks, beschreven in de vorige blog. Hij is geen beleid en geen opzet — hij is een bijproduct van de data waarop de tokenizer is gebouwd.
De tokenizer heb je niet in de hand. Je kunt geen vocabulaire kiezen, geen knipmethode instellen. Je kunt wel kiezen welk lab en welk model je gebruikt — en daarmee indirect welke tokenizer je rekening bepaalt.
Nu is er een derde laag. En die is fundamenteel anders dan de eerste twee.
Intelligentie-efficiëntie is de verhouding tussen de kwaliteit van het antwoord en het aantal tokens dat het model nodig heeft om dat antwoord te produceren. Een model dat een complexe codetaak oplost in 3.000 output-tokens is efficiënter dan een model dat voor dezelfde taak 8.000 tokens nodig heeft — ook als het per token goedkoper is.

Dit heb je niet in de hand. Maar je hebt wel een keuze: welk model — welk lab — je inzet voor welke taak. Dat is de strategische ruimte die deze blog opent.
De tokens die je nooit ziet
Intelligentie-efficiëntie heeft een mechanisme dat eraan ten grondslag ligt: de reasoning token.
Moderne frontier-modellen — GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro — zijn geen systemen die een vraag ontvangen en direct een antwoord formuleren. Ze denken eerst. Intern. En dat denkproces bestaat zelf ook uit tokens.
Dat interne denken speelt zich af in twee herkenbare fasen, ook al worden ze technisch niet apart gefactureerd.
De eerste fase is promptverbetering: het model ontvangt je prompt en herschrijft of verrijkt die intern. Wat wordt er precies gevraagd? Wat ontbreekt er aan context? Welke aanpak is het meest geschikt? Dit is een bewuste ontwerpkeuze van de labs — ze zien dat de meeste gebruikers hun prompt niet zelf optimaliseren, en compenseren dat intern. Het model doet voor jou wat een goede promptschrijver ook zou doen: de vraag scherper maken voordat het antwoord wordt gezocht.
De tweede fase is redeneren naar de output: het model werkt stap voor stap toe naar het antwoord. Het genereert tussenresultaten, checkt zijn eigen redenering, corrigeert waar nodig, en bouwt toe naar de conclusie. Dit is de eigenlijke chain-of-thought — de interne monoloog die je als gebruiker nooit leest, maar die het uiteindelijke antwoord draagt.
Beide fasen genereren reasoning tokens. En beide fasen worden gefactureerd als output-tokens — het duurste tarief dat bestaat — ook al verschijnen ze niet in je antwoord.

Een API-response ziet er dan zo uit:
input_tokens: 500
output_tokens: 2.400 ← totaal gefactureerd
waarvan:
reasoning_tokens: 1.800 ← onzichtbaar in je antwoord
visible_tokens: 600 ← wat je daadwerkelijk zietJe betaalt voor 2.400 tokens. Je leest er 600. De overige 1.800 zijn het denkproces — verdeeld over beide fasen, verborgen voor de gebruiker, maar volledig meegenomen in de rekening.
Bij hoge reasoning effort — het hoogste denkniveau van een model — kan die verhouding extremer zijn. Een zichtbaar antwoord van 200 tokens kan op 3.000 of meer reasoning tokens hebben gedraaid. Je betaalt effectief vijftien keer meer dan wat je te lezen krijgt.
Onderzoek bevestigt dit. Een enkele evaluatierun met OpenAI's o3-model op de ARC-AGI benchmark verbruikte 111 miljoen tokens en kostte meer dan 66.000 dollar — waarvan meer dan 60 procent bestond uit verborgen reasoning tokens. De factuur was twee keer zo hoog als de zichtbare output deed vermoeden.
Er zit ook een directe implicatie in voor wie bewust met kosten omgaat: een scherpe, goed geformuleerde prompt verkleint de behoefte aan fase 1. Wie zijn prompt zelf optimaliseert, laat het model minder intern herschrijven — en betaalt minder reasoning tokens voor iets wat hij ook zelf had kunnen doen.
Dit is geen randgeval. Het is de normale werking van reasoning-modellen. Je krijgt de factuur. Niet de uitsplitsing.
GPT-5.5: de prijsverdubbeling die geen verdubbeling is
Op 23 april 2026 lanceerde OpenAI GPT-5.5. De prijs verdubbelde: van 2,50 dollar naar 5 dollar per miljoen input-tokens, van 15 naar 30 dollar per miljoen output-tokens.
De eerste reactie in de markt was voorspelbaar: een verdubbeling van de tokenprijs. Maar OpenAI's argument was subtieler — en het is de moeite waard om dat argument serieus te nemen, want het illustreert precies waarom prijs per token het verkeerde meetpunt is.
GPT-5.5 gebruikt voor dezelfde taak circa 40 procent minder output-tokens dan zijn voorganger GPT-5.4. Het model is compacter in zijn redeneren: het bereikt een gelijkwaardig of beter resultaat in minder stappen, met minder retry-loops, en met een kortere interne redeneerchain.
De rekensom ziet er dan zo uit:
| GPT-5.4 | GPT-5.5 | Verschil | |
|---|---|---|---|
| Prijs per M output-tokens | $15,00 | $30,00 | +100% |
| Output-tokens per taak (index) | 100.000 | 60.000 | −40% |
| Kosten per taak | $1,50 | $1,80 | +20% |
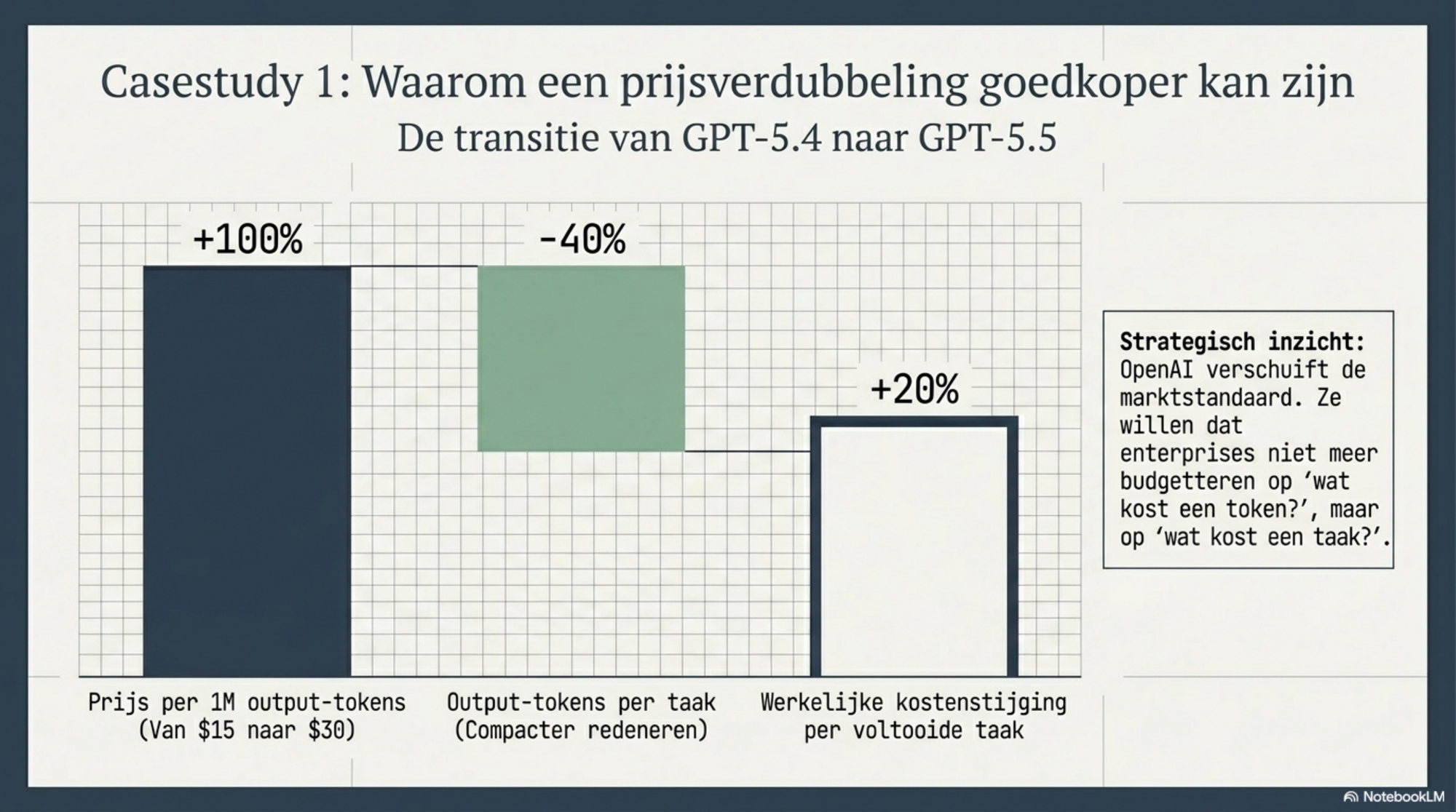
De tokenprijs verdubbelde. De kosten per taak stegen met 20 procent. Het verschil zit in wat het model doet met de tokens die het krijgt.
OpenAI's eigen omschrijving is veelzeggend: GPT-5.5 bereikt hogere kwaliteit met minder tokens en minder herhalingen. Dat is intelligentie-efficiëntie in één zin.
Er is één kanttekening die eerlijkheid vereist: het 40-procent-cijfer is door OpenAI zelf gepubliceerd en geldt specifiek voor Codex-taken. Onafhankelijke verificatie op de volledige taakbreedte is beperkt. Artificial Analysis bevestigt de richting — een nettokostenstijging van circa 20 procent op hun Intelligence Index — maar de exacte efficiëntiewinst varieert per workload. Wie GPT-5.5 inzet voor taken die weinig redeneren vereisen, betaalt de prijsverdubbeling zonder de efficiëntiebonus.
De bredere implicatie is misschien nog interessanter dan het getal zelf. OpenAI gokt dat de rekeneenheid verschuift. Niet wat een token kost, maar wat een taak kost. Als enterprise-klanten gaan budgetteren per voltooide taak — wat het logische eindpunt is van agentisch gebruik — is GPT-5.5 goedkoper dan zijn voorganger. Als ze dat niet doen, is de prijsstijging moeilijk te verdedigen.
Opus 4.7: hetzelfde verhaal, meer lagen
Op 16 april 2026 lanceerde Anthropic Claude Opus 4.7. Dezelfde prijs als Opus 4.6: 5 dollar input, 25 dollar output per miljoen tokens. Meer intelligentie voor hetzelfde geld — op het eerste gezicht een eenvoudigere propositie dan GPT-5.5.
Maar de werkelijkheid is genuanceerder.
Opus 4.7 wint op 12 van 14 gerapporteerde benchmarks ten opzichte van 4.6. De grootste sprongen zitten in agentisch coderen en visueel redeneren. Wat de intelligentie-efficiëntie betreft: een low-effort Opus 4.7 levert de kwaliteit van een medium-effort Opus 4.6. Het model doet meer met minder effort.
Praktijkdata van Box — een enterprise platform dat Opus 4.7 uitvoerig testte op agentische workflows — is illustratief. Opus 4.7 voltooide dezelfde taken met gemiddeld 7,1 model-aanroepen versus 16,3 voor Opus 4.6. Meer dan een halvering. Tool calls daalden van 18,8 naar 9,4. Taakduur daalde van 242 naar 183 seconden. Het model denkt besluitvaardiger: waar 4.6 iteratief informatie verifieerde over meerdere stappen, trekt 4.7 dezelfde conclusie vaak in één rekenronde.
Dat is intelligentie-efficiëntie in de meest directe zin: minder stappen, minder tokens, gelijkwaardige of betere output.
Maar er zijn twee complicaties die het verhaal minder eenvoudig maken dan de prijspagina suggereert.
De nieuwe tokenizer. Zoals hierboven beschreven, knipt de nieuwe tokenizer van Opus 4.7 dezelfde input op in 10 tot 35 procent meer tokens dan de vorige versie. Voor Nederlands, technische content en gestructureerde data (JSON, XML) zit je eerder aan het hogere einde van die bandbreedte. De taal die je schrijft en de structuur van je content bepalen mee hoeveel die extra knipfrequentie je kost. De efficiëntiewinst op taakniveau wordt hier deels uitgevlakt door een hogere tokenprijs per woord.
Het hogere standaard effort-niveau. Opus 4.7 staat standaard op xhigh effort — het hoogste denkniveau — voor alle plannen en providers. Opus 4.6 stond standaard op high of medium. Dat betekent dat Opus 4.7 out-of-the-box meer reasoning tokens verbruikt dan 4.6 deed. Wie op kosten let, kan dit terugdraaien door het effort-niveau expliciet lager in te stellen — maar de standaard gedraagt zich anders dan de voorganger.

Het nettoresultaat: Opus 4.7 is intelligenter én efficiënter op taakniveau, maar de nieuwe tokenizer en het hogere standaard effort-niveau eten een deel van die efficiëntiewinst op. De werkelijke kostenverschuiving hangt af van de specifieke workload.
Intelligence per dollar: het echte meetpunt
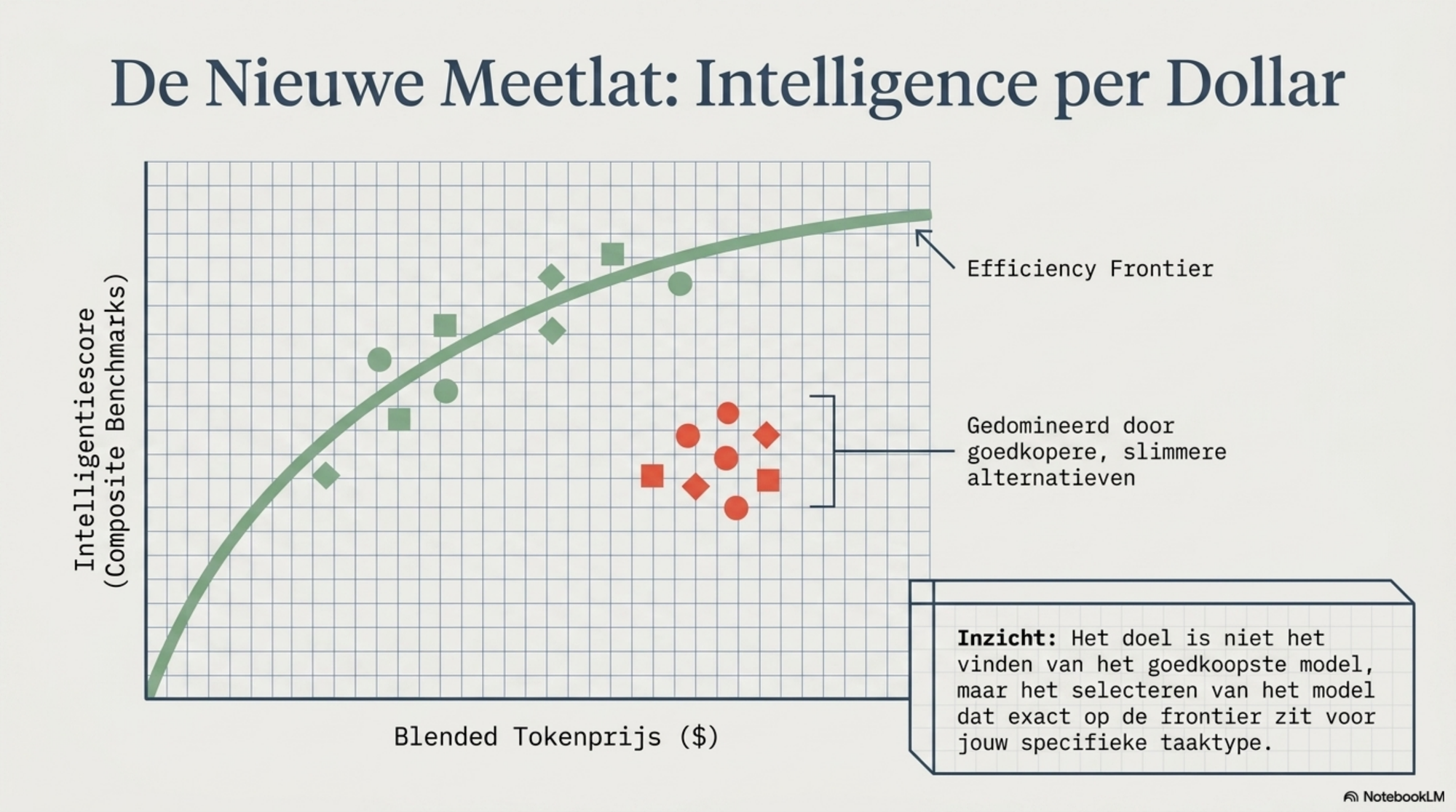
De term die Artificial Analysis hanteert voor dit concept is intelligence per dollar: de verhouding tussen de composite benchmark-score van een model en de blended tokenprijs per miljoen tokens.
Het is een fundamenteel ander meetpunt dan prijs per token. Het vraagt niet: wat kost een token? Het vraagt: hoeveel intelligentie krijg ik per dollar die ik uitgeef?
De scatter plot die Artificial Analysis publiceert — intelligentiescore op de y-as, prijs op de x-as — laat zien welke modellen op de efficiency frontier zitten: de maximale intelligentie voor een gegeven prijs. Modellen die niet op die frontier liggen, worden gedomineerd door een goedkoper model met een gelijkwaardige of hogere score.
Het beeld in april 2026:
| Categorie | Winnaar | Reden |
|---|---|---|
| Absolute intelligentie | GPT-5.5 | Score 60 op de Intelligence Index |
| Beste prijs/kwaliteit frontier | Gemini 3.1 Pro | Score vergelijkbaar met GPT-5.4, $2/$12 per M tokens |
| Hoogste score/dollar ratio breed | Gemini Flash-Lite | 127,5 benchmarkpunten per dollar |
| Coderen dagelijks gebruik | Claude Sonnet 4.6 | 79,6% SWE-bench, $3/$15, 40% goedkoper dan Opus |
| Redeneren en wetenschappen | Gemini 3.1 Pro | 94,3% GPQA Diamond |

De conclusie die eruit volgt is niet "kies het goedkoopste model." De conclusie is: kies het model dat op de efficiency frontier zit voor jouw specifieke taaktype.
Google koos een andere strategie dan OpenAI. Gemini 3.1 Pro levert benchmark-scores vergelijkbaar met GPT-5.4 voor significant minder geld — Google droeg de efficiëntiewinst over aan gebruikers via lagere prijzen. OpenAI koos voor hogere kwaliteit bij hogere prijs, met token-efficiëntie als compensatiemechanisme. Beide zijn rationele strategieën. Ze weerspiegelen verschillende keuzes over hoe je waarde overdraagt aan klanten.
Anthropic koos een derde weg: Opus 4.7 op dezelfde prijs als 4.6, met hogere kwaliteit als propositie. Maar de nieuwe tokenizer vertroebelt dat beeld — wie meer tokens per woord betaalt bij gelijkblijvend tarief, betaalt per saldo toch meer. De efficiëntiewinst op taakniveau en de tokenizer-kostenstijging op inputniveau werken in tegengestelde richting. Wat het netto oplevert, hangt af van de specifieke workload.

Wat dit vraagt van de gebruiker
De drie lagen van de werkelijke tokenprijs — prompt, tokenizer, intelligentie-efficiëntie — stellen samen een ongemakkelijke eis. Je kunt je prompt optimaliseren. Je kunt je taalstrategie bewust kiezen. Maar de intelligentie-efficiëntie van een model is geen parameter die je instelt. Het is een eigenschap van het model dat je kiest.
Dat betekent dat modelkeuze een strategische beslissing is, geen technische voorkeur.
Wie voor elke taak hetzelfde frontier-model inzet — het duurste, het krachtigste — betaalt reasoning tokens voor vraagstukken die dat niveau niet vereisen. Wie routeert op taakniveau — eenvoudige taken naar goedkope, efficiënte modellen; complexe taken naar de frontier — bouwt een kostenprofiel dat dichter bij de werkelijke behoefte ligt.

De praktische stelregel: meet niet wat een token kost. Meet wat een taak kost. En meet daarna welk model dezelfde taak voor minder tokens — en dus minder geld — tot een goed einde brengt.
Dat is intelligence per dollar. En het is het meetpunt dat ertoe doet.
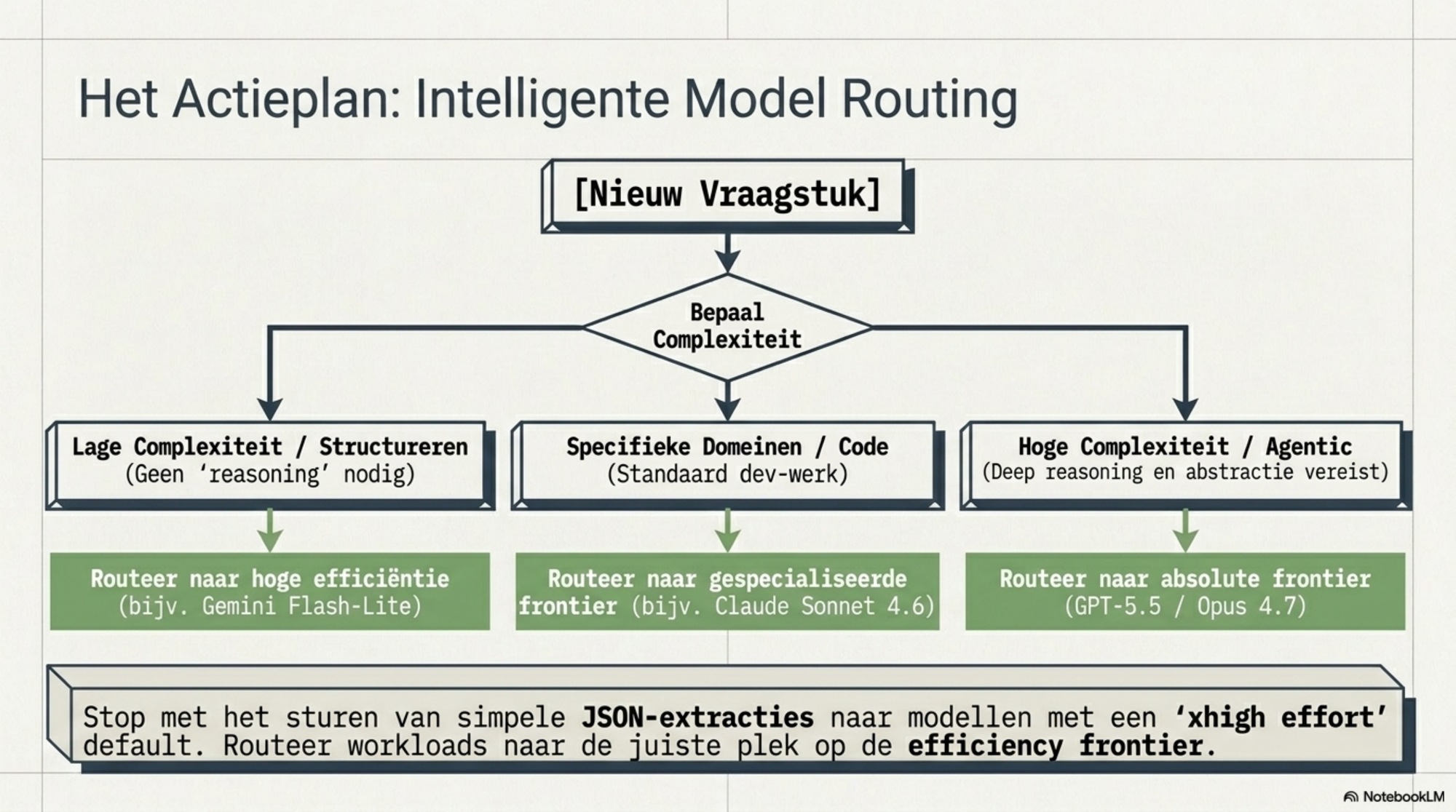
Maar die vraag — welk model voor welke taak — werd op 24 april 2026 ingrijpend complexer. En tegelijkertijd goedkoper.
Op diezelfde dag dat GPT-5.5 beschikbaar werd voor API-gebruik, lanceerde het Chinese lab DeepSeek zijn V4-modellen. V4-Pro is een open-source model van 1,6 biljoen parameters dat op SWE-bench Verified 80,6 procent scoort: binnen 0,2 procentpunt van Claude Opus 4.6, en vergelijkbaar met GPT-5.4 op coding-benchmarks. Op wiskundige competities en STEM-reasoning benadert het de absolute frontier.
De prijs: 1,74 dollar per miljoen input-tokens en 3,48 dollar per miljoen output-tokens. Ter vergelijking: Claude Opus 4.7 kost 5 dollar input en 25 dollar output. GPT-5.5 kost 5 dollar input en 30 dollar output. Voor nagenoeg dezelfde codeer-prestaties betaal je bij DeepSeek V4-Pro zeven keer minder per output-token.
Het model is open-source, staat op Hugging Face, en is getraind op Chinese hardware — buiten het Nvidia-ecosysteem. Dat is niet alleen een prijssignaal. Het is een geopolitiek signaal.

De volgende blog gaat hierover: wat DeepSeek zegt over de aanname dat frontier-intelligentie per definitie duur is, wat het betekent voor de westerse labs, en wat het vraagt van organisaties die nu hun AI-strategie bepalen.
Deze blog maakt deel uit van een bredere reeks over AI als systeemverschuiving — van de economie van tokens tot de versnelling van de technologie en wat dat betekent voor mensen en organisaties. De technische kant van AI in de praktijk beschrijft Edwin van Dillen. De bredere gedachten over organisatie, intentie en uitvoering zijn uitgewerkt op augmentedorganisation.nl, intentdriven.nl en augmentedengineering.nl.
De tokenreeks — eerder verschenen
Tokens op de meter — 23 maart 2026 Sam Altman beschreef het businessmodel openlijk: intelligentie wordt een nutsvoorziening, afgerekend per token. Deze blog introduceert de token als rekeneenheid, beschrijft de verslavingsfase waarin AI-bedrijven nu zitten — goedkoop om afhankelijkheid te bouwen — en legt uit waarom de uitgestelde rekening reëel is. Tokenefficiëntie is al nu een strategische vaardigheid.
De tokeneconomie — 24 maart 2026 Alibaba richtte de Alibaba Token Hub op: een formele business unit met de missie "tokens creëren, distribueren en toepassen." Drie lagen — foundational modellen, API-distributie, agentic platforms — vormen een verticaal geïntegreerd ecosysteem. Opmerkelijk: de tokeneconomie benoemt zichzelf, terwijl eerdere technologiegolven pas achteraf werden benoemd.
De token als meetlat — 27 maart 2026 Naar aanleiding van een WSJ-artikel: vier lenzen waarop bedrijven tokenverbruik meten — als factuur (Zapier), als prestatiemeting (Meta, Shopify), als statussymbool (tokenmaxxing bij OpenAI en Anthropic intern), en als waarde-signaal (Vercel, Kumo AI). Centrale conclusie: tokenefficiëntie is een proxy voor denkkwaliteit, niet voor technische vaardigheid.
SAP wordt tokenreseller — 28 maart 2026 SAP-CEO Christian Klein kondigde het einde van het abonnementsmodel aan. Als AI-agents de taken van tien medewerkers overnemen, heb je tien keer zo weinig seats nodig. SAP's "AI Units" zijn onder de motorkap tokens ingekocht bij Anthropic, OpenAI en anderen — SAP is in essentie een tokenreseller geworden. Systemen commoditiseren; menselijk vermogen blijft de onvervangbare differentiator.
De meter die lastig is te lezen — 7 april 2026 Drie betalingswerelden: de transparante API-wereld, de verpakte abonnementswereld (Claude Pro, ChatGPT Plus), en de geabstraheerde enterprise-wereld (M365 Copilot, GitHub Copilot). Kernconclusie: abonnementen zijn voor de gemiddelde gebruiker 3× tot 14× duurder per token dan directe API-toegang. In de enterprise wrapper-wereld ontbreekt de prikkel tot tokenefficiëntie structureel.
Tokenafhankelijkheid — 30 april 2026 Via de Black Mirror-aflevering Common People en het concept enshittification: hoe Anthropic in vier stappen laat zien hoe de uitgestelde rekening stap voor stap wordt gepresenteerd. Agentic AI verdiept de afhankelijkheid structureel.
De tokenizer als verborgen variabele — 01 mei 2026 Een token bij OpenAI is niet hetzelfde als een token bij Anthropic. En een token bij Anthropic 4.6 is niet hetzelfde als bij 4.7. Vergelijking van alle grote labs op tokenizer-architectuur en vocabulaireomvang. De stickerprice is geen eerlijke vergelijkingsmaatstaf.
De taaltaks — 03 mei 2026 Er is een belasting die je nooit hebt gekozen en die nergens op je factuur staat: de taaltaks. Nederlandse tekst kost structureel 30–35% meer tokens dan equivalente Engelse tekst, omdat de tokenizers zijn getraind op overwegend Engelstalige data. De meter tikt voor sommigen harder dan voor anderen.
Co-creatie: Dit stuk is gemaakt samen met Claude (Anthropic) en NotebookLM (Google). De gedachten, posities en interpretaties zijn van mij.