De tokenizer als verborgen variabele

De ene token is de andere niet
Dit is de zevende blog in mijn reeks over de tokeneconomie. Eerdere delen onderaan deze pagina met korte samenvatting.
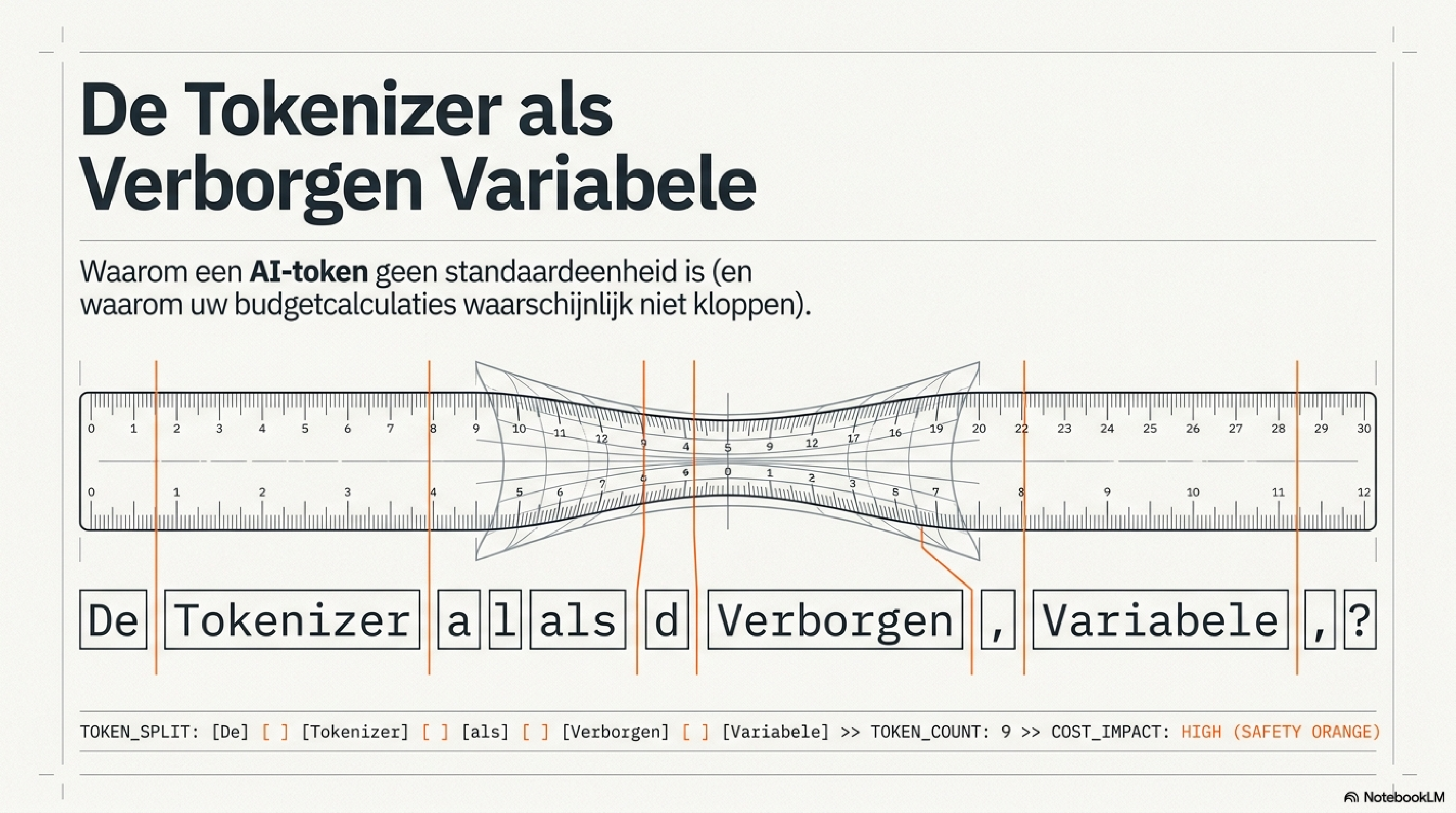
In de vorige blog beschreef ik hoe Anthropic in zes stappen de uitgestelde rekening stap voor stap presenteert. Stap vier was de meest technisch geladen: bij de lancering van Claude Opus 4.7 introduceerde Anthropic stilzwijgend een nieuwe tokenizer. Zelfde prijs per miljoen tokens — maar dezelfde invoer kost nu tot 47% meer tokens op technische content. Geen aankondiging. Geen changelog. Gewoon een andere definitie van de rekeneenheid.
Dat is de aanleiding voor deze blog. Want die wijziging bij Opus 4.7 wakkerde een bredere vraag aan: wat is een token eigenlijk precies? En is een token bij Anthropic hetzelfde als een token bij OpenAI, Google of xAI?
Het antwoord is nee. En dat heeft consequenties die verder gaan dan één modelupdate.
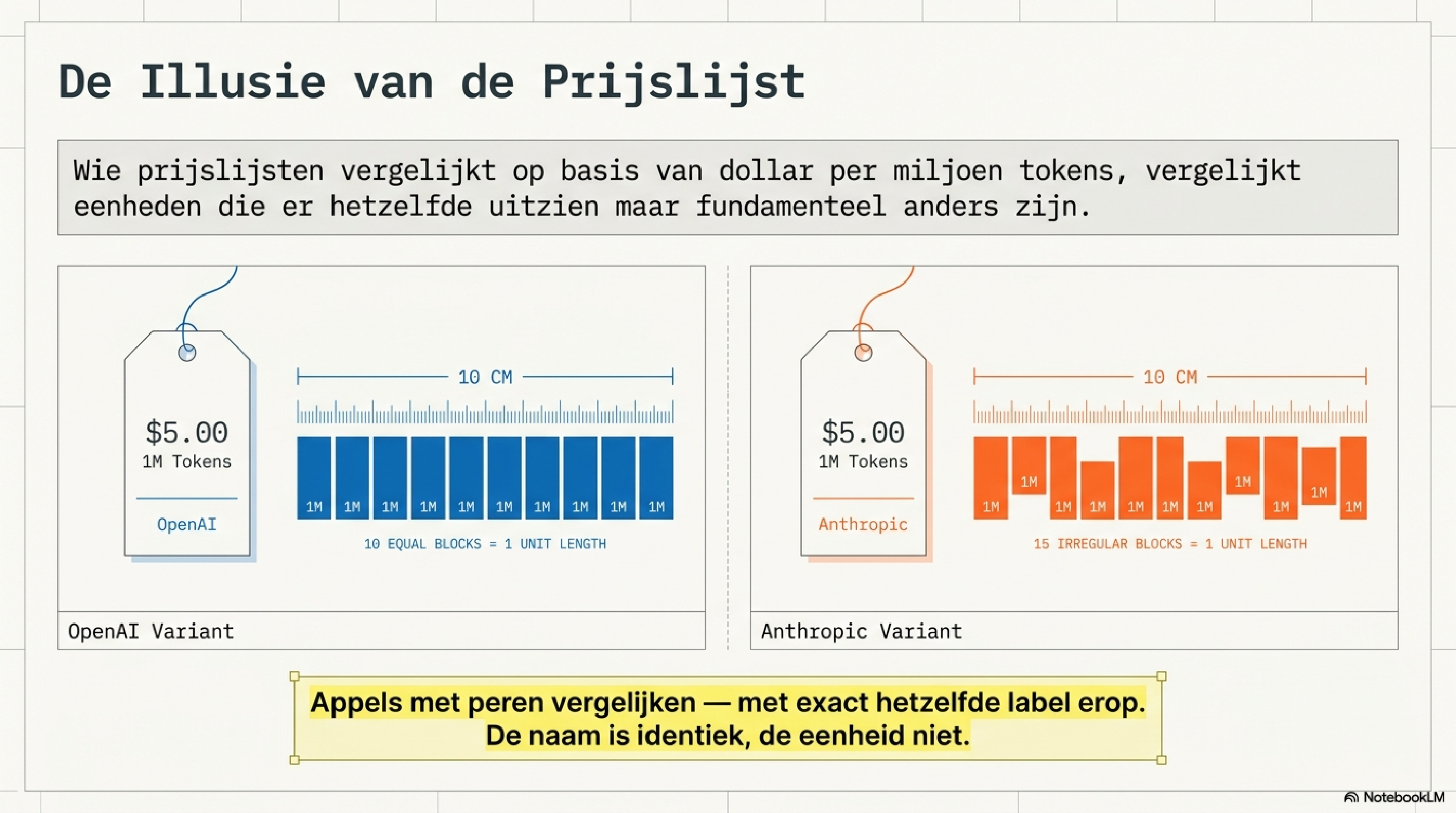
Een token bij OpenAI is niet hetzelfde als een token bij Anthropic. Een token bij Claude Opus 4.6 is niet hetzelfde als een token bij Claude Opus 4.7. De naam is identiek. De inhoud niet. Wie prijslijsten vergelijkt op basis van "dollar per miljoen tokens" vergelijkt eenheden die er hetzelfde uitzien maar fundamenteel anders zijn. Appels met peren — met hetzelfde label erop.
Dat is de tokenizer als verborgen variabele.
Hoe een tokenizer werkt
Voordat ik de verschillen tussen de labs bespreek, is het de moeite waard om kort uit te leggen wat er feitelijk gebeurt als tekst wordt omgezet naar tokens.
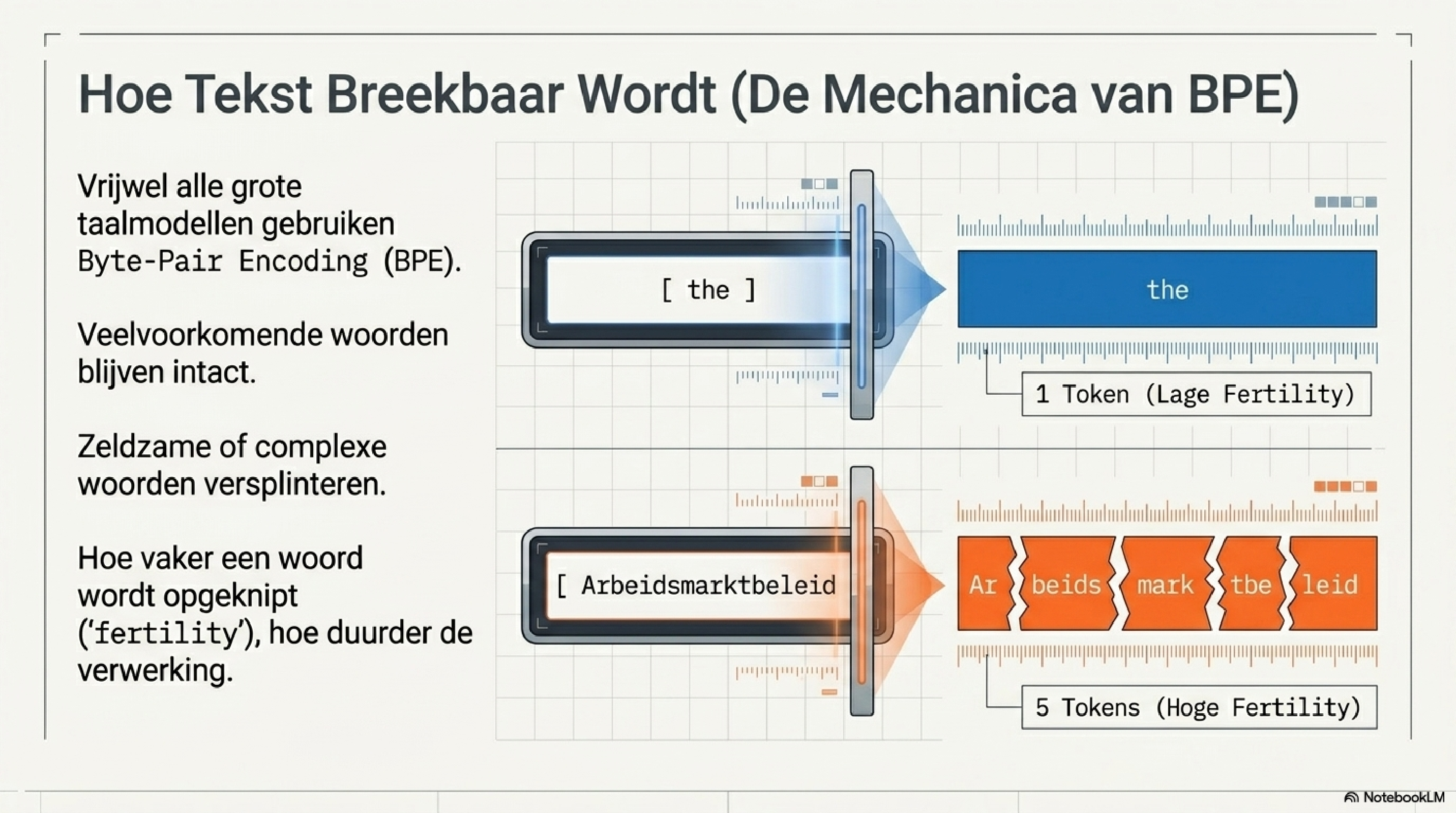
Vrijwel alle grote taalmodellen gebruiken een variant van Byte-Pair Encoding (BPE): een algoritme dat tekst opsplitst in subwoorden op basis van frequentie. Het begint met individuele karakters of bytes, en voegt iteratief de meest voorkomende paren samen tot nieuwe eenheden. Dit herhaalt zich totdat een vooraf bepaalde vocabulaireomvang is bereikt.
Het resultaat is een vocabulaire waarin veelvoorkomende woorden als één token zijn opgeslagen — "the", "is", "van" — en zeldzame of complexe woorden worden opgesplitst. "Tokenization" wordt "token" + "ization". "Arbeidsmarktbeleid" wordt misschien vijf losse stukken. Dat opknippen heet fertility: hoe meer tokens een woord kost, hoe hoger de fertility, hoe duurder de verwerking.
De sleutelkeuze die elke aanbieder maakt is de vocabulaireomvang: hoeveel unieke tokens worden er in de woordenlijst opgenomen? Een groter vocabulaire betekent dat meer woorden als één token worden herkend — efficiënter, maar de woordenlijst zelf wordt groter en het model complexer. Dat is de afweging. En elke aanbieder maakt hem anders.

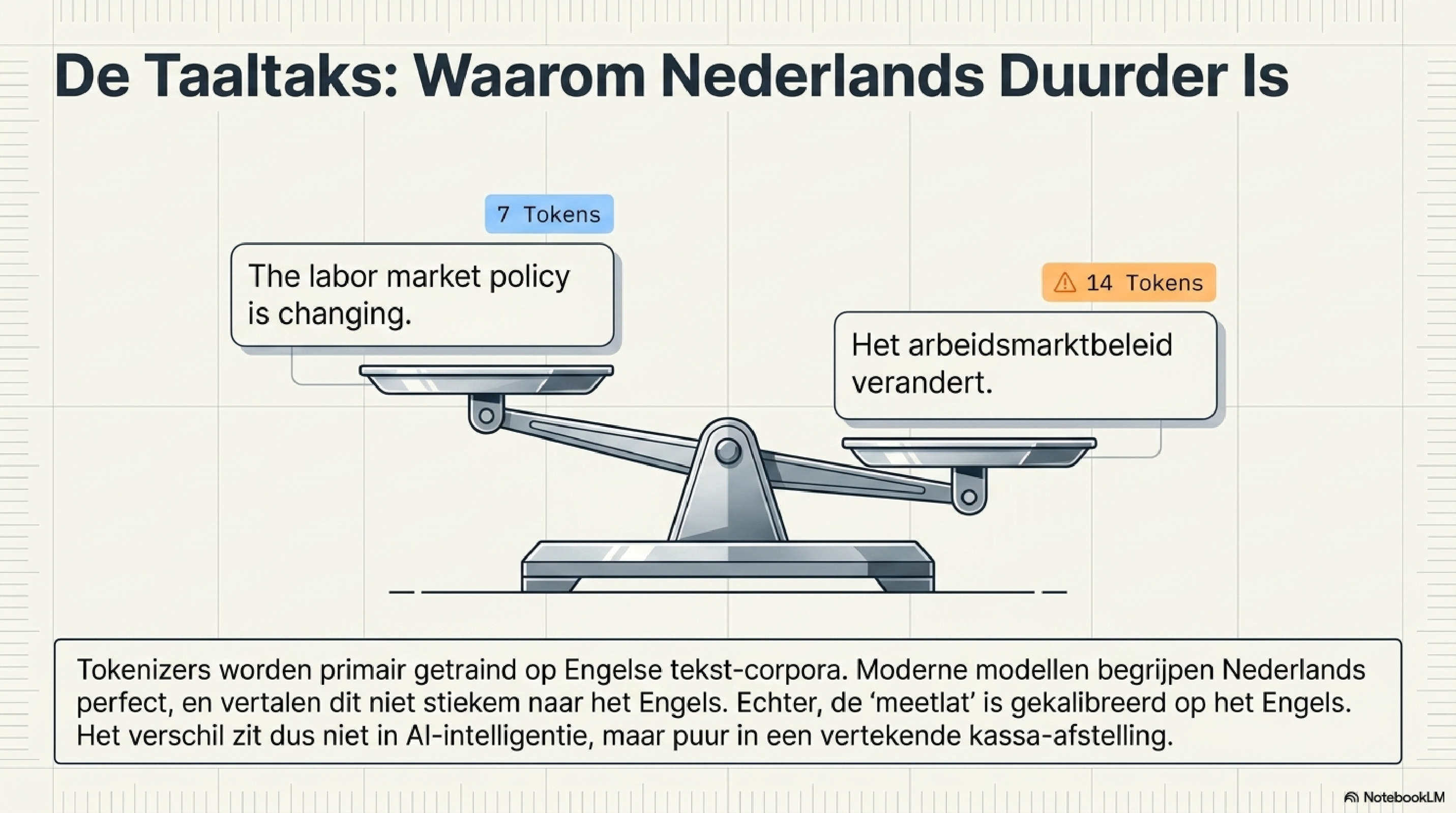
Daarbij speelt taal een cruciale rol. Een tokenizer wordt getraind op een corpus — een grote verzameling tekst — en dat corpus bestaat voor het grootste deel uit Engels. Het gevolg is dat Engelse woorden efficiënter worden opgeslagen: meer woorden als één token, minder opgeknipte stukken. Wie in het Nederlands, Duits of Frans werkt, betaalt structureel meer tokens voor dezelfde hoeveelheid inhoud — niet omdat zijn prompts slechter zijn, maar omdat zijn taal minder goed vertegenwoordigd is in de woordenlijst.
Een vraag die ik regelmatig hoor: vertalen modellen mijn Nederlandse input eerst naar het Engels voordat ze hem verwerken? Het antwoord is nee. Moderne taalmodellen werken rechtstreeks op de tokens zoals ze binnenkomen — er is geen interne vertaalstap. Maar de tokenizer is wél gebouwd op een Engels-zwaar vocabulaire. Het model begrijpt je Nederlands; de meetlat waarmee het je rekent, is primair voor Engels gemaakt. Het verschil zit dus niet in begrip, maar in prijs. Dat is de taaltaks — en die verdient een eigen blog.
De labs vergeleken
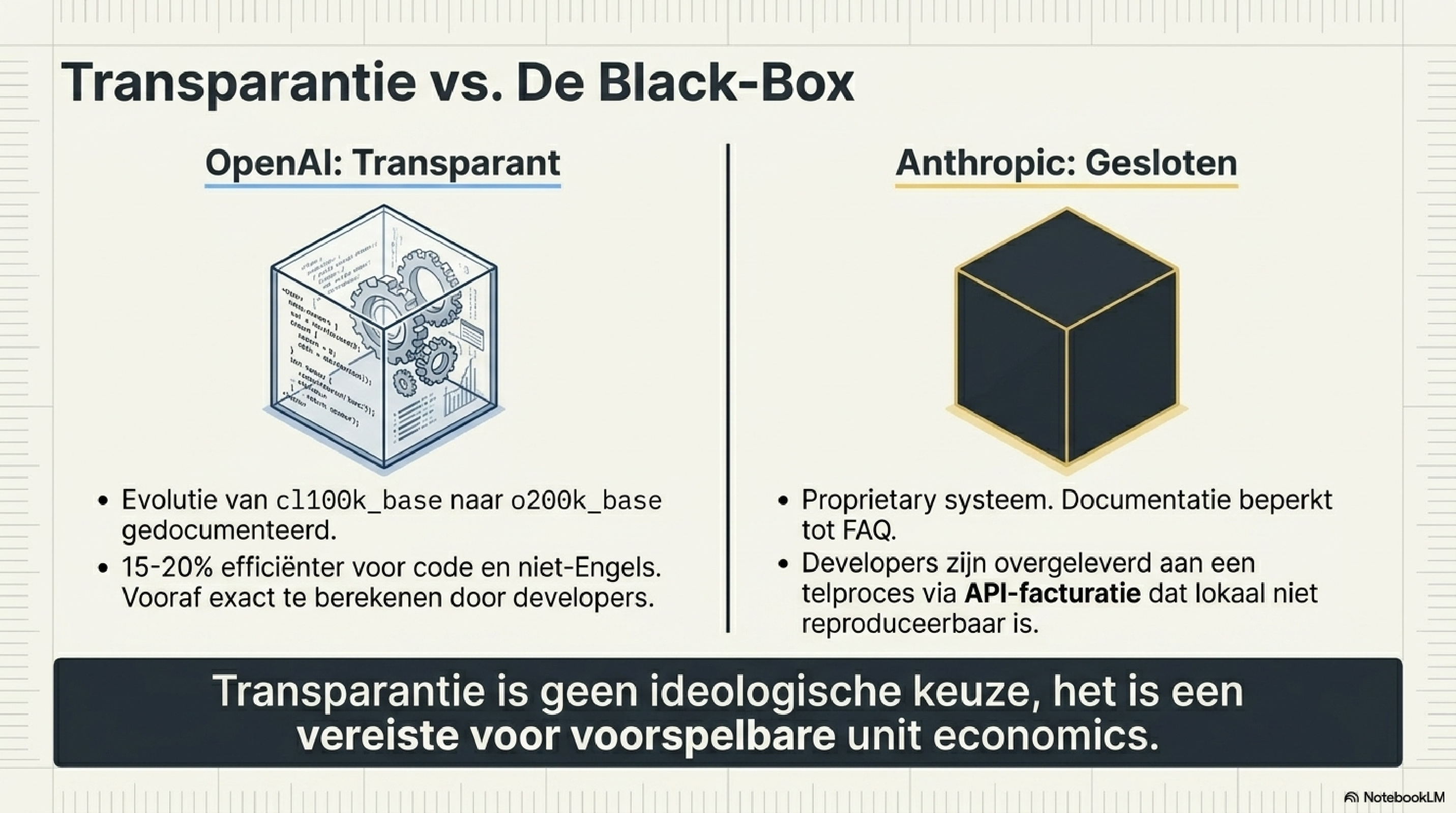
OpenAI — tiktoken, openbaar en geëvolueerd
OpenAI is de meest transparante speler: hun tokenizer tiktoken is open source en publiek gedocumenteerd. Ze hebben hem één keer significant bijgewerkt.
De eerste generatie — cl100k_base, gebruikt door GPT-3.5 en GPT-4 — bevat 100.256 vocabulaire-items. De tweede generatie — o200k_base, gebruikt door GPT-4o, o1, o3, GPT-4.1 en GPT-5 — verdubbelde dat naar 200.000 items. Dat grotere vocabulaire betaalt zich uit: o200k_base is 15–20% efficiënter dan cl100k_base, met name voor niet-Engels tekst en code. Het woord "Tokenization" telt bij cl100k_base twee tokens ("Token" + "ization"); bij o200k_base is het één geheel.
OpenAI heeft deze overgang goed gecommuniceerd, de tokenizer openbaar gemaakt, en de prijsstelling expliciet per encoding gedocumenteerd. Voor developers is de impact vooraf te berekenen.
Google — SentencePiece, Unigram, groot vocabulaire
Google hanteert een fundamenteel ander algoritme dan BPE. Hun tokenizer gebruikt SentencePiece met een Unigram-taalmodel: in plaats van paren iteratief samen te voegen, begint het met een enorme lijst kandidaat-subwoorden die probabilistisch worden gescoord en gesnoeid totdat het gewenste vocabulaire overblijft.
Het resultaat voor de Gemini-modellenreeks: alle Gemini-modellen — van Gemini Flash tot Gemini 2.5 Pro — gebruiken dezelfde tokenizer op basis van het Gemma 3 SentencePiece-model, met een vocabulaire van 262.144 items. Dat is het grootste vocabulaire van de grote labs. Google documenteert het eenvoudig: een token is equivalent aan ongeveer 4 karakters, 100 tokens staat gelijk aan 60–80 Engelse woorden.
Het grote vocabulaire werkt in het voordeel van niet-Engelstalige gebruikers. In onafhankelijk onderzoek naar Europese talen presteert Gemma consequent beter dan Mistral en Llama — doordat meer woorden als één token worden herkend in plaats van opgeknipt. Voor organisaties die primair in het Nederlands werken is dit een relevant verschil.
xAI / Grok — SentencePiece met byte-fallback, middelgroot
xAI kiest voor een middenpositie. Grok-1 gebruikt SentencePiece met byte-fallback en een vocabulaireomvang van 131.072 items — het dubbele van vroege Llama-modellen (32k), maar kleiner dan OpenAI's o200k_base en Google's 262k. De byte-fallback zorgt dat zelfs volledig onbekende karakters of symbolen altijd kunnen worden weergegeven, zonder "unknown token"-fouten.
xAI erkent in hun eigen documentatie expliciet dat verschillende Grok-modellen verschillende tokenizers kunnen gebruiken, en dat hetzelfde bericht bij verschillende modellen daardoor een ander tokenaantal kan opleveren. Ze bieden een tokenizer-tool aan in de xAI Console zodat developers vooraf kunnen tellen.
Anthropic — proprietary, ongedocumenteerd, nu veranderd
Anthropic's tokenizer is het meest ondoorzichtig van alle grote labs. Er is geen open-source release, geen publieke specificatie, en de documentatie beperkt zich tot een alinea in de pricing FAQ. Developers worden gefactureerd op basis van een telproces dat ze niet zelfstandig kunnen reproduceren.
Tot voor kort was dit een abstracte klacht. In april 2026 werd het concreet.
Claude Opus 4.7 gebruikt een nieuwe tokenizer. De stickerprice bleef gelijk: $5 per miljoen input tokens en $25 per miljoen output tokens — identiek aan Opus 4.6. Maar Anthropic documenteerde zelf dat dezelfde invoer nu ruwweg 1,0–1,35× zoveel tokens kan kosten. In de praktijk, gemeten op technische documentatie en realistische CLAUDE.md-bestanden, werden waarden van 1,45–1,47× geconstateerd. De bovenkant van Anthropic's eigen range is precies waar het meeste Claude Code-gebruik feitelijk zit.
Dezelfde stickerprice. Meer tokens per prompt. Het sessievenster raakt eerder op. De rate limit komt sneller dichtbij.
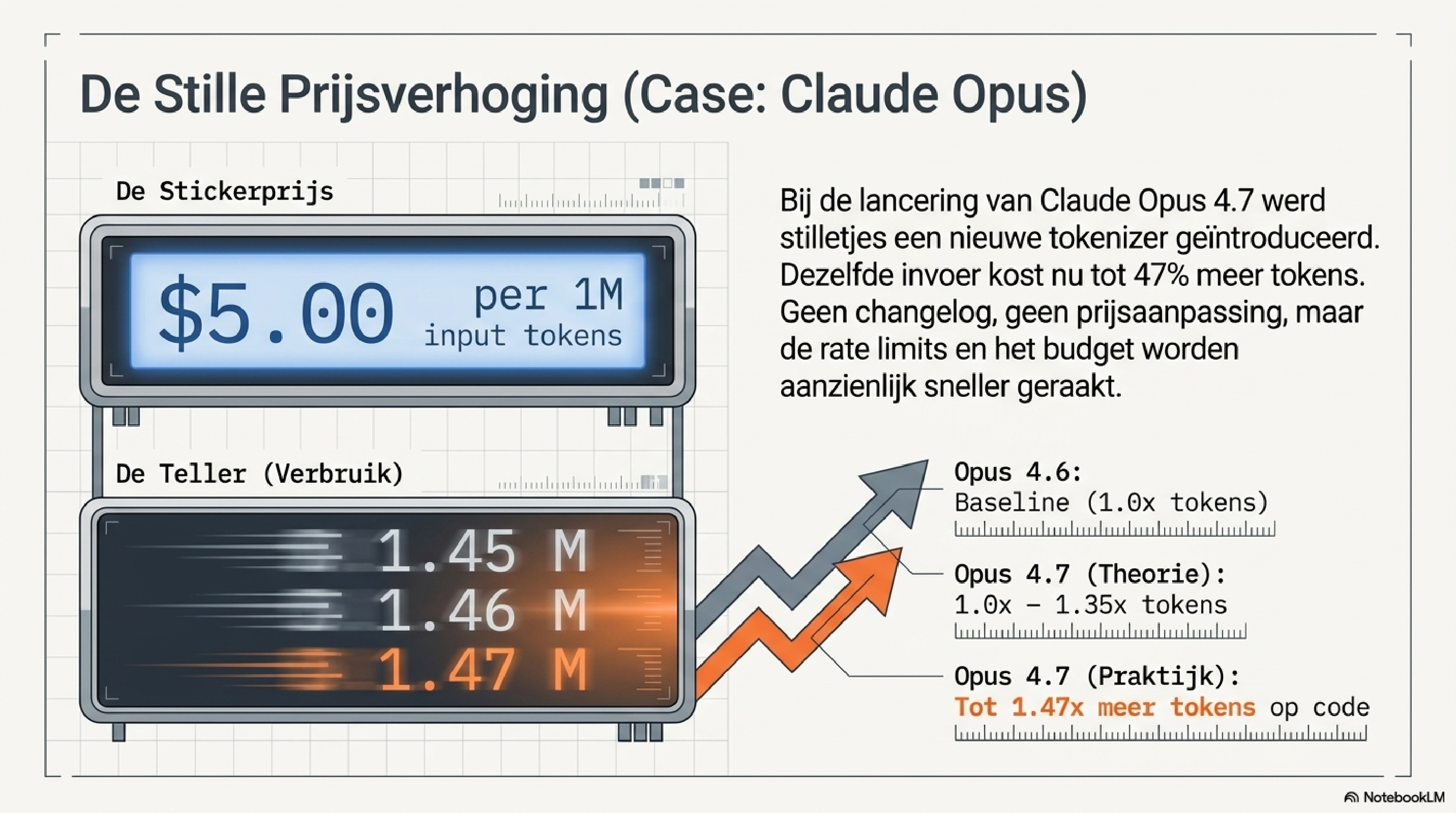
De reden die Anthropic geeft is technisch valide: kleinere tokens dwingen het model tot aandacht voor individuele woorden, wat nauwkeurigere instructieopvolging oplevert. Partnerrapportages van Notion, Warp en Factory bevestigen minder toolfouten bij langere agent-runs. De tokenizer is aangepast als kwaliteitsverbetering, niet als verkapte prijsverhoging.
Maar het effect is hetzelfde: de effectieve kosten per interactie stijgen, zonder dat de gepubliceerde prijs verandert. En omdat de tokenizer niet openbaar is, kan geen enkele developer dat vooraf berekenen of controleren. In de vorige blog beschreef ik dit als één van de zes stappen waarmee Anthropic de uitgestelde rekening stap voor stap presenteert. De tokenizer is stap vier.
Microsoft — geen eigen tokenizer
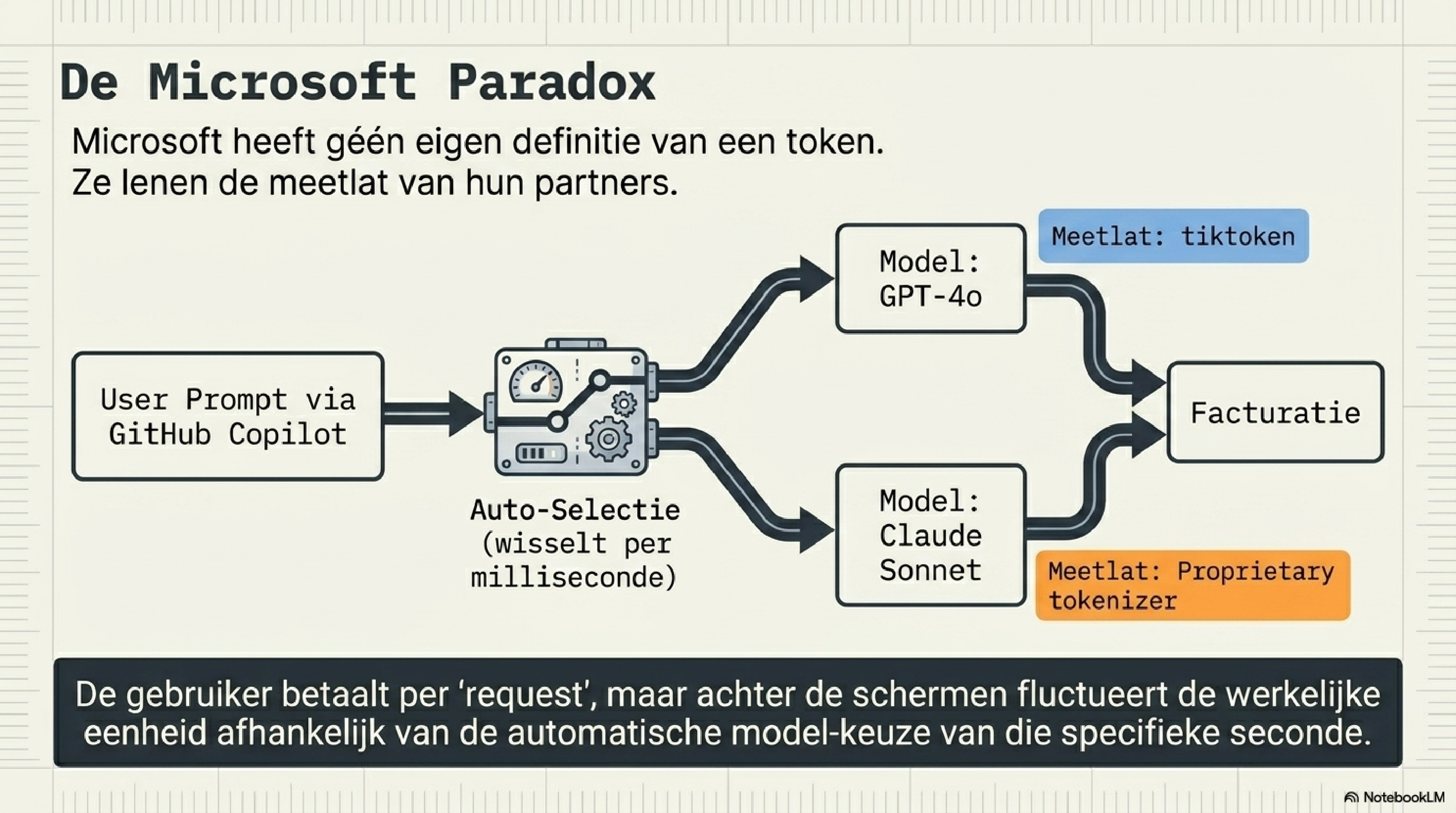
Microsoft is het meest bijzondere geval, omdat het de enige grote speler is zonder eigen tokenizer.
Azure OpenAI levert OpenAI-modellen door via Microsoft's cloudinfrastructuur. De tokenizer die daarin wordt gebruikt is tiktoken — OpenAI's tokenizer, ongewijzigd. Microsoft heeft zijn eigen .NET- en TypeScript-implementaties gebouwd op basis van de OpenAI Rust-bibliotheek, maar de vocabulaire en merge-regels zijn identiek aan die van OpenAI.
GitHub Copilot voegt een extra abstractielaag toe: het model dat per interactie wordt ingezet — GPT-4.1, Claude Sonnet, of een ander — bepaalt welke tokenizer telt. Bij auto-selectie in VS Code wisselt dat per taak, zonder dat de gebruiker het ziet. Wie Copilot gebruikt betaalt per request, niet per token — maar achter die request zit een tokenizer die afhankelijk is van het model dat op dat moment werd gekozen.
Microsoft heeft geen eigen definitie van een token. Ze lenen die definitie van hun modelpartners — en het antwoord op "hoeveel tokens kostte dit?" hangt af van wie er vandaag aan de beurt was.
De vergelijking op een rij
| Aanbieder | Tokenizer | Type | Vocabulaire | Open source? |
|---|---|---|---|---|
| OpenAI | tiktoken (cl100k → o200k) | BPE | 100k → 200k | Ja |
| SentencePiece (Gemma 3) | Unigram | 262k | Model open, gewichten publiek | |
| xAI | SentencePiece + byte-fallback | SentencePiece | 131k | Grok-1 open, latere modellen niet |
| Anthropic | Proprietary | Onbekend | Onbekend | Nee |
| Microsoft | Geen eigen — leent van model | BPE (via tiktoken) | Afhankelijk van model | n.v.t. |
Wat dit overzicht laat zien: de "prijs per miljoen tokens" die aanbieders publiceren is geen vergelijkbare eenheid. OpenAI's $5 per miljoen tokens bij GPT-5 is een andere maatstaf dan Anthropic's $5 bij Opus 4.7 — niet alleen omdat de modellen anders zijn, maar omdat een token bij de één niet hetzelfde is als een token bij de ander. Wie uitsluitend op stickerprice vergelijkt, vergelijkt appels met peren.

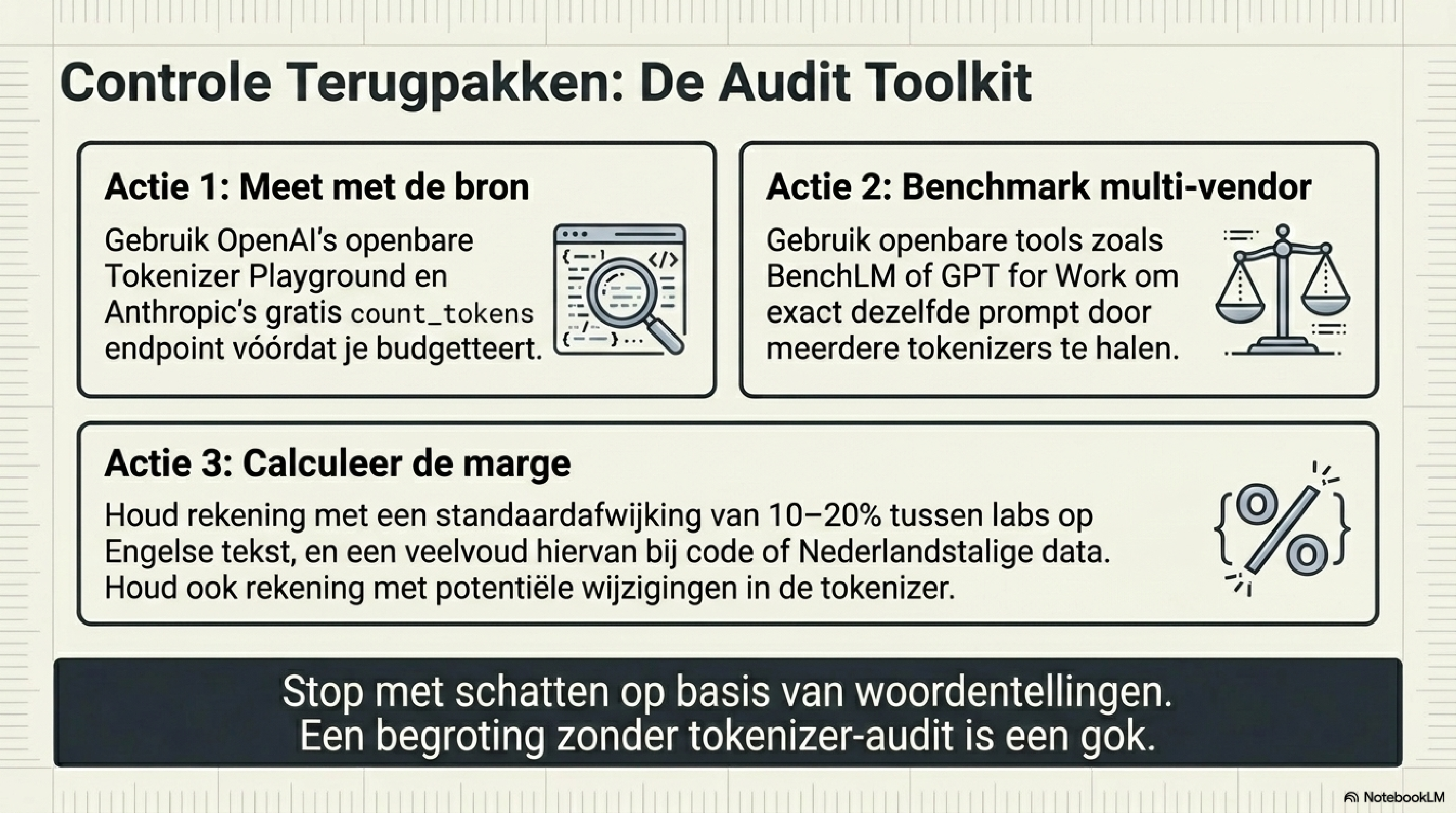
Wie het zelf wil meten: er bestaan online tools waarmee je dezelfde tekst door meerdere tokenizers kunt halen en de uitkomsten naast elkaar kunt zetten. OpenAI heeft een publieke Tokenizer Playground. Tools als GPT for Work en BenchLM bieden vergelijkingen over meerdere aanbieders. Anthropic biedt een officiële count_tokens-endpoint aan die gratis is te gebruiken. De uitkomsten voor Engelse tekst liggen doorgaans 10–20% uiteen tussen de grote labs — bij code, niet-Latijnse scripts of technische documentatie loopt dat verschil verder op.
De diepere consequentie
In de vorige blogs in deze reeks beschreef ik tokenefficiëntie als cognitieve vaardigheid: wie helder denkt en precies formuleert, verbruikt minder tokens en bereikt betere uitkomsten. Dat argument staat nog steeds.
Maar de tokenizer voegt een laag toe die buiten jouw controle ligt. Je kunt je prompts optimaliseren. Je kunt je agents efficiënter inrichten. Je kunt leren denken in tokens. Maar je kunt niet bepalen hoe de aanbieder jouw tekst opknipt. Je kunt niet voorkomen dat die definitie verandert bij een modelupdate. En je kunt niet zelfstandig berekenen wat een interactie kost als de tokenizer niet openbaar is.
De tokenizer is de verborgen variabele in elke kostencalculatie. En zolang hij verborgen blijft, is elke begroting op basis van tokenverbruik een schatting, geen meting.
Maar er is een diepere laag. Bij energie bestaat een universele eenheid: een kilowattuur is een kilowattuur, ongeacht leverancier, land of tijdstip. Die standaard is er omdat ze ooit is afgedwongen — door regulering, door marktwerking, door de noodzaak van vergelijkbaarheid.

Een token is dat niet. Er bestaat geen universele definitie. Elke lab bepaalt zijn eigen rekeneenheid, past hem aan wanneer het hem uitkomt, en hoeft dat niet te communiceren. Anthropic heeft in april laten zien wat dat in de praktijk betekent: zelfde prijs, andere maatstaf, geen aankondiging. Ze hebben een knop waar ze aan kunnen draaien. En ze draaien eraan.
Dat is geen technisch ongemak. Het is een machtspositie. Wie intelligentie inkoopt in tokens, koopt in een eenheid die de verkoper zelf definieert — en opnieuw kan definiëren. De afhankelijkheid zit niet alleen in het gebruik. Ze zit in de meetlat zelf.

De tokenreeks — eerder verschenen
Tokens op de meter — 23 maart 2026 Sam Altman beschreef het businessmodel openlijk: intelligentie wordt een nutsvoorziening, afgerekend per token. Deze blog introduceert de token als rekeneenheid, beschrijft de verslavingsfase waarin AI-bedrijven nu zitten — goedkoop om afhankelijkheid te bouwen — en legt uit waarom de uitgestelde rekening reëel is. Tokenefficiëntie is al nu een strategische vaardigheid.
De tokeneconomie — 24 maart 2026 Alibaba richtte de Alibaba Token Hub op: een formele business unit met de missie "tokens creëren, distribueren en toepassen." Drie lagen — foundational modellen, API-distributie, agentic platforms — vormen een verticaal geïntegreerd ecosysteem. Opmerkelijk: de tokeneconomie benoemt zichzelf, terwijl eerdere technologiegolven pas achteraf werden benoemd.
De token als meetlat — 27 maart 2026 Naar aanleiding van een WSJ-artikel: vier lenzen waarop bedrijven tokenverbruik meten — als factuur (Zapier), als prestatiemeting (Meta, Shopify), als statussymbool (tokenmaxxing bij OpenAI en Anthropic intern), en als waarde-signaal (Vercel, Kumo AI). Centrale conclusie: tokenefficiëntie is een proxy voor denkkwaliteit, niet voor technische vaardigheid.
SAP wordt tokenreseller — 28 maart 2026 SAP-CEO Christian Klein kondigde het einde van het abonnementsmodel aan. Als AI-agents de taken van tien medewerkers overnemen, heb je tien keer zo weinig seats nodig. SAP's "AI Units" zijn onder de motorkap tokens ingekocht bij Anthropic, OpenAI en anderen — SAP is in essentie een tokenreseller geworden. Systemen commoditiseren; menselijk vermogen blijft de onvervangbare differentiator.
De meter die lastig is te lezen — 7 april 2026 Drie betalingswerelden: de transparante API-wereld, de verpakte abonnementswereld (Claude Pro, ChatGPT Plus), en de geabstraheerde enterprise-wereld (M365 Copilot, GitHub Copilot). Kernconclusie: abonnementen zijn voor de gemiddelde gebruiker 3× tot 14× duurder per token dan directe API-toegang. In de enterprise wrapper-wereld ontbreekt de prikkel tot tokenefficiëntie structureel.
Tokenafhankelijkheid — 30 april 2026 Via de Black Mirror-aflevering Common People en het concept enshittification: hoe Anthropic in zes stappen laat zien hoe de uitgestelde rekening stap voor stap wordt gepresenteerd — van piekuur-throttling en afsluiting van third-party tools tot een nieuwe tokenizer bij Claude Opus 4.7. Agentic AI verdiept de afhankelijkheid structureel. Tokenefficiëntie als bewuste keuze, niet als bezuiniging.
Co-creatie: Dit stuk is gemaakt samen met Claude (Anthropic) en NotebookLM (Google). De gedachten, posities en interpretaties zijn van mij.