Intelligentie op de meter

Een inleiding op de tokeneconomie — 8 blogs, deel 9 verschijnt morgen

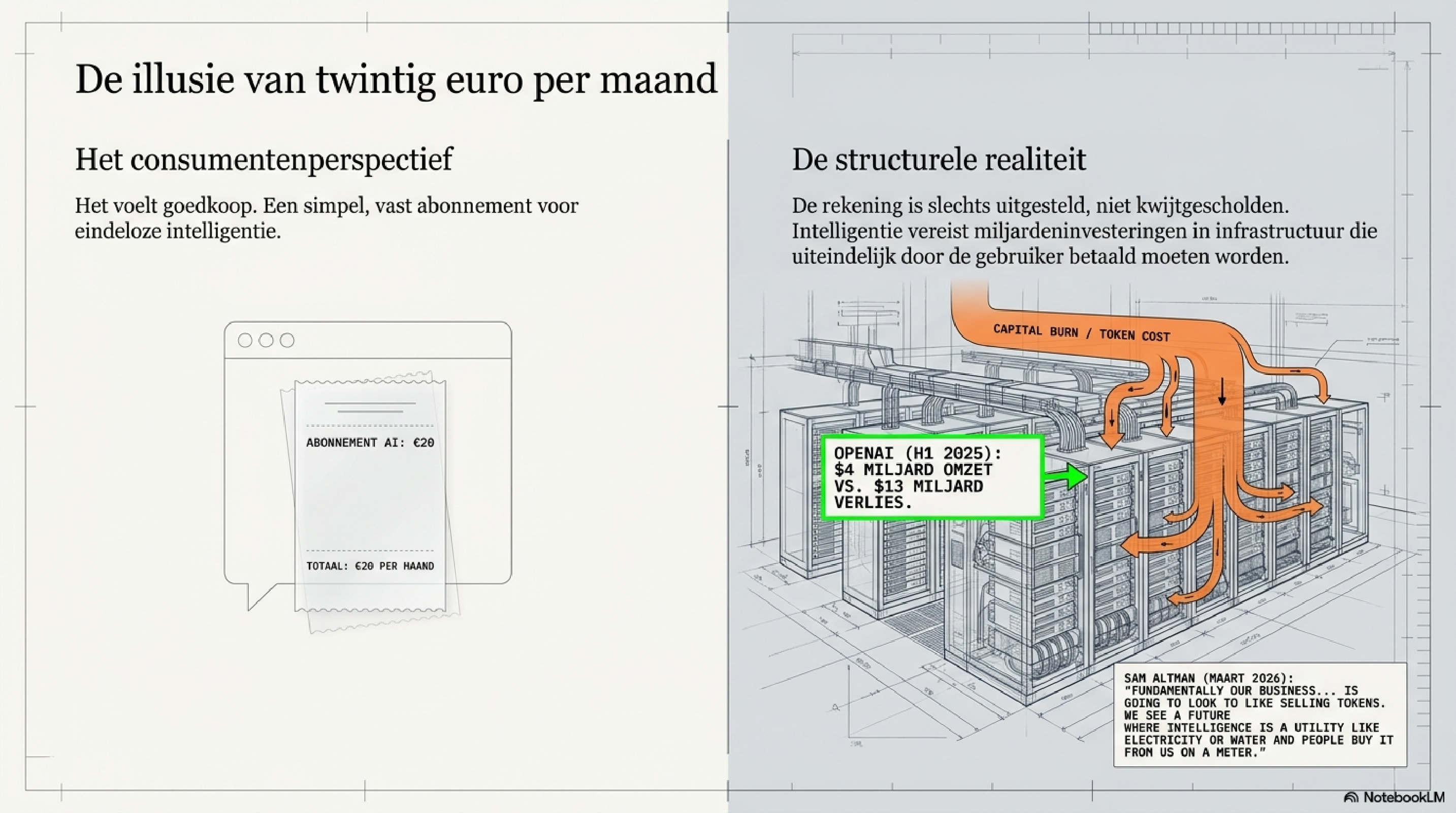
Je betaalt twintig euro per maand voor ChatGPT of Claude. Of je betaalt helemaal niets, omdat je de gratis versie gebruikt. Het voelt goedkoop. Het voelt bijna te goed.
Dat gevoel klopt niet.
Dit is geen waarschuwing voor een verborgen abonnementsval of een aanval op AI-bedrijven. Het is iets subtielers — en uiteindelijk nuttiger. Het is een uitnodiging om de economische laag te begrijpen die onder elk AI-product ligt, die door de grootste techbedrijven ter wereld serieus wordt genomen, en die voor de meeste gebruikers volledig onzichtbaar blijft.
Die laag heet de tokeneconomie. En er zijn inmiddels negen blogs over geschreven die samen één verhaal vertellen — met als rode draad één begrip dat in elk deel terugkeert: tokenefficiëntie.
De munteenheid die je nooit ziet
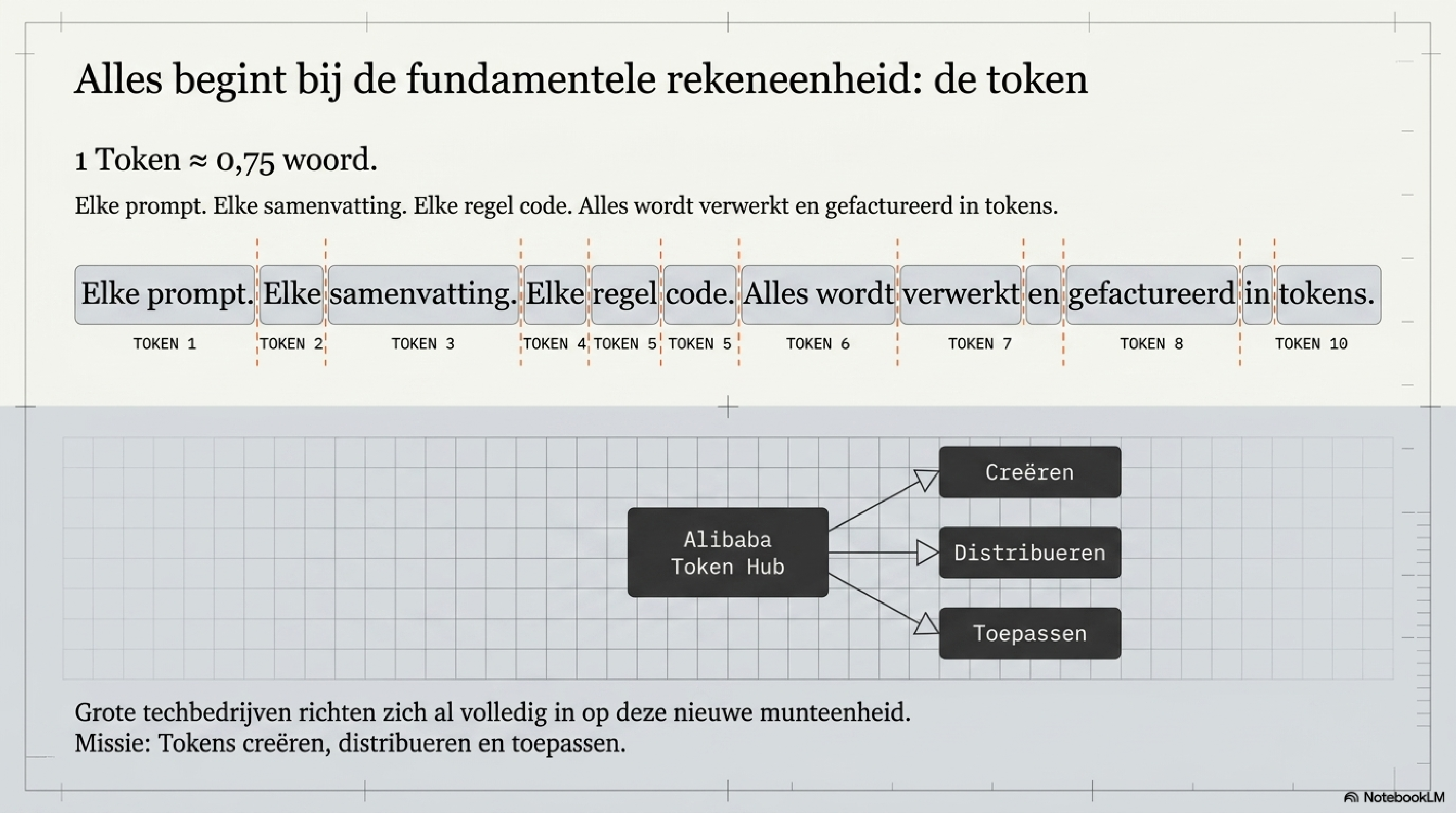
Alles begint bij de token.
Een token is de fundamentele rekeneenheid waarmee een taalmodel werkt — ruwweg driekwart woord. Elke vraag die je stelt, elk antwoord dat je terugkrijgt, elke samenvatting, elke gegenereerde code: het wordt verwerkt en gefactureerd in tokens. Dat is de transactie die plaatsvindt, of je er weet van hebt of niet.
Sam Altman, CEO van OpenAI, zei het openlijk op een investeerdersconferentie in maart 2026: "Fundamentally our business and the business of every other model provider is going to look like selling tokens." En: "We see a future where intelligence is a utility like electricity or water and people buy it from us on a meter."
Dat is geen vage toekomstvisie. Dat is de beschrijving van een businessmodel dat nu al bestaat — maar waarvan de werkelijke kosten op dit moment nog niet volledig bij gebruikers liggen. De rekening is uitgesteld, niet kwijtgescholden. Achter die ogenschijnlijk goedkope twintig euro per maand gaan miljarden aan investeringen schuil die op enig moment moeten worden terugverdiend — via de tokens die jij verbruikt. OpenAI draaide in de eerste helft van 2025 ruim vier miljard dollar omzet en dertien miljard dollar verlies. De investeerders in GPU-fabrieken en datacenters gaan die factuur niet zelf voldoen.
Alibaba maakte de strategie nog explicieter door een formele business unit op te richten: de Alibaba Token Hub, met als officiële missie "tokens creëren, distribueren en toepassen." Een technologiegolf die zichzelf bij naam noemt terwijl hij nog volop bezig is — dat is zeldzaam. Het vraagt om een antwoord dat even helder is.
Tokenefficiëntie: de vaardigheid die er al nu toe doet
Midden in dat verhaal over kosten en afhankelijkheid zit een positieve kern: wie de tokeneconomie begrijpt, kan er ook beter mee omgaan. Die vaardigheid heet tokenefficiëntie — en hij is de rode draad door de hele reeks.
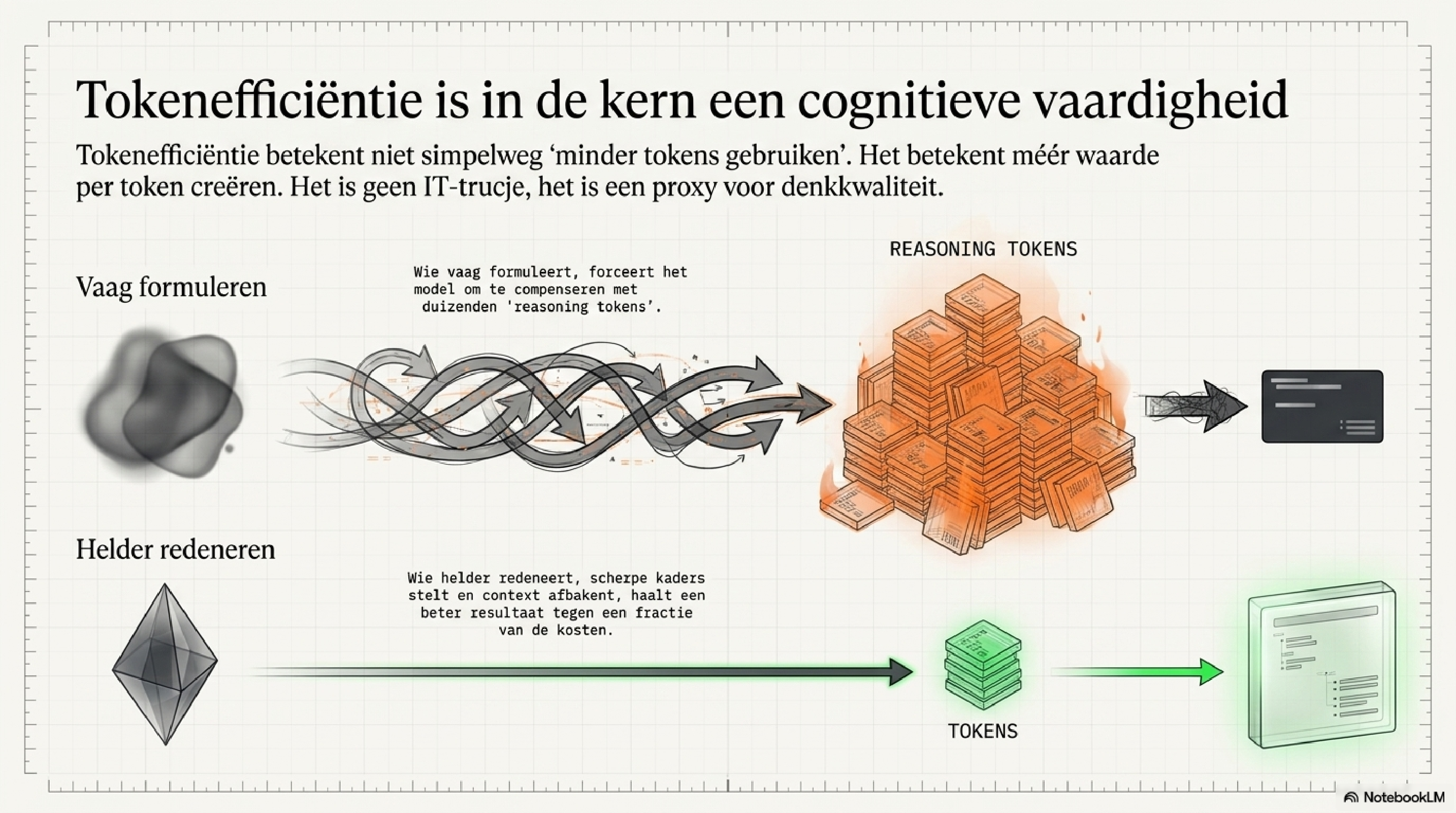
Tokenefficiëntie betekent: méér waarde per token, niet meer tokens per se. Het is geen bezuinigingstechniek. Het is een manier van denken.
Wie vaag formuleert, te breed vraagt, of de context niet goed afbakent, krijgt een omslachtig antwoord terug — en verbruikt daarvoor veel tokens. Wie precies weet wat hij vraagt, helder redeneert en de juiste informatie meegeeft, bereikt hetzelfde resultaat met een fractie van het verbruik. Tokenefficiëntie is daarmee een proxy voor denkkwaliteit: niet voor technische vaardigheid, maar voor het vermogen om helder te denken en goed te formuleren.
Die vaardigheid is nu nog een nichevaardigheid — iets wat developers met directe API-toegang en de eerste generatie AI-power users beoefenen. Maar het is de vaardigheid die straks structureel het onderscheid maakt. Zodra de uitgestelde rekening wordt ingelost — gedreven door aandeelhouderswaarde en een infrastructuur die haar eigen gewicht moet gaan dragen — wordt efficiëntie geen optimalisatie meer maar een kostenpost die telt.
Tokenefficiëntie is geen IT-begrip. Het is een cognitieve vaardigheid. Wie helder denkt, stelt gerichte vragen. Gerichte vragen kosten minder tokens. Minder tokens betekent lagere kosten én betere uitkomsten.
Wat organisaties al doen — en wat het verraadt
Terwijl de meeste gebruikers niets merken van dit alles, zijn organisaties wereldwijd al bezig de token als meetinstrument te gebruiken. En hoe ze dat doen, vertelt iets over hoe ver ze zijn.
Sommige bedrijven meten tokenverbruik puur als factuur: Zapier bouwde dashboards om te begrijpen welk gebruik waarde oplevert en welk gebruik ruis is. Anderen, zoals Meta en Shopify, koppelden het aan prestatiemeting — wie meer AI gebruikt, presteert beter, is de aanname. In Silicon Valley zijn interne leaderboards ontstaan waarbij engineers wedijveren wie de meeste tokens verbrandt; bij Anthropic liep een medewerker een maandelijkse rekening op van meer dan $150.000 — als statussymbool, volledig betaald door de werkgever. Tokens verbranden werd een doel op zichzelf: tokenmaxxing.
De meest volwassen aanpak is die van Vercel en Kumo AI: zij kijken niet naar het volume, maar naar wat het oplevert. Hoog verbruik dat waarde genereert is een investering. Hoog verbruik dat niets oplevert is verspilling. De verhouding daartussen — waarde per token — is efficiëntie. Dat is de vraag die de meeste bedrijven nog niet stellen, en tegelijk de vraag die er het meest toe doet.
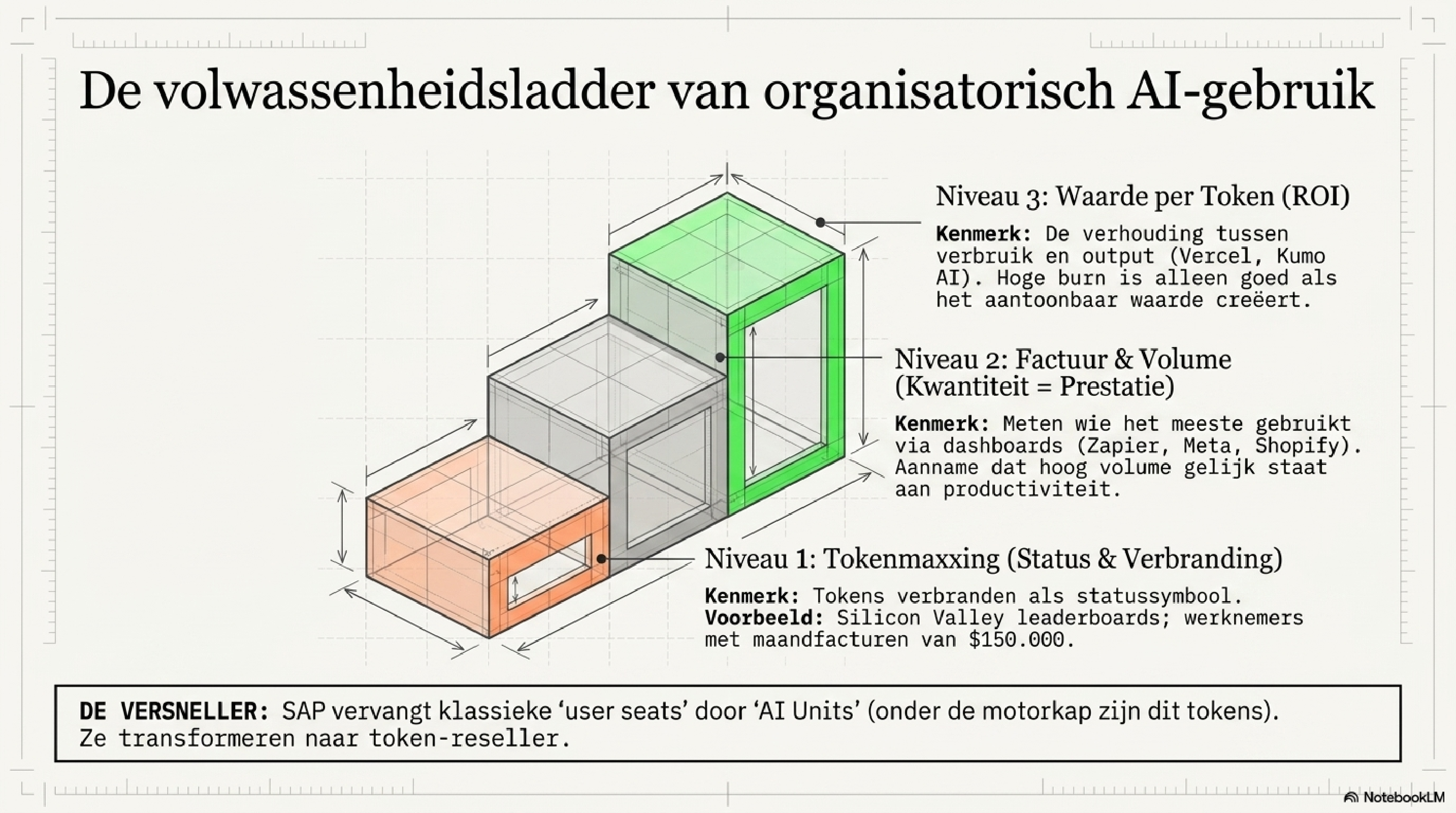
Ondertussen gooit SAP zijn volledig verdienmodel overboord. Als een AI-agent de taken van tien medewerkers overneemt, heb je tien keer zo weinig seats nodig. Dat is existentieel voor een bedrijf dat zijn omzet baseert op het aantal gebruikers. SAP's "AI Units" zijn onder de motorkap tokens, ingekocht bij Anthropic, OpenAI en Google en doorverkocht met een laag proceskennis eroverheen. SAP is in essentie een tokenreseller geworden. De conclusie die eruit volgt: systemen commoditiseren. Wat overblijft als onvervangbare differentiator is het menselijk vermogen om de juiste vragen te stellen en de uitkomst te beoordelen. Tokenefficiëntie als cognitieve vaardigheid is precies dat vermogen.
De meter die je niet kunt lezen
Hoeveel betaal je werkelijk voor de AI die je dagelijks gebruikt? Het antwoord hangt af van hoe je toegang hebt — en de eerlijkheid varieert sterk per wereld.
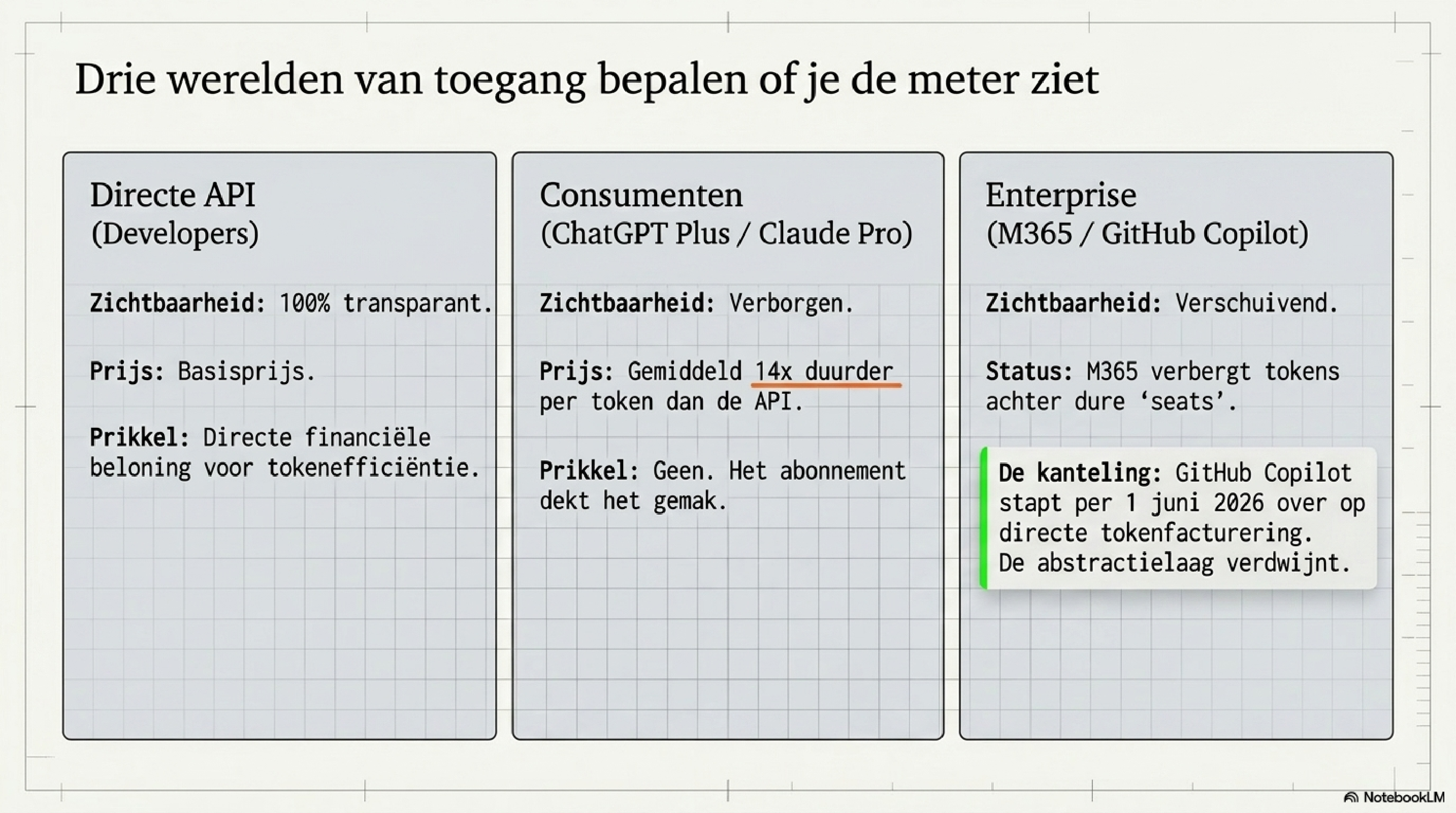
In de transparante wereld van directe API-toegang staat alles open: prijs per miljoen input-tokens, prijs per miljoen output-tokens, openbaar gepubliceerd door Anthropic, OpenAI, Google en xAI. Developers die hier werken weten precies wat ze betalen — en hebben daarmee ook de directe prikkel om tokenefficiënt te werken. Elke inefficiënte prompt staat direct op de rekening.
In de wereld van consumentenabonnementen — Claude Pro voor $20 per maand, ChatGPT Plus voor hetzelfde — is de tokenprijs verborgen maar terugrekbaar. Wie de moeite neemt om door te rekenen, ontdekt dat een gemiddelde gebruiker per token ruwweg veertien keer meer betaalt dan via de directe API. Dat is niet oneerlijk — het abonnement dekt ook gemak en eenvoud. Maar het is informatie die het abonnement zelf niet biedt.
In de enterprise-wereld is het beeld aan het verschuiven. Microsoft M365 Copilot blijft volledig verpakt: seat-fees zonder tokeninzicht, en de abonnementsprijzen stijgen per juli 2026 bovendien gewoon door. In die wereld ontbreekt de prikkel tot tokenefficiëntie structureel: wie tien vage prompts schrijft die elk twintig keer meer tokens kosten dan nodig, betaalt exact hetzelfde als wie scherp en precies werkt. Maar GitHub Copilot — de tool die developers dagelijks in hun IDE gebruiken — stapt per 1 juni 2026 over op directe tokenfacturering. De abstractielaag van "requests" verdwijnt. De meter wordt leesbaar. En wie hem afleest, ziet ook waarom tokenefficiëntie ertoe doet.
Wie de meter niet kan aflezen, kan de vaardigheid niet ontwikkelen.
De rekening wordt zichtbaarder
Terwijl de meeste gebruikers denken dat alles stabiel is, schuiven de grenzen gestaag.

In zes stappen over zes weken heeft Anthropic laten zien hoe de uitgestelde rekening stap voor stap wordt gepresenteerd. Piekuren worden gethrottled. Third-party tools worden afgesloten van het abonnement. Enterprise-klanten betalen voortaan per token in plaats van een vaste seat-fee. En bij de introductie van Claude Opus 4.7 werd stilzwijgend een nieuwe tokenizer meegeleverd — zelfde stickerprice, maar dezelfde invoer kost nu tot 35% meer tokens. Drie van de zes stappen zijn inmiddels teruggedraaid na gebruikersprotesten. Maar terugdraaien is niet vergeten. Het is: dit keer te vroeg, te zichtbaar, te veel weerstand. De richting is ongewijzigd.
Dat patroon heeft een naam: enshittification — het proces waarbij een dienst in het begin royaal en goedkoop is, en stap voor stap verslechtert naarmate het bedrijf winstgevend moet worden. De gebruiker is op dat moment al afhankelijk. En bij AI gaat de afhankelijkheid dieper dan bij eerdere technologiegolven: agents die zelfstandig processen uitvoeren, verweven raken in organisaties, continu tokens verbranden — ook als niemand kijkt. Wie zijn agents bewust inricht en tokenefficiëntie als vaardigheid heeft opgebouwd, houdt de meter leesbaar. Wie dat niet heeft gedaan, wordt verrast.
De verborgen variabele die alles vertroebelt
Er is een complicatie die de meeste discussies over AI-kosten missen: een token bij OpenAI is niet hetzelfde als een token bij Anthropic.

Elke aanbieder bouwt zijn eigen tokenizer — het systeem dat tekst opknipt in rekeneenheden. OpenAI verdubbelde zijn vocabulaire van 100.000 naar 200.000 items en werd daarmee 15–20% efficiënter. Google hanteert 262.000 items, wat niet-Engelstalige tekst aantoonbaar gunstiger behandelt. Anthropic's tokenizer is proprietary en niet openbaar — developers worden gefactureerd op basis van een telproces dat ze niet zelfstandig kunnen controleren.
De conclusie is ongemakkelijk: wie prijslijsten vergelijkt op basis van "dollar per miljoen tokens", vergelijkt eenheden die er hetzelfde uitzien maar fundamenteel anders zijn. Het is alsof drie bakkers elk hun eigen definitie van een kilogram hanteren — en allemaal hetzelfde bedrag per kilo rekenen. Je kunt je prompts optimaliseren, maar je kunt niet bepalen hoe de aanbieder jouw tekst opknipt. En je kunt niet voorkomen dat die definitie verandert bij een modelupdate.

En dan is er nog de taaltaks. Tokenizers zijn getraind op overwegend Engelstalige data. Engels is daardoor de meest efficiënte taal. Wie in het Nederlands werkt, betaalt structureel 30–35% meer tokens voor dezelfde inhoud, omdat samengestelde woorden en minder frequente tekenreeksen vaker worden opgeknipt. Voor Nederlandse gebruikers die Claude Opus 4.7 inzetten voor technische documentatie stapelen de effecten op: de taaltaks van ~35% plus de tokenizer-opslag van de nieuwe versie resulteert in tot 90% meer tokens dan een Engelstalige developer voor hetzelfde werk betaalt. Dezelfde stickerprice. Bijna het dubbele aantal tokens. Dit is een laag van de tokenrekening die buiten jouw controle ligt — maar die je wel kunt meenemen in je keuze voor aanbieder en model.
Wat intelligentie werkelijk kost

De nieuwste blog in de reeks trekt de lijn door naar de diepste laag.
De prijs per token staat op de prijspagina. Maar de werkelijke rekening is het product van twee factoren: de prijs per token én het aantal tokens dat een model nodig heeft om tot het goede antwoord te komen. Dat tweede getal varieert van model tot model, van taak tot taak, met een factor twee, vijf, of twintig — en staat nergens gepubliceerd.
Moderne frontier-modellen denken voordat ze antwoorden. Dat denkproces — reasoning tokens — bestaat zelf ook uit tokens, en wordt gefactureerd als output-tokens, het duurste tarief dat bestaat. Een zichtbaar antwoord van 200 woorden kan op 3.000 of meer interne redeneer-tokens hebben gedraaid. Je betaalt voor het geheel. Je ziet alleen het resultaat. Een scherpe, goed geformuleerde prompt verkleint de behoefte aan dat interne herschrijfproces — en bespaart daarmee onzichtbare kosten voor iets wat de gebruiker ook zelf had kunnen doen. Tokenefficiëntie werkt dus ook op dit niveau.

Dit herschrijft de vraag die elke organisatie zou moeten stellen. Niet: wat kost een token? Maar: hoeveel intelligentie krijg ik per dollar die ik uitgeef? Intelligence per dollar — de verhouding tussen modelprestaties en werkelijke tokenkosten — is het meetpunt dat ertoe doet. En het staat niet op de prijspagina.
Waarom dit verhaal nu verteld wordt
De negen blogs in deze reeks zijn geen technische documentatie en geen aanklacht. Ze zijn een poging om een economische verschuiving begrijpelijk te maken die nu al gaande is, maar voor de meeste mensen onzichtbaar blijft achter vriendelijke interfaces en comfortabele abonnementsprijzen.
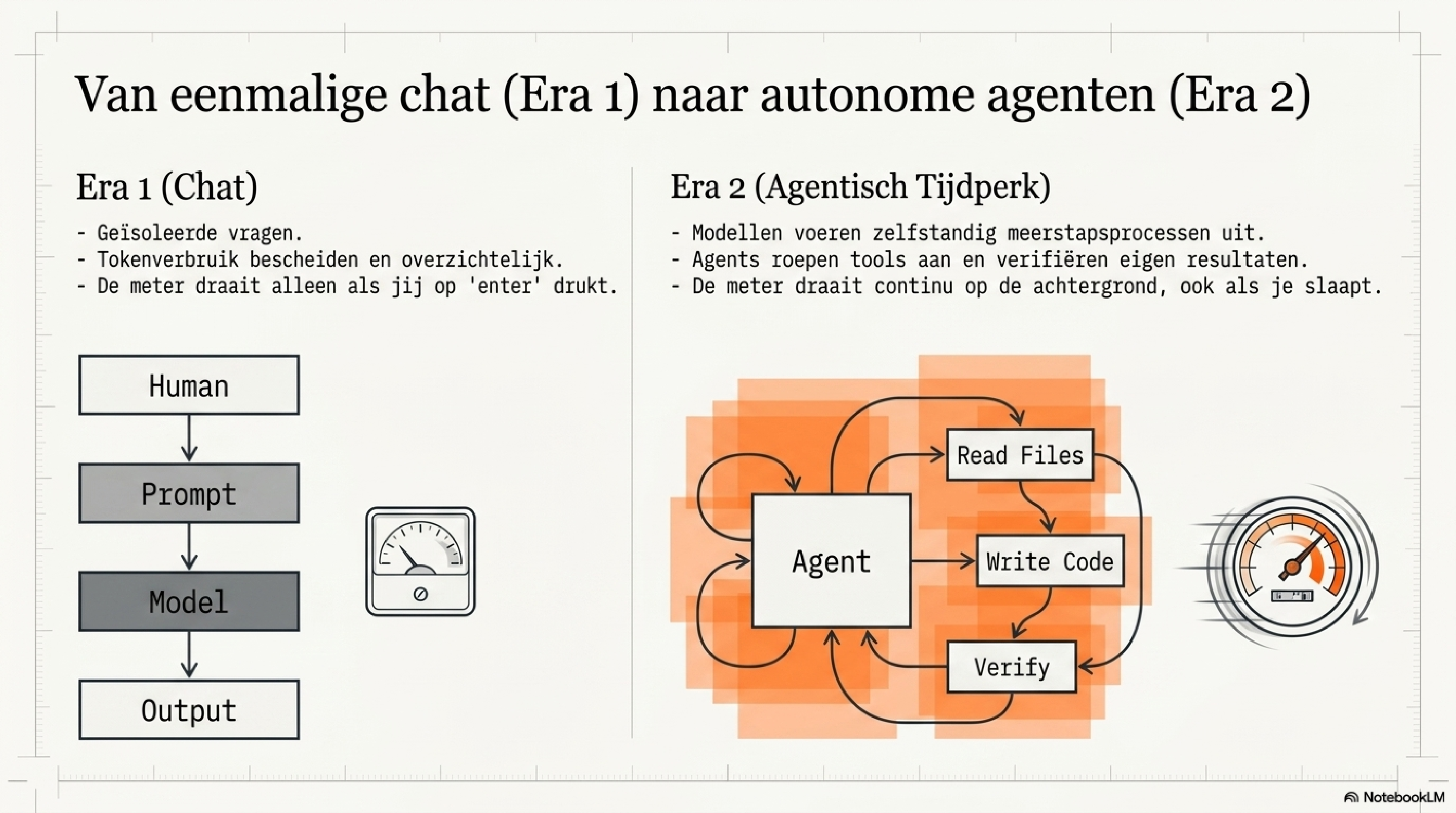
AI begon als een chatvenster — losse vragen, bescheiden tokenverbruik, overzichtelijke kosten. Maar de modellen zijn fundamenteel veranderd. Ze kunnen redeneren, coderen, plannen en taken autonoom uitvoeren. We zijn het agentische tijdperk ingegaan. Agents die zelfstandig werken, meerdere stappen zetten, tools aanroepen, bestanden lezen, code schrijven en resultaten controleren — en bij elke stap tokens verbranden, ook als niemand kijkt.
Dat betekent dat tokenverbruik niet langer iets is wat alleen developers met API-toegang hoeven te begrijpen. Het raakt iedereen die AI inzet voor serieus werk. De kosten lopen op. De afhankelijkheid verdiept. En wat je wel en niet zelf in de hand hebt — je prompt, je taalkeuze, je modelkeuze, je architectuur — wordt steeds bepalender voor wat je betaalt en wat je terugkrijgt.

De token is de grondstof van de nieuwe economie. Tokenefficiëntie is de vaardigheid om bewust met die grondstof om te gaan — niet als technische optimalisatie, maar als cognitieve basisvaardigheid voor iedereen die met AI werkt. Wie dat begrijpt, kiest bewuster welk model hij inzet voor welke taak, bouwt processen die hij kan sturen in plaats van processen die hem sturen, en wordt niet verrast door de rekening die onvermijdelijk komt.
De meter loopt al — hoe bewust ben je hiervan?
Deze blog maakt deel uit van een bredere reeks over AI als systeemverschuiving — van de economie van tokens tot de versnelling van de technologie en wat dat betekent voor mensen en organisaties. De technische kant van AI in de praktijk beschrijft Edwin van Dillen. De bredere gedachten over organisatie, intentie en uitvoering zijn uitgewerkt op augmentedorganisation.nl, intentdriven.nl en augmentedengineering.nl.
De tokenreeks — alle negen blogs
Tokens op de meter — 23 maart 2026 Sam Altman beschreef het businessmodel openlijk: intelligentie wordt een nutsvoorziening, afgerekend per token. Deze blog introduceert de token als rekeneenheid, beschrijft de verslavingsfase waarin AI-bedrijven nu zitten — goedkoop om afhankelijkheid te bouwen — en legt uit waarom de uitgestelde rekening reëel is. Tokenefficiëntie is al nu een strategische vaardigheid.
De tokeneconomie — 24 maart 2026 Alibaba richtte de Alibaba Token Hub op: een formele business unit met de missie "tokens creëren, distribueren en toepassen." Drie lagen — foundational modellen, API-distributie, agentic platforms — vormen een verticaal geïntegreerd ecosysteem. Opmerkelijk: de tokeneconomie benoemt zichzelf, terwijl eerdere technologiegolven pas achteraf werden benoemd.
De token als meetlat — 27 maart 2026 Naar aanleiding van een WSJ-artikel: vier lenzen waarop bedrijven tokenverbruik meten — als factuur (Zapier), als prestatiemeting (Meta, Shopify), als statussymbool (tokenmaxxing bij OpenAI en Anthropic intern), en als waarde-signaal (Vercel, Kumo AI). Centrale conclusie: tokenefficiëntie is een proxy voor denkkwaliteit, niet voor technische vaardigheid.
SAP wordt tokenreseller — 28 maart 2026 SAP-CEO Christian Klein kondigde het einde van het abonnementsmodel aan. Als AI-agents de taken van tien medewerkers overnemen, heb je tien keer zo weinig seats nodig. SAP's "AI Units" zijn onder de motorkap tokens ingekocht bij Anthropic, OpenAI en anderen — SAP is in essentie een tokenreseller geworden. Systemen commoditiseren; menselijk vermogen blijft de onvervangbare differentiator.
De meter die lastig is te lezen — 7 april 2026 Drie betalingswerelden: de transparante API-wereld, de verpakte abonnementswereld (Claude Pro, ChatGPT Plus), en de geabstraheerde enterprise-wereld (M365 Copilot, GitHub Copilot). Kernconclusie: abonnementen zijn voor de gemiddelde gebruiker 3× tot 14× duurder per token dan directe API-toegang. In de enterprise wrapper-wereld ontbreekt de prikkel tot tokenefficiëntie structureel.
Tokenafhankelijkheid — april 2026 Via de Black Mirror-aflevering Common People en het concept enshittification: hoe Anthropic in zes stappen laat zien hoe de uitgestelde rekening stap voor stap wordt gepresenteerd. Agentic AI verdiept de afhankelijkheid structureel. Besef waar je aan begint.
De tokenizer als verborgen variabele — april 2026 Een token bij OpenAI is niet hetzelfde als een token bij Anthropic. En een token bij Anthropic 4.6 is niet hetzelfde als bij 4.7. Vergelijking van alle grote labs op tokenizer-architectuur en vocabulaireomvang. De stickerprice is geen eerlijke vergelijkingsmaatstaf.
De taaltaks — april 2026 Er is een belasting die je nooit hebt gekozen en die nergens op je factuur staat: de taaltaks. Nederlandse tekst kost structureel 30–35% meer tokens dan equivalente Engelse tekst. Voor Nederlandse gebruikers van Opus 4.7 op technische content stapelen effecten op tot 90% meer tokens. De meter tikt voor sommigen harder dan voor anderen.
De prijs van intelligentie — mei 2026 De stickerprice staat op de prijspagina. Maar de werkelijke rekening is het product van twee factoren: de prijs per token én het aantal tokens dat een model nodig heeft om het goede antwoord te bereiken. Reasoning tokens — het onzichtbare denkproces van frontier-modellen — worden gefactureerd als output-tokens maar zijn nooit te lezen. Intelligence per dollar is het meetpunt dat ertoe doet. En het staat niet op de prijspagina.
Co-creatie: Dit stuk is gemaakt samen met Claude (Anthropic) en NotebookLM (Google). De gedachten, posities en interpretaties zijn van mij.