De taaltaks

Waarom Nederlands duurder is dan Engels — maar een stuk goedkoper dan Grieks
Dit is de achtste blog in mijn reeks over de tokeneconomie. Eerdere delen onderaan deze pagina met korte samenvatting.

Er is een belasting die je nooit hebt gekozen, die nergens op je factuur staat, en die je niet kunt afschaffen door efficiënter te werken. Je betaalt hem elke keer dat je een prompt schrijft in het Nederlands.
Ik noem hem de taaltaks.
Hij is geen opzet. Hij is geen beleid. Hij is een bijproduct van een technische keuze die de grote AI-labs hebben gemaakt: hun tokenizers zijn getraind op trainingsdata die overwegend uit Engelse tekst bestond. Het gevolg is dat Engels de meest efficiënte taal is voor vrijwel elke grote tokenizer — en dat alle andere talen, in wisselende mate, meer tokens verbruiken voor dezelfde hoeveelheid inhoud.
De prijspagina's vermelden allemaal hetzelfde bedrag per miljoen tokens. Maar de hoeveelheid tokens die jij verbruikt voor een Nederlandse tekst van duizend woorden is structureel hoger dan wat een Engelstalige concurrent betaalt voor dezelfde tekst in het Engels.
Dat is de taaltaks. En hij is meetbaar.

Hoe de taaltaks wordt gemeten
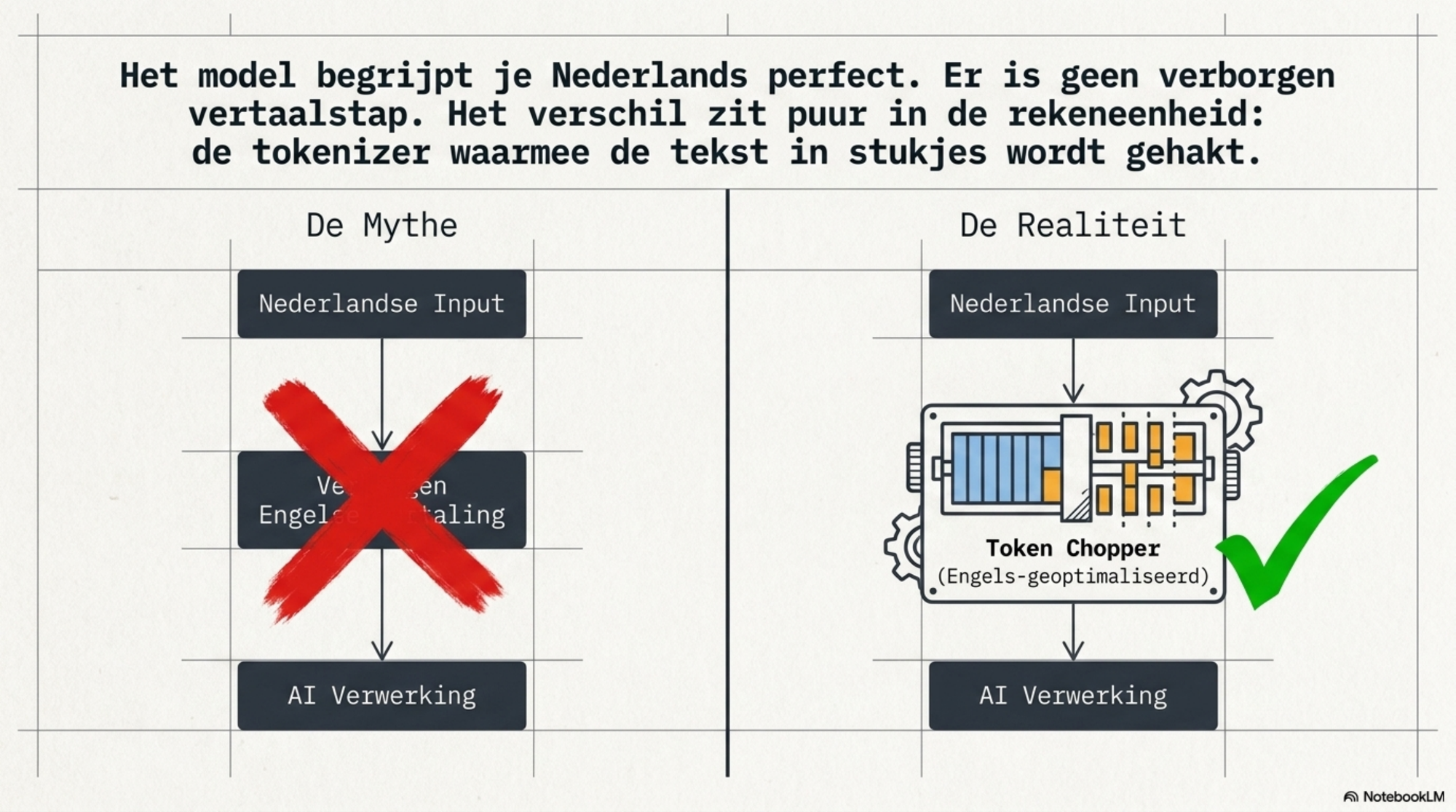
Een misverstand dat ik regelmatig tegenkom: de gedachte dat een model jouw Nederlandse invoer eerst intern vertaalt naar het Engels voordat het hem verwerkt. Dat klopt niet. Zoals ik in de vorige blog al beschreef: moderne taalmodellen werken rechtstreeks op de tokens zoals ze binnenkomen — er is geen verborgen vertaalstap. Het model begrijpt je Nederlands. Maar de tokenizer waarmee het je tekst opknipt en factureert, is primair gebouwd op Engels. Het verschil zit dus niet in begrip, maar in prijs.
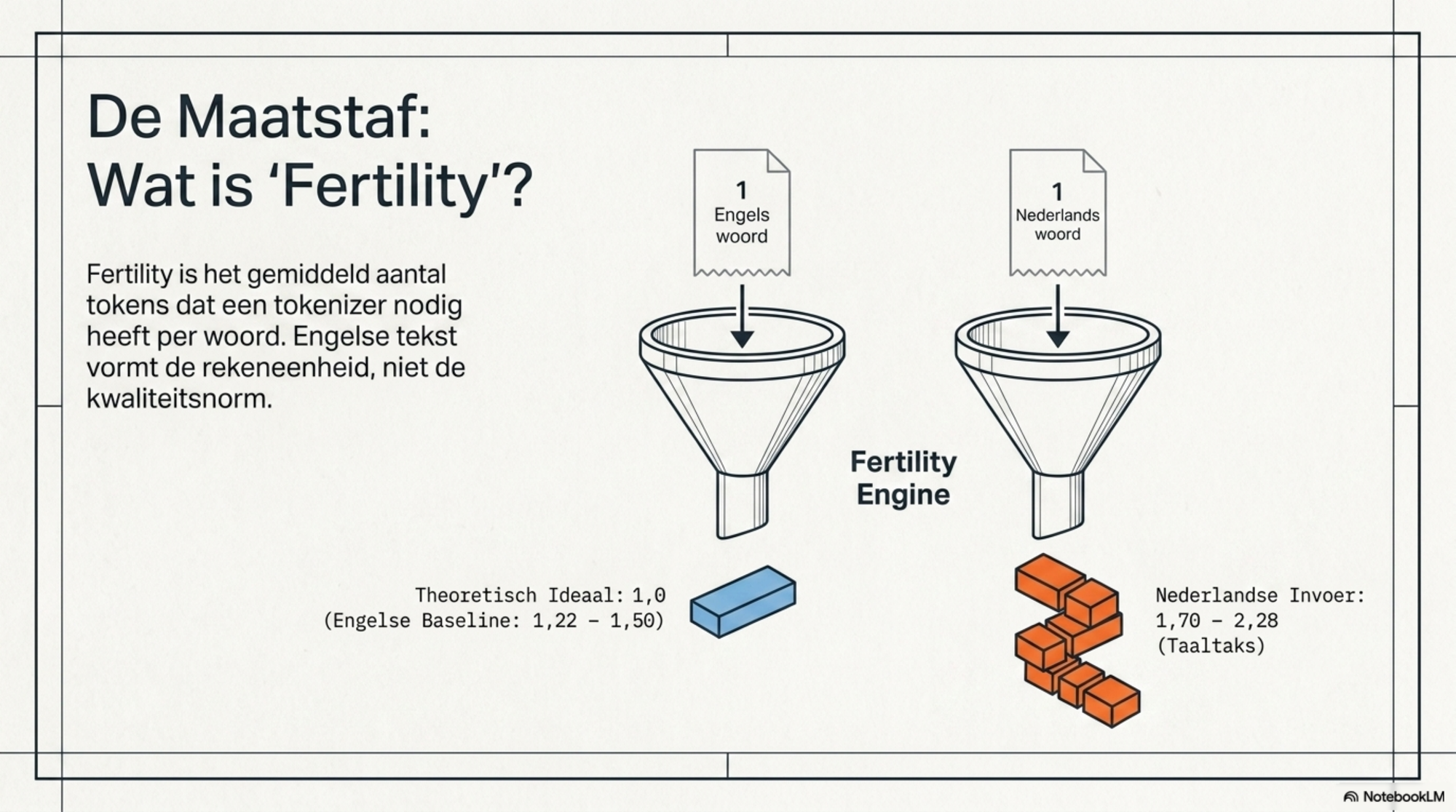
De maatstaf om dat prijsverschil te kwantificeren heet fertility: het gemiddeld aantal tokens dat een tokenizer nodig heeft per woord. Een fertility van 1,0 is het theoretische ideaal — één token per woord. Hogere fertility betekent meer tokens, hogere kosten, sneller opgebruikt sessiebudget.
Onderzoekers van het Occiglot-project — een Europees initiatief voor meertalige taalmodellen — hebben de fertilitywaarden systematisch gemeten voor 29 Europese talen over vier grote tokenizers. Onafhankelijk onderzoek, waaronder een analyse uit 2024 die fertilityscores vergeleek voor GPT-4o, Mistral, Llama, Qwen en DeepSeek over meerdere talen, bevestigt het beeld: Engels is structureel bevoordeeld als rekeneenheid, niet als taal of als kwaliteit van input.
Engels scoort als baseline tussen 1,22 en 1,50, afhankelijk van de tokenizer en het type tekst. Dat is het referentiepunt. Alles daarboven is taaltaks.
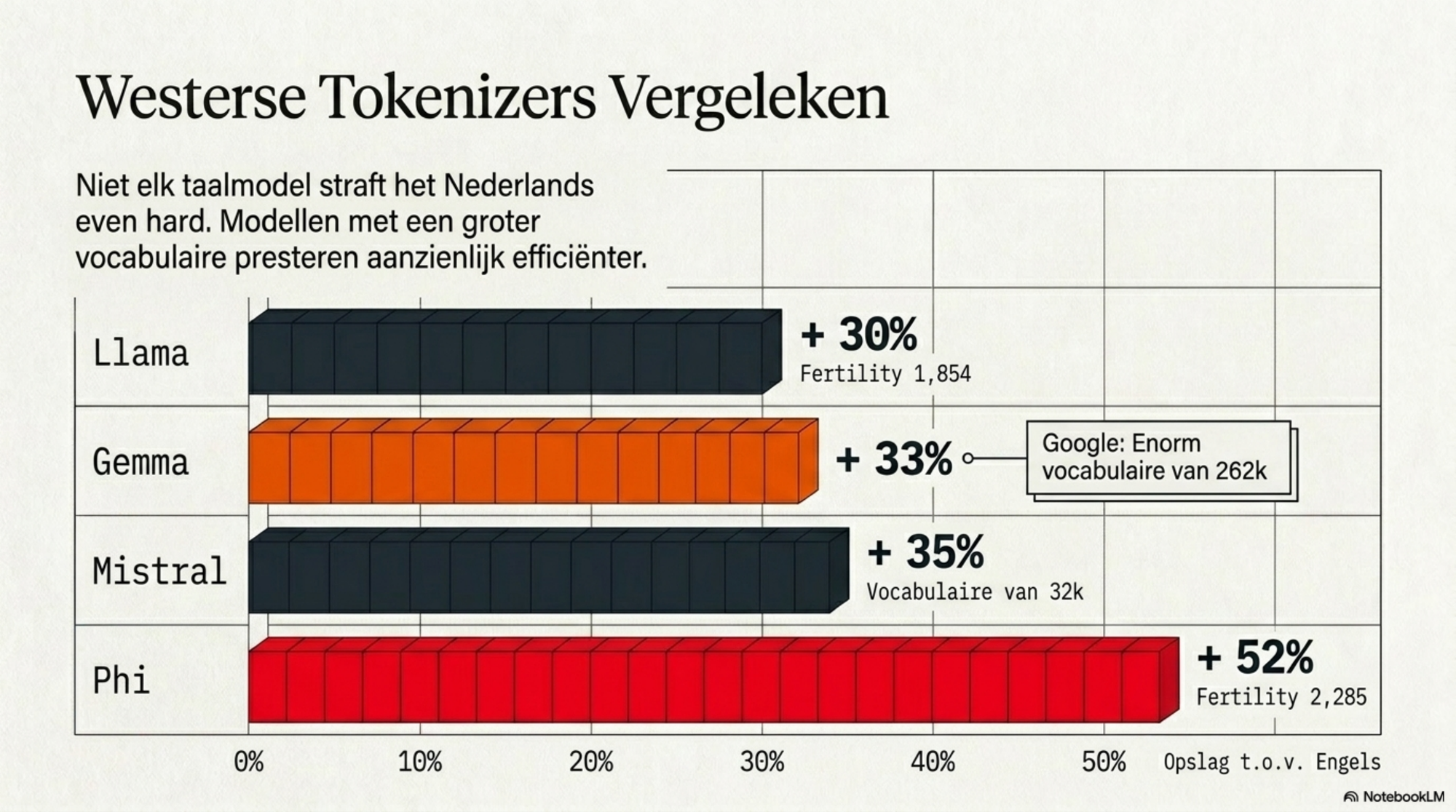
Voor Nederlands zijn de gemeten waarden:
| Tokenizer | Fertility | Opslag t.o.v. Engels |
|---|---|---|
| Mistral | 1,924 | +35% |
| Llama | 1,854 | +30% |
| Phi | 2,285 | +52% |
| Gemma (Google) | 1,703 | +33% |
Nederlands kost bij de meeste tokenizers structureel 30–35% meer tokens dan Engels voor dezelfde hoeveelheid inhoud. Bij Phi loopt dat op tot 52%.
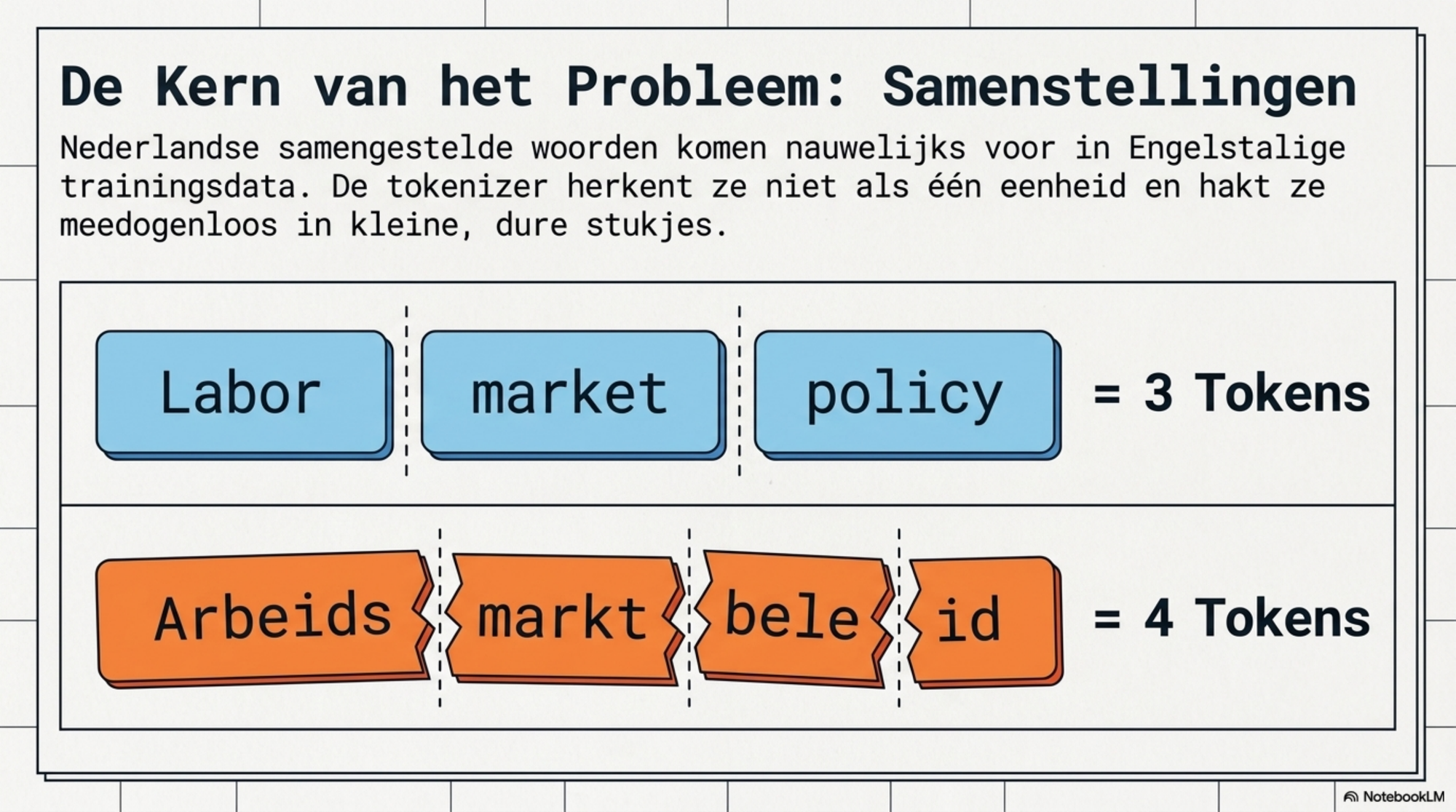
Waarom Nederlands relatief duur is
Nederlandse samengestelde woorden zijn de kern van het probleem. Een tokenizer leert welke tekenreeksen zo frequent zijn dat ze als één eenheid worden opgeslagen. "Arbeidsmarktbeleid", "informatiebeveiliging", "gegevensverwerkingsovereenkomst" — dit zijn woorden die in de overwegend Engelstalige trainingsdata van grote modellen nauwelijks voorkomen. De tokenizer heeft er geen samengesteld token voor en kapt ze op in meerdere stukken.
Dat is niet iets wat je kunt oplossen door anders te formuleren. Het zit in de structuur van de taal. Nederlands is morfologisch rijker dan Engels: meer samenstellingen, meer verbuigingen, langere woorden per semantische eenheid. Elke taalinherent woord dat de tokenizer niet herkent, betaal je als meerdere losse tokens.
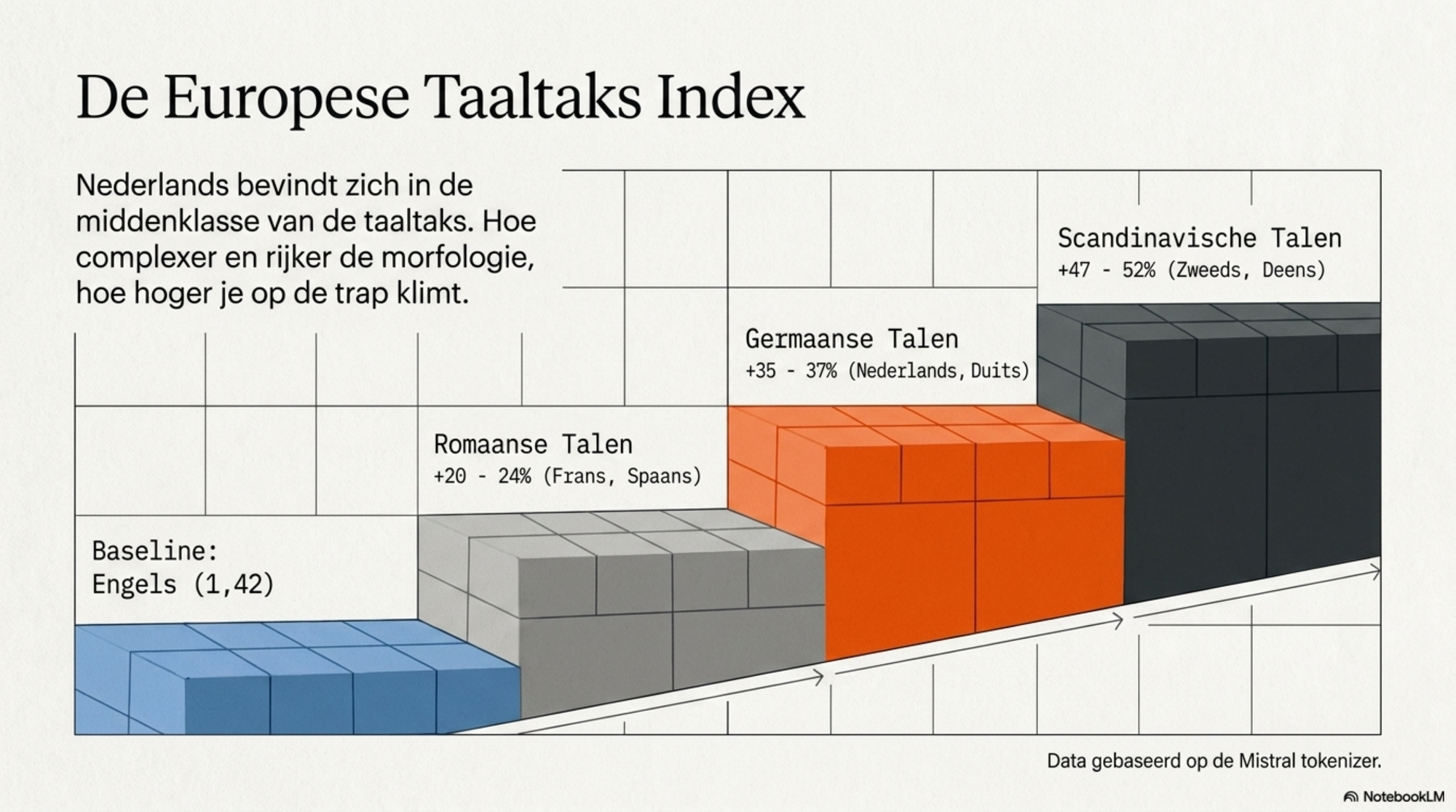
De vergelijking met andere Europese talen laat zien dat Nederlands in de middenklasse zit — beter dan de Scandinavische talen, slechter dan de Romaanse:
| Taal | Fertility (Mistral) | Opslag t.o.v. Engels |
|---|---|---|
| Engels | 1,42 | — |
| Frans | 1,70 | +20% |
| Spaans | 1,76 | +24% |
| Nederlands | 1,92 | +35% |
| Duits | 1,95 | +37% |
| Deens | 2,16 | +52% |
| Zweeds | 2,09 | +47% |
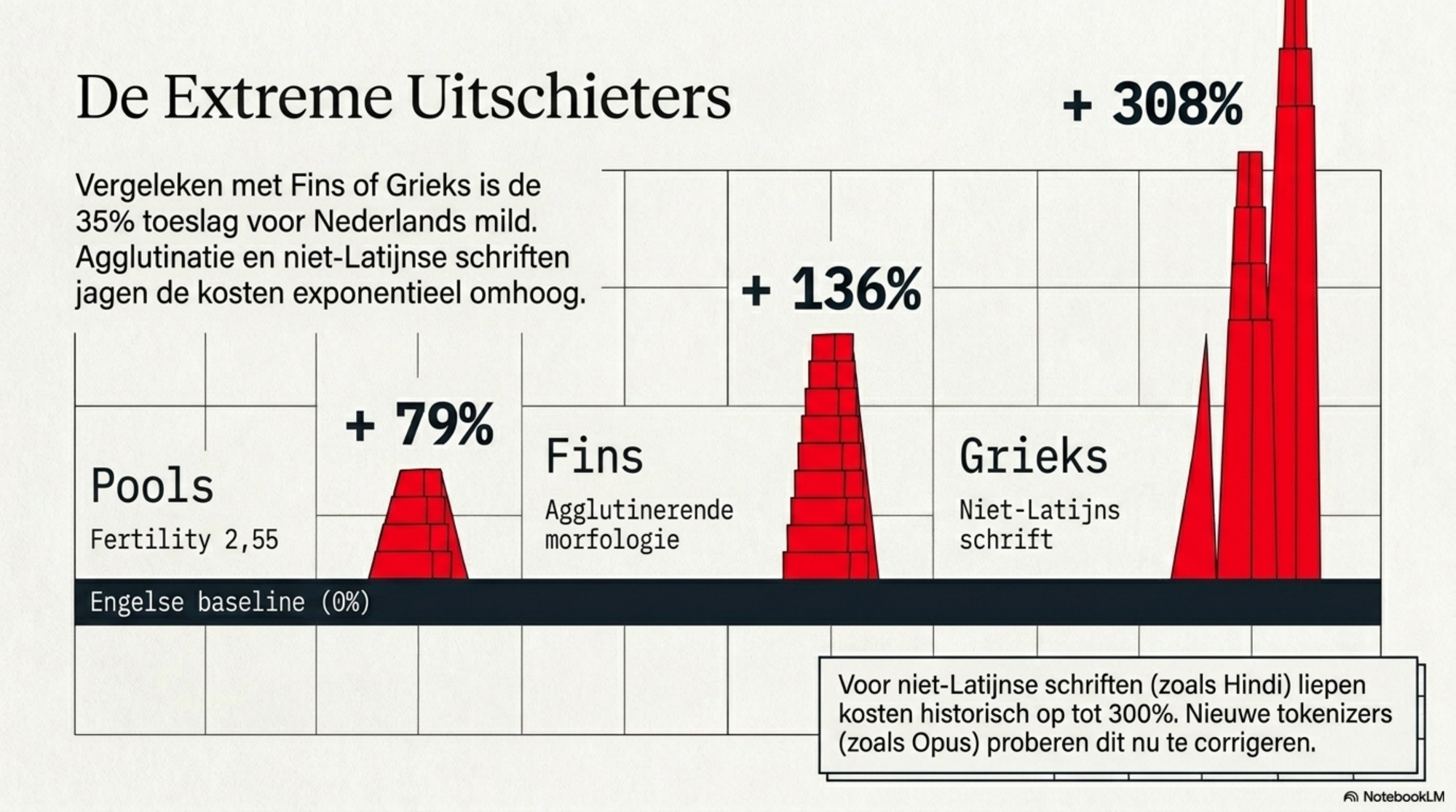
| Pools | 2,55 | +79% |
| Fins | 3,35 | +136% |
| Grieks | 5,80 | +308% |
Grieks, met zijn niet-Latijnse schrift, betaalt meer dan drie keer zoveel tokens als Engels voor dezelfde inhoud. Fins, met zijn agglutinerende morfologie, betaalt 136% meer. Vergeleken daarmee lijkt 35% voor Nederlands mild. Maar mild is niet gratis.
En dan is Europa nog het bevoordeelde continent. Hindi — met zijn Devanagari-schrift — was in eerdere versies van de grote westerse tokenizers extreem duur: metingen uit 2024 wezen op fertility-waarden tot drie keer die van Engels bij de Claude 3-tokenizer, die slechts 65.000 vocabulaire-items bevatte tegenover OpenAI's 100.000. Voor Indiase gebruikers was AI op de API structureel een andere rekening dan voor westerse gebruikers. De nieuwe tokenizer van Anthropic's Opus 4.7 zou dat gedeeltelijk corrigeren — er zijn aanwijzingen dat niet-Latijnse scripts (Arabisch, Hindi, Mandarijn, Japans, Koreaans) goedkoper worden met de vernieuwde tokenizer. Onafhankelijke metingen op dit punt ontbreken nog.
Een omgekeerde wereld: Chinese tokenizers
Tot nu toe heb ik het gehad over westerse tokenizers — OpenAI, Anthropic, Google, Mistral — en de taaltaks die zij opleggen aan niet-Engelstalige gebruikers. Maar er is een andere kant van hetzelfde fenomeen die het verhaal completer maakt.
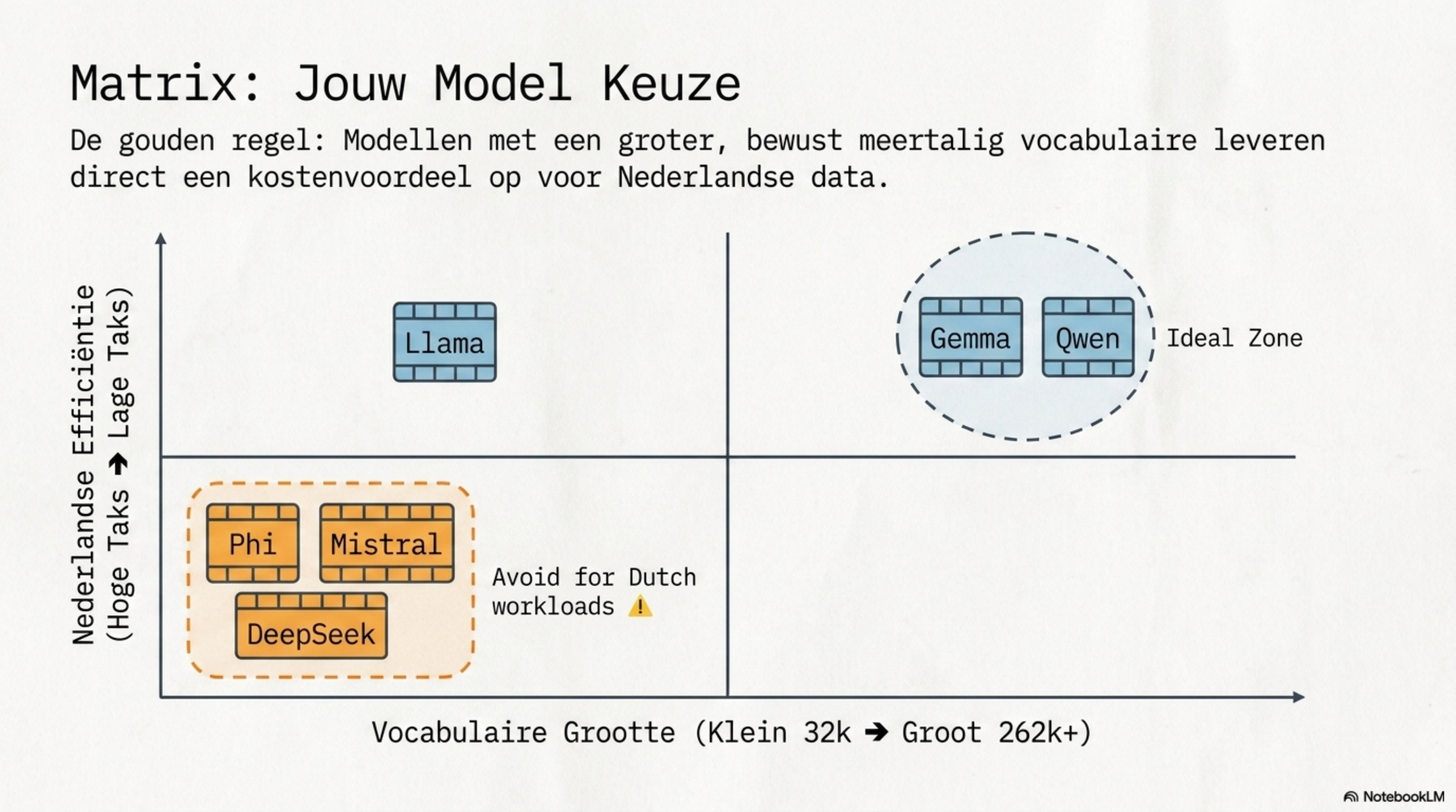
Hier is het belangrijk onderscheid te maken binnen de Chinese labs. Alibaba's Qwen en DeepSeek worden vaak in één adem genoemd, maar hun tokenizers zijn fundamenteel anders van opzet. Qwen heeft gekozen voor een zeer groot vocabulaire — vergelijkbaar met Google's aanpak — en heeft dat vocabulaire bewust meertalig ingericht. Het resultaat is dat Qwen-modellen niet alleen Chinees efficiënt verwerken, maar ook Europese talen relatief goed doen. Voor een Nederlandse gebruiker die Qwen via de API gebruikt, is de taaltaks aanzienlijk lager dan bij Mistral of de oudere Claude-tokenizer.
DeepSeek is een ander verhaal. Ondanks zijn Chinese oorsprong is de DeepSeek-tokenizer sterk Engels-georiënteerd. Praktijkmetingen laten zien dat Arabische tekst bij Qwen zo'n 68% meer tokens kost dan Engels — maar bij DeepSeek loopt dat op tot meer dan 340%. Voor Nederlands geldt een vergelijkbaar patroon: DeepSeek biedt geen voordeel ten opzichte van westerse tokenizers; Qwen wel.
Mandarijn zelf zit in een bijzondere positie. Het logografische schrift zonder expliciete woordgrenzen is juist duur in westerse tokenizers — niet vanwege morfologische rijkdom zoals bij Fins, maar vanwege de manier waarop BPE omgaat met karaktergebaseerde schriften. Tegelijkertijd laat onderzoek naar interne redeneerprocessen iets onverwachts zien: DeepSeek en Qwen redeneren intern efficiënter als ze in het Chinees denken. Modellen die worden gevraagd om in het Chinees te redeneren — ook al is de vraag in het Engels gesteld — gebruiken 20–40% minder tokens. Qwen3 behaalt zelfs 73% tokenreductie bij Koreaans. Die efficiëntie is ingebakken in hoe de tokenizer die taal heeft opgeslagen.
Wat dit geheel laat zien: de taaltaks is geen absolute maatstaf, maar een relatieve. Elke tokenizer heeft zijn eigen voorkeursgebied. Engels is de thuisbasis van de westerse labs. Qwen heeft bewust gekozen voor brede meertaligheid. DeepSeek is ondanks zijn Chinese herkomst op dit punt meer westers dan Qwen. Wie in de thuistaal van zijn aanbieder werkt, betaalt minder. Wie dat niet doet, betaalt de taks.

Wat het kost in de praktijk
Laat me het concreet maken.
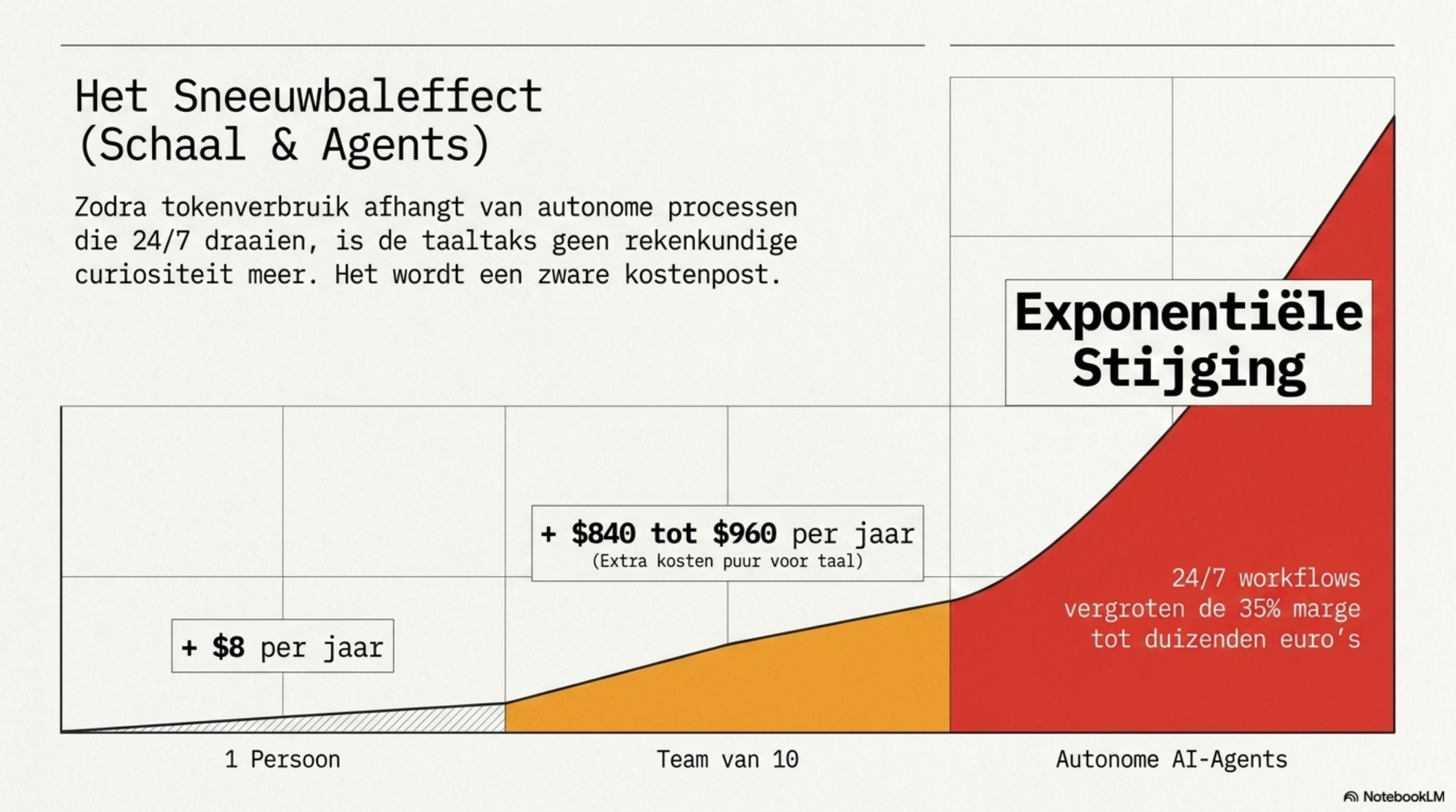
Een Nederlandse kenniswerker die Claude Sonnet 4.6 gebruikt via de API betaalt $3 per miljoen input tokens. Stel dat hij dagelijks 50.000 tokens verwerkt — een redelijk getal voor iemand die AI intensief inzet voor schrijven, analyse en research. Op maandbasis is dat 1 miljoen tokens: een API-rekening van $3.
Zijn Engelstalige concurrent verwerkt met dezelfde inhoud, in het Engels, ruwweg 30–35% minder tokens. Zijn rekening voor dezelfde hoeveelheid werk: $2,20–$2,30.
Het verschil per maand: $0,70–$0,80. Lijkt klein. Schaal het op: een team van tien Nederlandse kenniswerkers betaalt per jaar $840–$960 meer dan een equivalent Engels team — voor exact hetzelfde werk, dezelfde kwaliteit, dezelfde modellen. Niet wegens hogere prijzen. Wegens hogere tokentellingen.
Dat is de taaltaks in euro's. Niet dramatisch per individu. Maar structureel, onzichtbaar en cumulatief — en groeiend naarmate AI-gebruik intensiveert.

Voor organisaties die AI-agents inzetten — waarbij tokenverbruik niet meer afhangt van menselijke invoer maar van autonome processen die continu draaien — lopen deze bedragen significant op. En dan is de taaltaks niet meer een rekenkundige curiositeit maar een kostenpost die meetelt in de businesscase.
Wat betekent de taaltaks voor jou

De taaltaks is technisch verklaarbaar. Tokenizers zijn niet gebouwd om oneerlijk te zijn — ze zijn gebouwd op de data die beschikbaar was. Bij de westerse labs was dat overwegend Engels. Bij de Chinese labs ligt dat genuanceerder: Qwen kiest bewust voor een breed meertalig vocabulaire dat ook Europese talen ten goede komt, terwijl DeepSeek ondanks zijn Chinese herkomst sterk Engels-georiënteerd blijft. Dat zijn ontwerpkeuzes, geen kwade opzet.
Maar de uitkomst is wel dat de taal die je gebruikt een zelfstandige kostenvariabele is. Niet alleen het model dat je kiest, niet alleen het aantal woorden dat je schrijft — ook de taal zelf bepaalt mee wat je betaalt. Dat is dezelfde logica als de vorige blog: de ene token is de andere niet, en de ene aanbieder hanteert een andere definitie van zijn rekeneenheid. De taal die je schrijft voegt daar een derde dimensie aan toe. Bewustzijn daarvan is het begin.
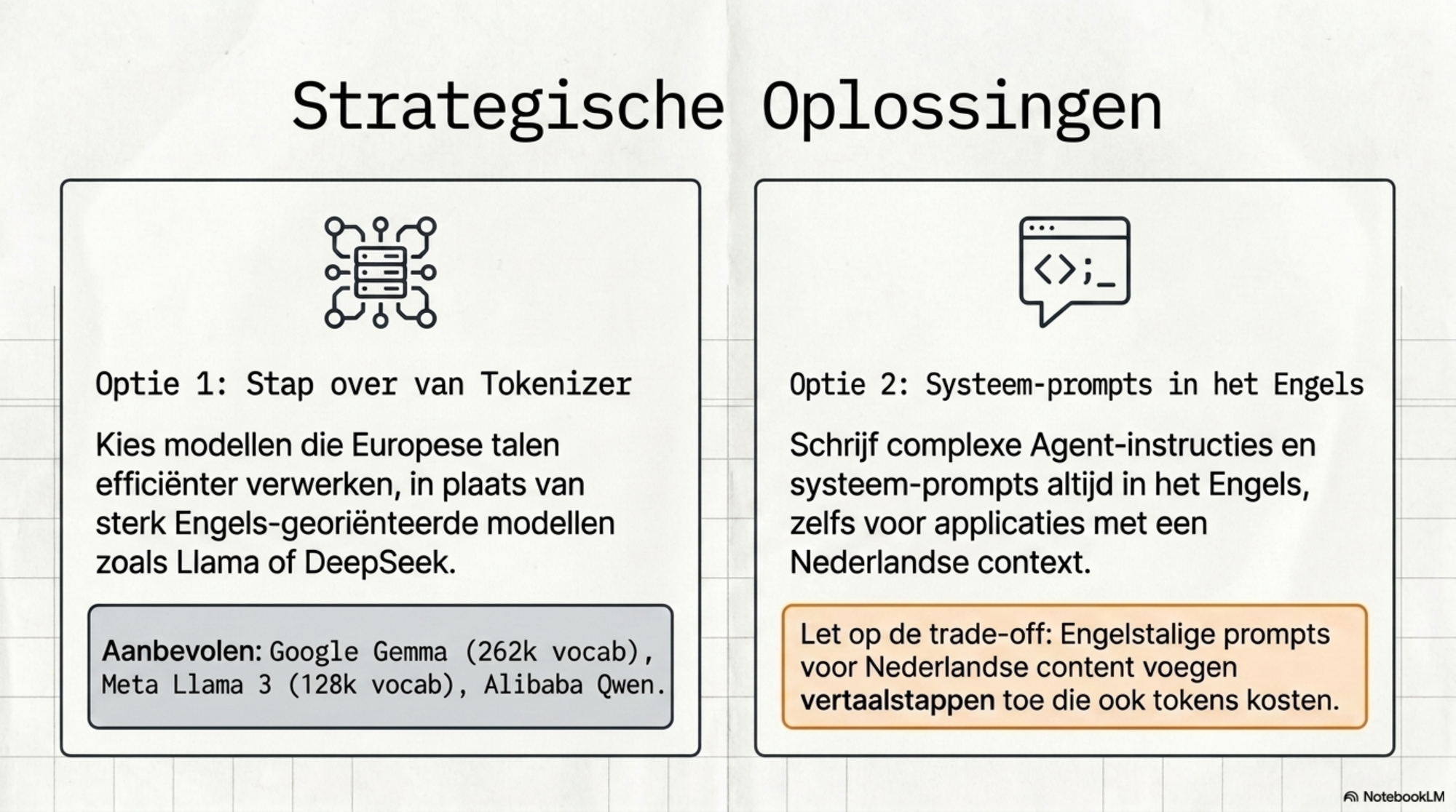
Keuze van model en aanbieder. De taaltaks verschilt per tokenizer. Google's Gemma-aanpak met 262k vocabulaire doet het voor Europese talen beter dan Mistral of Llama met 32k. Qwen scoort ook relatief goed voor Nederlands — beter dan DeepSeek, dat op dit punt dicht bij de westerse tokenizers blijft. Wie Nederlands als primaire werktaal heeft, heeft er belang bij te weten welke aanbieder efficiënter tokeniseert, en die keuze mee te nemen in platformbeslissingen.
Taalstrategie. Sommige organisaties kiezen er bewust voor om AI-prompts en agent-instructies in het Engels te schrijven, ook al is de rest van hun werk in het Nederlands. Het is het meest directe antwoord op de taaltaks. Het heeft ook een keerzijde: Engelstalige prompts voor Nederlandstalige content voegen een extra vertaalstap toe die zijn eigen tokens kost. De optimale strategie hangt af van het concrete gebruik — maar het is een afweging die het waard is om bewust te maken.
De meter tikt. In het Nederlands wat harder dan in het Engels.
Deze blog maakt deel uit van een bredere reeks over AI als systeemverschuiving — van de economie van tokens tot de versnelling van de technologie en wat dat betekent voor mensen en organisaties. De technische kant van AI in de praktijk beschrijft Edwin van Dillen. De bredere gedachten over organisatie, intentie en uitvoering zijn uitgewerkt op augmentedorganisation.nl, intentdriven.nl en augmentedengineering.nl.
De tokenreeks — eerder verschenen
Tokens op de meter — 23 maart 2026 Sam Altman beschreef het businessmodel openlijk: intelligentie wordt een nutsvoorziening, afgerekend per token. Deze blog introduceert de token als rekeneenheid, beschrijft de verslavingsfase waarin AI-bedrijven nu zitten — goedkoop om afhankelijkheid te bouwen — en legt uit waarom de uitgestelde rekening reëel is. Tokenefficiëntie is al nu een strategische vaardigheid.
De tokeneconomie — 24 maart 2026 Alibaba richtte de Alibaba Token Hub op: een formele business unit met de missie "tokens creëren, distribueren en toepassen." Drie lagen — foundational modellen, API-distributie, agentic platforms — vormen een verticaal geïntegreerd ecosysteem. Opmerkelijk: de tokeneconomie benoemt zichzelf, terwijl eerdere technologiegolven pas achteraf werden benoemd.
De token als meetlat — 27 maart 2026 Naar aanleiding van een WSJ-artikel: vier lenzen waarop bedrijven tokenverbruik meten — als factuur (Zapier), als prestatiemeting (Meta, Shopify), als statussymbool (tokenmaxxing bij OpenAI en Anthropic intern), en als waarde-signaal (Vercel, Kumo AI). Centrale conclusie: tokenefficiëntie is een proxy voor denkkwaliteit, niet voor technische vaardigheid.
SAP wordt tokenreseller — 28 maart 2026 SAP-CEO Christian Klein kondigde het einde van het abonnementsmodel aan. Als AI-agents de taken van tien medewerkers overnemen, heb je tien keer zo weinig seats nodig. SAP's "AI Units" zijn onder de motorkap tokens ingekocht bij Anthropic, OpenAI en anderen — SAP is in essentie een tokenreseller geworden. Systemen commoditiseren; menselijk vermogen blijft de onvervangbare differentiator.
De meter die lastig is te lezen — 7 april 2026 Drie betalingswerelden: de transparante API-wereld, de verpakte abonnementswereld (Claude Pro, ChatGPT Plus), en de geabstraheerde enterprise-wereld (M365 Copilot, GitHub Copilot). Kernconclusie: abonnementen zijn voor de gemiddelde gebruiker 3× tot 14× duurder per token dan directe API-toegang. In de enterprise wrapper-wereld ontbreekt de prikkel tot tokenefficiëntie structureel.
Tokenafhankelijkheid — april 2026 Via de Black Mirror-aflevering Common People en het concept enshittification: hoe Anthropic in zes stappen laat zien hoe de uitgestelde rekening stap voor stap wordt gepresenteerd — van piekuur-throttling en afsluiting van third-party tools, via enterprise van flat fee naar seat plus verbruik en een nieuwe tokenizer bij Opus 4.7, tot het stilletjes verwijderen van Claude Code uit het Pro-abonnement en drie afzonderlijke incidenten waarbij het model onbedoeld slechter ging presteren. Drie van de zes stappen zijn teruggedraaid; de richting is onveranderd. Agentic AI verdiept de afhankelijkheid structureel. Tokenefficiëntie als bewuste keuze, niet als bezuiniging.
De tokenizer als verborgen variabele — april 2026 Een token bij OpenAI is niet hetzelfde als een token bij Anthropic. En een token bij Anthropic 4.6 is niet hetzelfde als bij 4.7. Vergelijking van alle grote labs: OpenAI (tiktoken, open source, 100k→200k vocabulaire), Google (SentencePiece/Unigram, 262k), xAI (SentencePiece + byte-fallback, 131k), Anthropic (proprietary, ongedocumenteerd), Microsoft (geen eigen tokenizer, leent van modelpartners). De stickerprice is geen eerlijke vergelijkingsmaatstaf.
Co-creatie: Dit stuk is gemaakt samen met Claude (Anthropic) en NotebookLM (Google). De gedachten, posities en interpretaties zijn van mij.