De Chinese AI Labs

Waarom de goedkoopste intelligentie uit China komt — en wat dat betekent
Dit is de tiende blog in mijn reeks over de tokeneconomie. Eerdere delen onderaan deze pagina met korte samenvatting.
De vorige blog eindigde met een ongemakkelijke conclusie: frontier-intelligentie wordt schaarser, duurder en minder vanzelfsprekend. De subsidie-fase loopt ten einde. De rekening komt.
Dat klopt. Maar het is niet het volledige verhaal.
Want terwijl Anthropic en OpenAI hun prijzen ophogen, hun enterprise-contracten herstructureren en hun toegang stratificeren, beweegt er iets in de tegengestelde richting. Al moet daar direct bij gezegd: Anthropic draaide op 6 mei 2026 een deel van die stratificatie terug — limieten verdubbeld, piekuurbeperkingen opgeheven — mede aangejaagd door precies de krachten die deze blog beschrijft. Dat zegt iets. Bijna-equivalente intelligentie daalt structureel in prijs — en ligt al een factor vijf tot tien onder de westerse frontier-labs. En die beweging komt niet uit San Francisco.
Ze komt uit Hangzhou, Beijing en Shanghai.

Op 24 april 2026 lanceerde DeepSeek V4 — het meest verwachte Chinese AI-model van het jaar. De standaard API-prijs van V4-Pro is $3,48 per miljoen output tokens. Ter vergelijking: Claude Opus 4.7 kost $25 per miljoen output tokens, GPT-5.5 kost $30. Dat is al een factor zeven à negen goedkoper. Maar bij de lancering voegde DeepSeek daar een promotiekorting van 75% aan toe, verlengd tot 31 mei 2026, waarmee de output-prijs zakt naar $0,87 per miljoen tokens. Het meest opvallende aan de lancering was echter niet de prijs op dag één. Het was wat DeepSeek erbij aankondigde: de standaardprijs gaat verder omlaag. Zodra Huawei's Ascend 950-chips in de tweede helft van 2026 op schaal worden geleverd, verwacht DeepSeek een "significante verdere daling" van de V4-Pro prijs. De tokenprijs is daarmee expliciet gekoppeld aan de opbouw van Chinese chip-infrastructuur — een signaal dat dit geen tijdelijke marketingactie is, maar een structurele koersbepaling.
Wat er in de achterkamer al is besloten
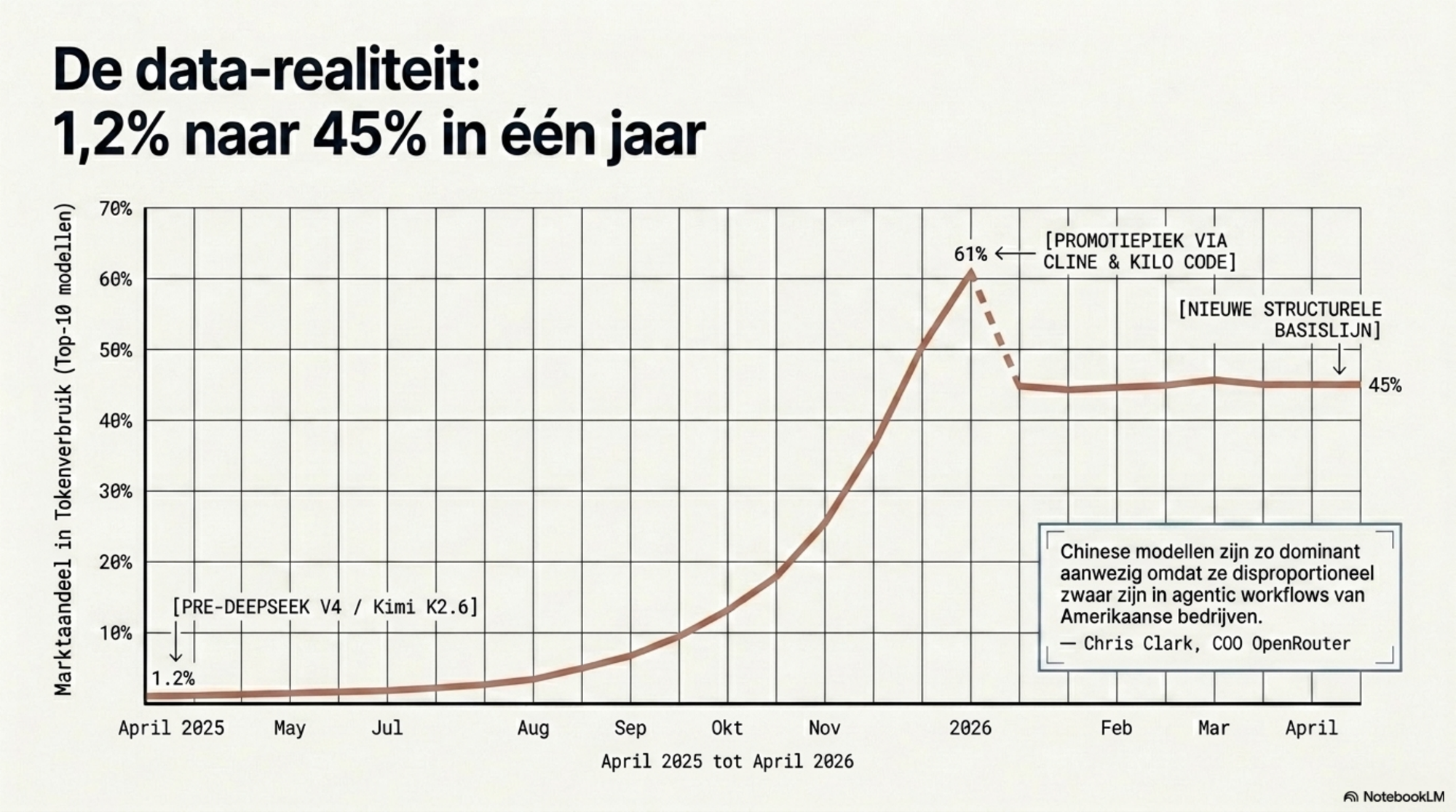
Begin februari 2026 publiceerde OpenRouter — het grootste aggregatieplatform voor AI-modellen, met toegang tot meer dan 400 modellen van meer dan 60 aanbieders — een opvallend gegeven. In de week van 24 februari vertegenwoordigden Chinese modellen 61% van het tokenverbruik bij de top-10 modellen op het platform. Drie Chinese modellen stonden tegelijk in de top drie. Voor het eerst stond er geen Amerikaans model in de bovenste positie.
Dat piekgetal verdient context. Een deel van de sprong werd veroorzaakt doordat developer-tools zoals Kilo Code en Cline het Chinese model MiniMax M2.5 die week gratis aanboden, wat het tokenvolume tijdelijk opblies. En OpenRouter bedient primair developers en startups, niet de grote enterprise-markt. Wie alleen naar die week kijkt, overschat de verschuiving. Wie de trend over een langere periode bekijkt, onderschat hem.
Want het jaar ervoor was het marktaandeel van Chinese modellen op OpenRouter 1,2%. In april 2026 is het structureel boven de 45%. Dat is geen uitschietende piek — dat is een marktherstructurering die zich in twaalf maanden heeft voltrokken.
Wat die overgang drijft is niet een bijzondere doorbraak in kwaliteit. Het is het prijsverschil — en de specifieke plek waar dat prijsverschil het hardst aanslaat. OpenRouter COO Chris Clark formuleerde het nuchter: Chinese modellen zijn zo dominant aanwezig omdat ze "disproportioneel zwaar zijn in agentic workflows van Amerikaanse bedrijven." Niet in de chatinterface die consumenten zien. In de automatiseringslaag die bedrijven bouwen achter hun producten.
Dat onderscheid is cruciaal. Consumentengebruik van AI draait nog steeds grotendeels op ChatGPT en Gemini. Maar API-gebruik — dat agentic workflows, codeergeneratoren en batchverwerking meet — vertelt een ander verhaal. Een partner bij Andreessen Horowitz schatte dat 80% van de Amerikaanse startups die open-source AI-stacks gebruiken, Chinese basismodellen inzet voor afgeleide ontwikkeling.
De overgang naar Chinese modellen is geen toekomstscenario. Hij is gaande, in de developer- en startuplaag, grotendeels onzichtbaar voor compliance-afdelingen en beleidsmakers.
Vijf labs, één beweging
Om te begrijpen wat er speelt, is het noodzakelijk de spelers te kennen. Het Chinese AI-landschap is geen monoliet. Er zijn vijf serieuze labs die elk een eigen positie innemen.
DeepSeek is de meest bekende naam buiten China — het lab dat in januari 2025 de wereld wakker schudde met R1, een redeneermodel dat OpenAI's o1 evenaarde voor een fractie van de prijs. DeepSeek opereert als een uitloper van het hedgefonds High-Flyer Capital Management uit Hangzhou. Dat is relevant: het lab heeft geen druk om snel winstgevend te worden en geen VC die bij elk kwartaal op de deur klopt. DeepSeek publiceert gedetailleerde technische rapporten, geeft de modelgewichten vrij onder MIT-licentie, en heeft van prijsdruk zijn expliciete strategie gemaakt. In april 2026 verscheen V4: twee varianten, V4-Pro (1,6 biljoen parameters) en V4-Flash (284 miljard parameters), beide met een contextvenster van één miljoen tokens.
Alibaba / Qwen is in omvang de grootste speler. De Qwen-familie heeft in maart 2026 de grens van één miljard downloads op Hugging Face gepasseerd, sneller dan enig ander open-source modelproject in de geschiedenis. In april 2026 verscheen de Qwen 3.6-familie, waaronder een variant die draait op slechts 3 miljard actieve parameters van een totaal van 35 miljard — smal genoeg om te draaien op een laptop met 22 gigabyte werkgeheugen.
Moonshot AI / Kimi is de verrassing van 2026. Het Beijing-gebaseerde lab, gewaardeerd op 18 miljard dollar, bracht in april Kimi K2.6 uit: een open-weight model van 1 biljoen parameters met 32 miljard actief per token en een "Swarm 2.0"-architectuur die tot 300 autonome sub-agents tegelijk kan coördineren. Kimi positioneert zich expliciet in agentic workflows en bracht het eerste open-weight model dat GPT-5.4 overtrof op SWE-Bench Pro — met 58,6% tegenover GPT-5.4's 57,7%. Claude Opus 4.7 leidt dat benchmark nog steeds met 64,3%.
Zhipu AI / GLM is het minst bekende lab buiten China maar misschien het meest strategisch interessante. GLM-5.1, uitgebracht in april 2026, is het eerste frontier-klasse model dat volledig is getraind op Huawei Ascend-chips — zonder één Nvidia GPU. Dat maakt het geopolitiek uniek: dit is Chinese AI-autonomie als bewezen feit, niet als ambitie.
StepFun / Step richt zich op specifieke capaciteiten. Step 3.5 Flash biedt wiskundige redeneervaardigheden vergelijkbaar met GPT-4o voor $0,10 per miljoen input tokens — 25 keer goedkoper dan zijn Amerikaans equivalent.
Vijf labs, verschillende posities, maar één gedeelde beweging: agressieve prijsstelling gecombineerd met open-weight beschikbaarheid als standaard.

Hoe goed zijn ze werkelijk?
De eerlijke samenvatting: DeepSeek claimt zelf zo'n 3 tot 6 maanden achter te lopen op de absolute state-of-the-art van westerse gesloten modellen. Op de Artificial Analysis Intelligence Index — een samengestelde score over tien evaluaties — scoort GPT-5.5 een 60, Claude Opus 4.7 een 57, Gemini 3.1 Pro Preview een 57. DeepSeek V4 Pro scoort een 52, Kimi K2.6 een 54.
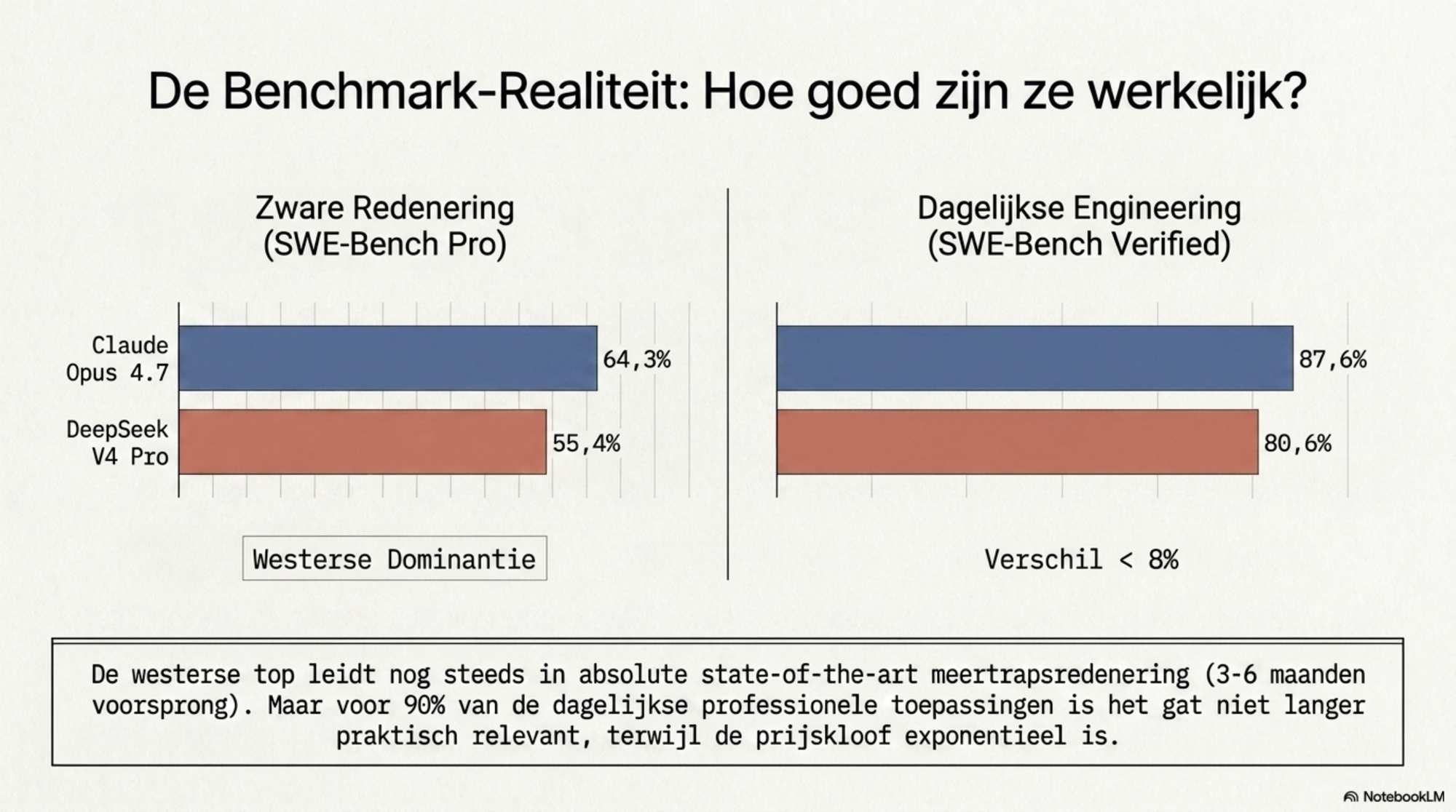
Dat gat is reëel. Op specifieke benchmarks die zwaar testen op feitelijke kennis, complexe meertrapsredenering en de moeilijkste wiskundige problemen, halen de westerse frontier-modellen de Chinese nog steeds. Op SWE-Bench Pro — het zwaarste coderingsbenchmark voor echte GitHub-problemen — leidt Claude Opus 4.7 met 64,3% tegenover 55,4% voor DeepSeek V4 Pro.
Maar op de benchmarks die de meeste dagelijkse bedrijfsprocessen weerspiegelen, is het verschil kleiner, hoewel meetbaar. Op SWE-Bench Verified scoort DeepSeek V4 Pro 80,6% tegenover 87,6% voor Claude Opus 4.7 — een verschil van 7 procentpunt. Op Terminal-Bench 2.0, dat autonome agentic uitvoering meet, scoort Opus 4.7 69,4% tegenover 67,9% voor V4 Pro — een klein maar reëel verschil ten gunste van Opus 4.7.
Het bredere patroon: op vrijwel alle gemeten benchmarks liggen de westerse frontier-modellen voor. De kloof is het grootst op zware redeneer- en kennistaken. Op codeertaken is het beeld genuanceerder: op LiveCodeBench leidt V4 Pro met 93,5% het gehele leaderboard — GPT-5.5 heeft geen gepubliceerde score op dit benchmark. Op Codeforces (competitief programmeren) bereikt V4 Pro een rating van 3.206, boven GPT-5.4's 3.168. Maar op SWE-Bench Pro en SWE-Bench Verified — de benchmarks die echte software-engineering taken meten — liggen de westerse modellen duidelijk voor. Het verschil is kleiner dan de prijskloof, maar het bestaat.
Een eerlijkheidskanttekening bij alle benchmarkcijfers in dit stuk is op zijn plaats. Objectieve vergelijkingen zijn moeilijk. Veel benchmarkscores zijn door de modellabs zelf gepubliceerd, zonder onafhankelijke verificatie. Sommige modellen zijn aantoonbaar specifiek getraind op bepaalde benchmarks, waardoor hoge scores weinig zeggen over echte prestaties. Bekende benchmarks zoals SWE-Bench Verified zijn door OpenAI zelf aangemerkt als gecontamineerd door trainingsdata-overlap. En de metingen worden niet altijd onder vergelijkbare omstandigheden uitgevoerd — verschillende tooling, verschillende harnessen, verschillende redeneerinstellingen kunnen scores met meerdere procentpunten verschuiven. De Intelligence Index van Artificial Analysis is een van de meer betrouwbare onafhankelijke bronnen omdat hij tien evaluaties combineert, maar ook die methodologie is niet onomstreden.
Wat je uit al deze data kunt herleiden — voorbij de individuele cijfers — is een consistent beeld: de Chinese frontier-modellen, en V4 Pro in het bijzonder, lopen nog achter op de westerse top, maar niet ver. Het gat is reëel en meetbaar, maar niet zo groot dat het voor de meeste professionele toepassingen praktisch relevant is. En het kost een fractie van de prijs.
De intelligentie-per-dollar-rekening
In de vorige blog introduceerde ik de lens van intelligentie per dollar als de juiste maatstaf voor strategische modelkeuze. Die lens geeft hier een ongemakkelijke uitkomst.
Neem de Intelligence Index-scores en leg er de outputprijzen naast:
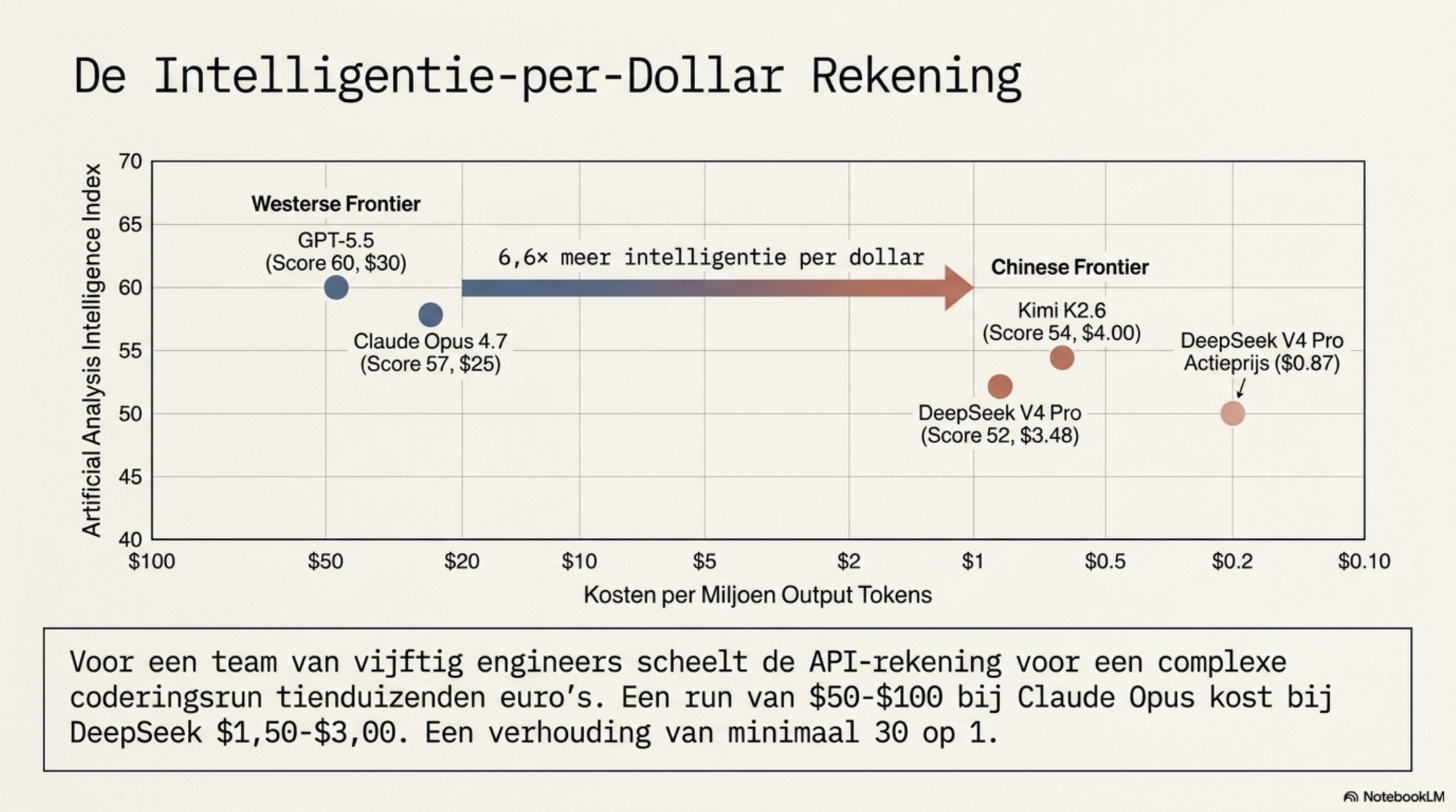
| Model | Intelligence Index | Output $/M (standaard) | Index per outputdollar (relatief) |
|---|---|---|---|
| Claude Opus 4.7 | 57 | $25 | 1× (baseline) |
| GPT-5.5 | 60 | $30 | 0,88× |
| DeepSeek V4 Pro | 52 | $3,48 | 6,6× |
| DeepSeek V4 Pro (actie t/m 31 mei) | 52 | $0,87 | 26× |
| Kimi K2.6 | 54 | $4,00 | 5,9× |
De actieregel verdient een kanttekening. De 75% korting op V4-Pro loopt tot 31 mei 2026 en is een tijdelijke promotie bij de lancering — geen structurele prijs. Voor een eerlijke strategische vergelijking is de standaardprijs van $3,48 de relevante basis. Die levert al 6,6× meer intelligentie per outputdollar dan Claude Opus 4.7. De actieprijs van $0,87 laat zien hoe ver de ondergrens kan liggen als DeepSeek dat wil — en geeft een indicatie van de richting waarin de structurele prijs zich beweegt naarmate de Huawei-infrastructuur goedkoper wordt.
Dat is geen marginaal verschil. Het is een structurele kloof.
Voor een codeerteam van vijftig engineers dat dagelijks AI-ondersteuning gebruikt, kan de keuze voor een Chinees model tegenover Claude Opus tienduizenden euro's per jaar schelen in de API-rekening. Een complexe coderingsrun kost bij Claude Opus 4-tarieven $50 tot $100. Via DeepSeek V4 Pro kost dezelfde run circa $1,50 tot $3. Een verhouding van 30 tot 50 op 1.
Dat is het type prijsverschil dat niet door compliance of voorkeur weerstaan kan worden als de kwaliteit voldoende is. En voor een groot deel van de dagelijkse werklast — alles buiten de absolute frontier-taken — is de kwaliteit voldoende.
Waarom zo goedkoop? Drie structurele oorzaken
Het prijsverschil is geen tijdelijk marketingfenomeen. Het heeft drie structurele wortels.
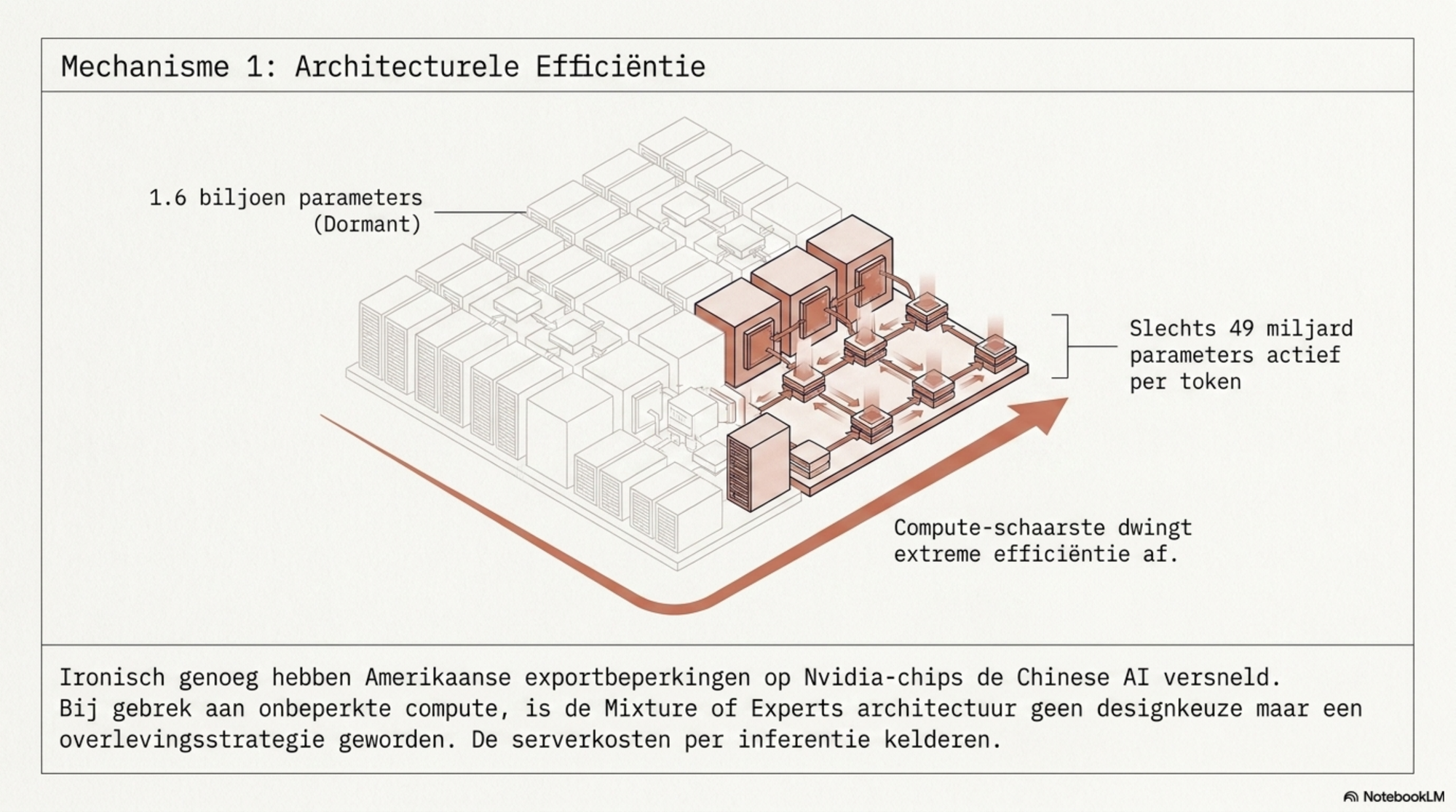
Architecturele efficiëntie door gedwongen schaarste. Ironisch genoeg hebben de Amerikaanse exportbeperkingen op Nvidia-chips de Chinese AI-ontwikkeling geholpen. Omdat Chinese labs niet konden bouwen met onbeperkte compute, moesten ze de computervraag per token drastisch reduceren. Mixture of Experts — de architectuur waarbij slechts een klein deel van de modelparameters per token actief is — is voor Chinese labs geen designkeuze maar een overlevingsstrategie geworden. Het resultaat is dat modellen als DeepSeek V4 Pro 1,6 biljoen parameters hebben maar per inferentie slechts 49 miljard activeren. Dat houdt de serverkosten laag bij een model dat qua capaciteit met de grote westerse labs concurreert.
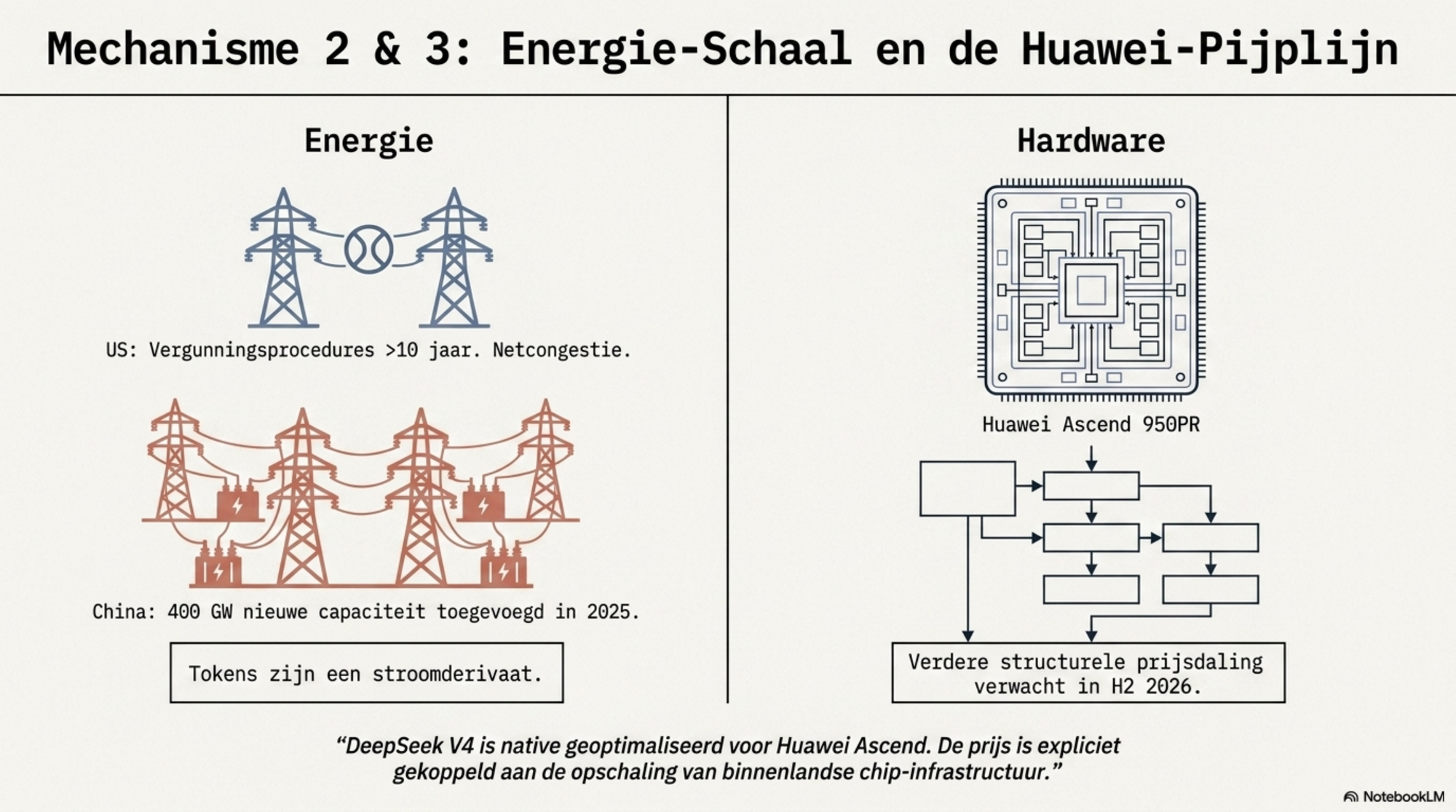
Energie als structureel voordeel. De gangbare aanname dat China enorm goedkopere stroom heeft, verdient nuancering. Elektriciteitskosten in China zijn vergelijkbaar met die in de VS — maar duidelijk lager dan in Europa. Het werkelijke voordeel zit elders. Terwijl de VS de afgelopen twee decennia nauwelijks groei had in stroomvraag, groeide China's elektriciteitsverbruik gemiddeld 8% per jaar, met nooit aflatende investeringen in capaciteit en netinfrastructuur. Amerikaanse AI-bedrijven kampen met netcongestie, vergunningstrajecten van meer dan tien jaar voor nieuwe centrales, en sterk gestegen wholesale-elektriciteitsprijzen in de buurt van grote datacenters. China heeft dat probleem niet.
Analisten schatten dat het trainen van één frontier-model in 2027 vijf gigawatt aan vermogen vereist — en dat de Amerikaanse AI-sector vóór 2028 50 gigawatt nieuwe capaciteit nodig heeft. China voegde in 2025 meer dan 400 gigawatt aan nieuwe capaciteit toe. De bottleneck bestaat in de VS; in China niet.
Chinese analisten formuleerden het treffend: energiekosten vormen 60 tot 70% van de operationele kosten van grote taalmodellen. Tokens zijn daarmee een soort stroomderivaat. En China exporteert zijn infrastructuurvoordeel niet als kilowattuur — maar als token.
De Huawei-factor en de dalende koers. DeepSeek V4 is het eerste frontier-klasse model dat native is geoptimaliseerd voor Huawei Ascend-chips — en het eerste waarbij de toekomstige prijs expliciet is gekoppeld aan de opschaling van binnenlandse chip-infrastructuur. Huawei kondigde bij de release "volledige ondersteuning" aan voor alle Ascend-supernodeclusters. DeepSeek zei dat de V4-Pro prijs "significant" kan dalen zodra Huawei's Ascend 950-supernodes in de tweede helft van 2026 op schaal worden geleverd. Huawei plant circa 750.000 units van de 950PR dit jaar te verschepen, met volledige productie in de tweede helft van 2026.
Dat is een reële aankondiging met een reële beperking. Amerikaanse exportcontroles op geavanceerde chipproductieapparatuur beperken Huawei's productievolume — de verwachting is dat de output onder de vraag blijft. De prijsdaling is dus niet gegarandeerd en ook niet ongelimiteerd. Maar de richting is duidelijk: DeepSeek heeft de standaardprijs van V4-Pro al structureel lager gezet dan de westerse frontier-labs, en geeft aan die koers voort te zetten naarmate de Huawei-infrastructuur groeit. Jensen Huang van Nvidia noemde de Huawei-optimalisatie van V4 "catastrofaal" voor de VS. De structurele implicatie is terecht: voor het eerst is er een Chinese AI-infrastructuurketen die onafhankelijk van Nvidia kan opereren, en die keten wordt nu actief gebouwd.
De tokenizer-wending: ook Chinese modellen hebben een taaltaks
Voor trouwe lezers van deze reeks is er een specifieke dimensie die niet onbesproken mag blijven.
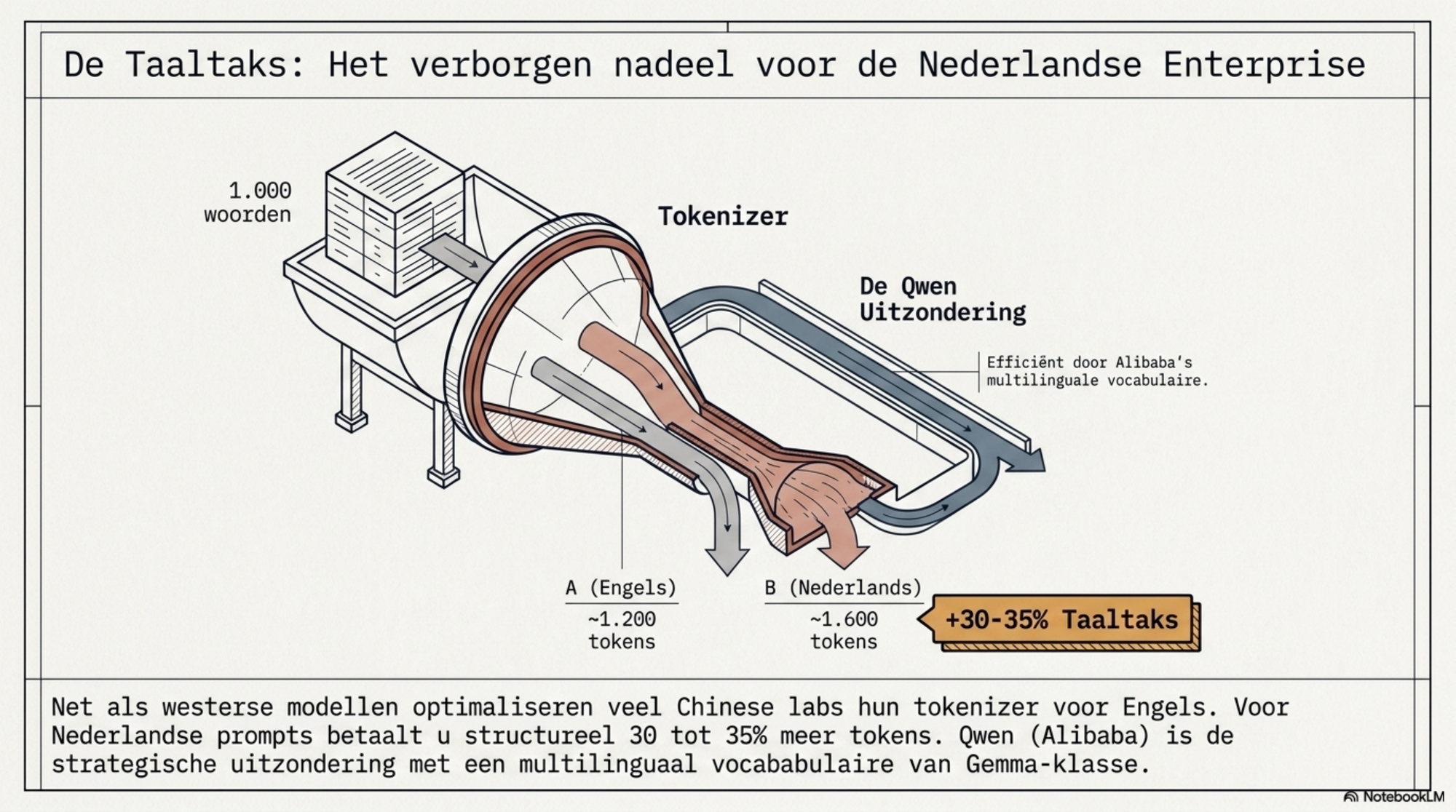
In blogs 7 en 8 analyseerde ik hoe de tokenizer bepaalt wat je werkelijk betaalt. De kernconclusie: aanbieders optimaliseren hun vocabulaire op de taal die het vaakst voorkwam in hun trainingsdata, en dat is overwegend Engels. Wie in het Nederlands werkt, betaalt structureel 30 tot 35% meer tokens voor dezelfde hoeveelheid inhoud.
Die conclusie geldt ook voor Chinese modellen — maar anders.
DeepSeek is geoptimaliseerd voor Chinees en Engels. Beide talen worden uitzonderlijk efficiënt verwerkt. Maar voor Arabische tekst vereist DeepSeek's tokenizer tot 340% meer tokens dan voor Engels — een van de extremere taaltaks-waarden in het veld. Voor Nederlands zijn de gemeten waarden vergelijkbaar met westerse tokenizers: ook hier betaalt de Nederlandstalige gebruiker de standaard 30 tot 35% toeslag.
Qwen is de uitzondering. Alibaba koos voor een vocabulaire van vergelijkbare omvang als Google's Gemma-tokenizer, met expliciete aandacht voor multilinguale dekking. Qwen doet het structureel beter voor Europese talen dan DeepSeek of de meeste westerse Llama-gebaseerde modellen. Voor een organisatie die primair in het Nederlands werkt en de overstap naar een Chinees model overweegt, is de tokenizer-keuze relevant: niet alle Chinese modellen zijn gelijk op dit punt.
Er is ook een ander fenomeen. Onderzoek naar redeneermodellen toont dat Chinese modellen intern soms redeneren in een andere taal dan de invoertaal. DeepSeek R1 gebruikt bij niet-Engelstalige vragen regelmatig Chinees in de denkketen. Dat levert 20 tot 40% minder tokens op in de redeneerlaag — maar alleen voor de talen die de tokenizer goed kent. Voor Nederlands geldt dat voordeel niet.
De les: wie een Chinees model kiest, verlegt de taaltaks niet — hij verplaatst hem naar een andere aanbieder met een deels andere tariefstructuur.
Waarom gaan we er dan niet massaal op over?
Dat is de juiste vraag. En het antwoord is: we gaan er al massaal op over — alleen niet daar waar het zichtbaar is.
Op OpenRouter — dat primair developers en startups bedient, niet de grote enterprise-markt — vertegenwoordigen Chinese modellen inmiddels structureel boven de 45% van het totale tokenverkeer. Een jaar geleden was dat onder de 2%. Piekweken met gratis promoties voor Chinese modellen via developer-tools trokken dat tijdelijk naar 61%; de structurele lijn na correctie voor die promoties ligt rond de 45 tot 50%. De stijging zit niet in de consumentenlaag — die blijft op ChatGPT en Gemini. Ze zit in de achterkamer: agentic workflows, codeerpijplijnen, batchverwerking, de automatiseringslagen die organisaties bouwen zonder dat de eindgebruiker ziet welk model er draait.
Drie remmen houden de volledige adoptie nog gedeeltelijk terug.
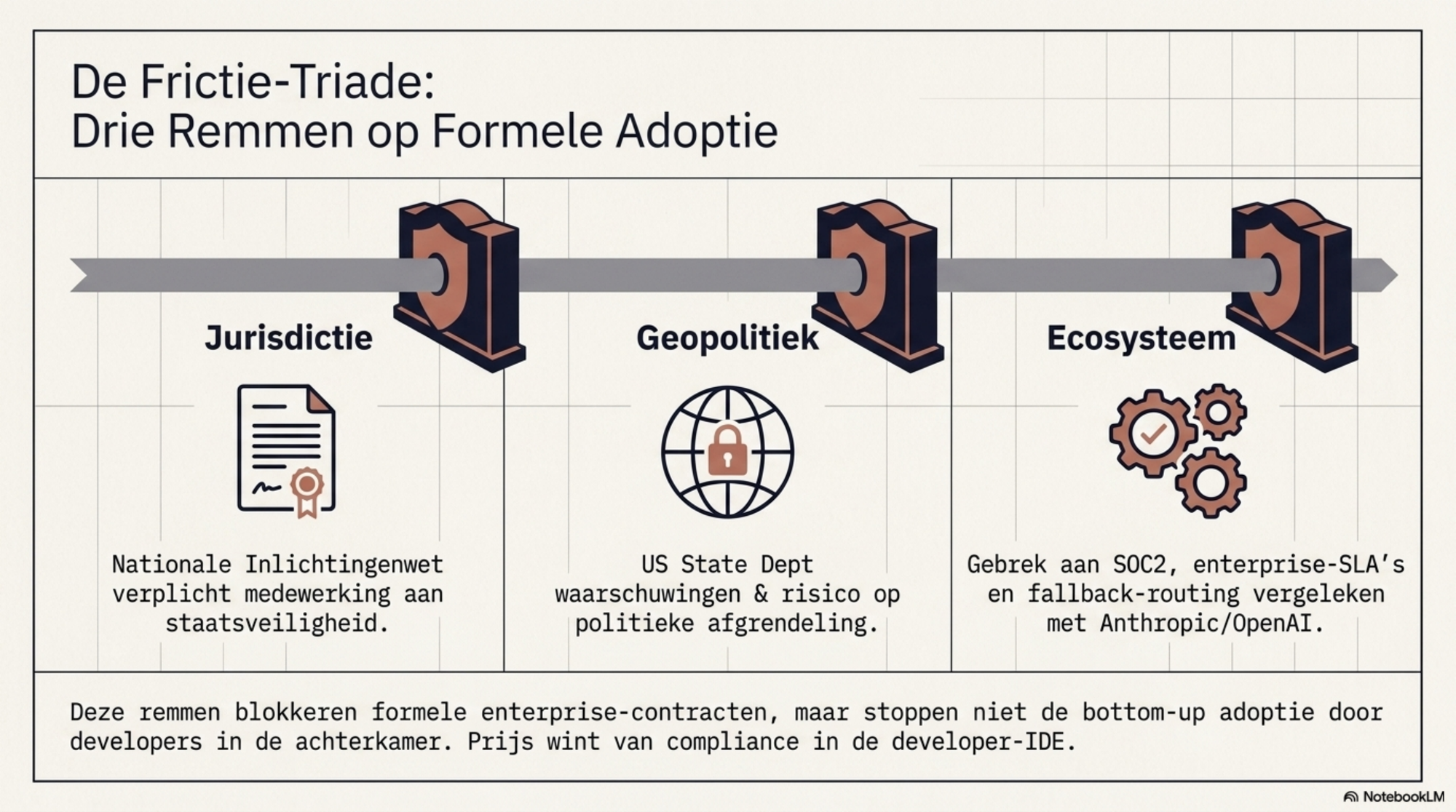
De eerste rem is dataprivacy en jurisdictie. Chinese labs zijn, ongeacht hun open-weight strategie, opgericht en gevestigd in China. Ze vallen onder de Chinese Nationale Inlichtingenwet, die verplicht tot samenwerking met nationale veiligheidsdiensten op verzoek. Dat is geen theoretisch risico — het is een juridische realiteit. Wie gevoelige bedrijfsinformatie, klantgegevens of strategische documenten door een Chinees model stuurt, plaatst die data in een jurisdictie met andere normen dan de AVG. Overheden in meerdere westerse landen hebben het institutionele gebruik van DeepSeek al verboden. De combinatie van open-weight beschikbaarheid en zelf-hosting reduceert dit risico, maar verplaatst het naar modelintegriteitsrisico's en onderhoudsverplichtingen.
De tweede rem is geopolitieke afhankelijkheid. Het Amerikaanse State Department stuurde in april 2026 een diplomatieke kabel naar ambassades wereldwijd met de opdracht buitenlandse regeringen te waarschuwen voor Chinese "extractie en destillatie" van westerse AI-modellen. De kabel noemt DeepSeek, Moonshot AI en MiniMax met naam. Anthropic beschuldigde drie Chinese labs eerder van het overspoelen van zijn Claude-model via 24.000 frauduleuze accounts. Of die beschuldigingen volledig standhouden of niet — ze geven aan dat de relatie tussen westerse frontier-labs en hun Chinese concurrenten gespannen is. Wie vandaag zijn bedrijfsprocessen bouwt op Chinese modellen, bouwt een afhankelijkheid waarvan de toegang morgen politiek kan worden afgegrendeld.
De derde rem is ecosysteem en rijpheid. Claude beschikt over jaren van productie-inzet, uitgebreide compliance-documentatie, SOC 2-certificering, en diep geïntegreerde tooling in Cursor, Windsurf en Claude Code. DeepSeek heeft een sterkere API-compatibiliteit dan de meeste alternatieven — V4 spreekt zowel het OpenAI- als het Anthropic-API-formaat — maar het ecosysteem rondom monitoring, fallback-routing, enterprise-SLA's en gedetailleerde auditrapporten is dunner.
Dat zijn drie reële remmen. Maar ze gelden primair voor de formele, zichtbare adoptie. In de achterkamer, op het niveau van de developer die een modelbeslissing neemt, wint het prijsargument het al.
Het prijsverschil is onhoudbaar
Er zijn prijsverschillen die door regulering in stand worden gehouden. En er zijn prijsverschillen die zo groot zijn dat ze zichzelf oplossen — door marktkrachten, door druk van concurrenten, of door de eenvoudige calculatie van budgethouders.
Een verhouding van 30 tot 50 op 1 bij vergelijkbare kwaliteit valt in de tweede categorie.
De westerse frontier-labs zijn niet blind voor dit gegeven. OpenAI prijst zijn Codex-lijn lager dan zijn flagship-modellen. Anthropic differentieert agressief tussen Haiku, Sonnet en Opus. Maar de bovenste laag — de frontier-modellen die het meest worden gebruikt voor complexe taken — blijft geprijsd op een niveau dat de Chinese concurrenten structureel onderbieden.
De westerse labs houden die prijs hoog om twee redenen. Ten eerste omdat de kapitaalkosten voor training en infrastructuur enorm zijn — Anthropic sloot deals voor in totaal circa 10 gigawatt aan bevestigde compute-capaciteit (5 GW bij Amazon, 5 GW bij Google), met een aanvullende 3,5 gigawatt via Google en Broadcom voor 2027. Een industrieel-strategische inzet die zijn equivalent in tokenprijzen moet terugverdienen. Ten tweede omdat de subsidie-fase nog niet voorbij is: de adoptie-investering wordt nog verdedigd, de dominante positie in enterprise bewaard met contractuele lock-in.
De compute-schaarste is intussen zo acuut dat Anthropic op 6 mei 2026 een deal sloot met SpaceX — dat eerder dit jaar xAI absorbeerde en eigenaar is van het Colossus 1-datacenter in Memphis. Musk had Anthropic eerder publiekelijk "misantropisch en kwaadaardig" genoemd. Toch: Anthropic krijgt nu toegang tot meer dan 220.000 NVIDIA GPU's en 300 megawatt, beschikbaar binnen een maand. Het directe gevolg: Claude Code-limieten werden verdubbeld voor alle betaalde abonnementen, piekuurbeperkingen werden opgeheven, en API-limieten stegen met tot 1.500% voor sommige tiers. Dat twee openlijke concurrenten samenwerken omdat de compute-schaarste zo reëel is, zegt meer over de toestand van de AI-infrastructuurmarkt dan welke persverklaring ook.
Maar de structurele druk neemt toe. Vanaf februari 2026 overtreffen Chinese modellen structureel de Amerikaanse in wekelijks tokenverbruik op het grootste developer-API-aggregatieplatform ter wereld. Dat is één segment van de markt — maar het is het segment waar de bouwers zitten, niet de consumenten. En bouwers bepalen de architectuurkeuzes van morgen.
De vraag voor de professionele lezer is niet of dit zijn organisatie zal raken. De vraag is wanneer — en of er dan al een positie is ingenomen.
Twee tegengestelde krachten
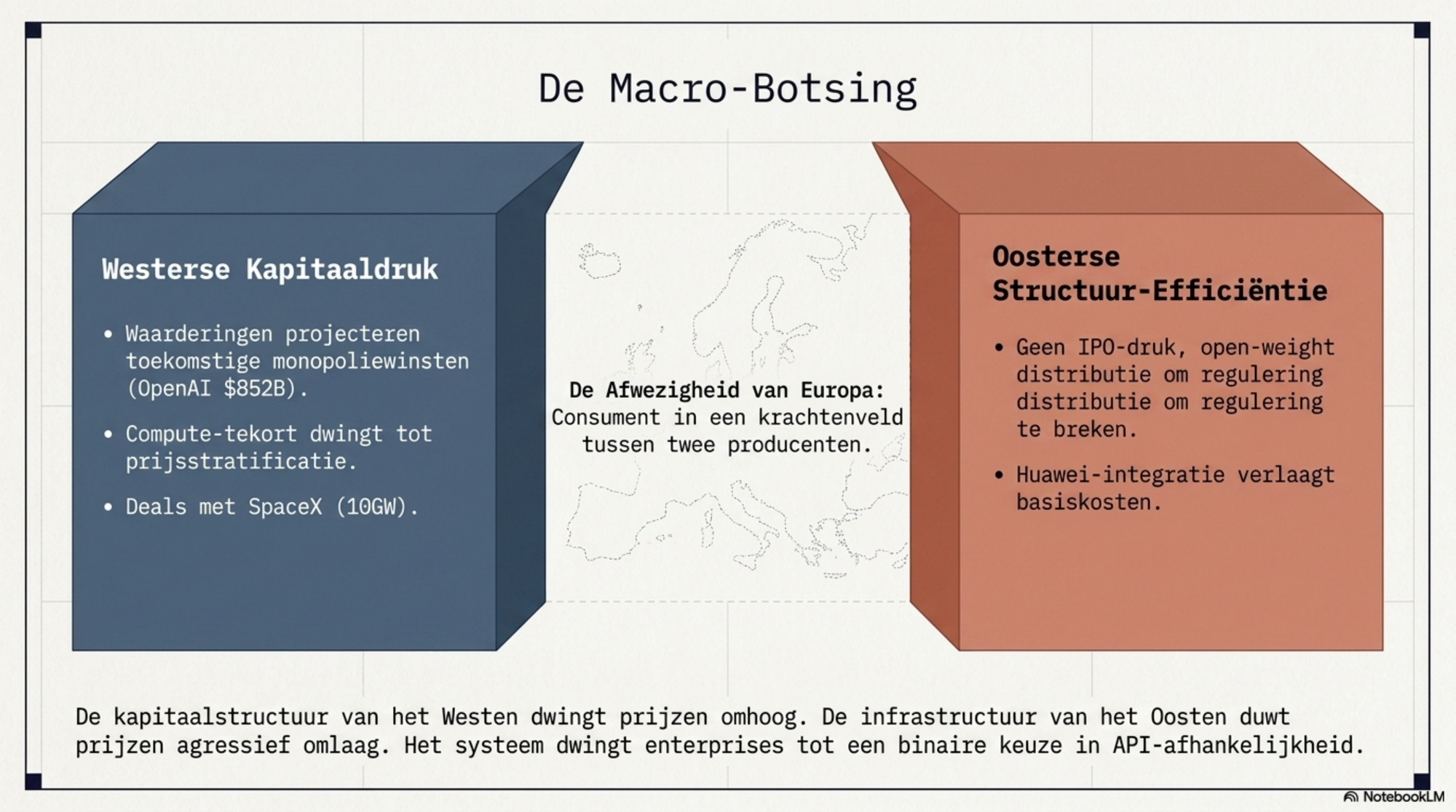
Zet de twee bewegingen naast elkaar, dan tekenen zich twee structurele krachten af die in tegengestelde richting duwen.
De eerste is die van de grote westerse labs. Anthropic sloot deals voor circa 10 gigawatt aan bevestigde compute-capaciteit, met verdere uitbreiding in de pijplijn. OpenAI wordt gewaardeerd op 852 miljard dollar. Die waarderingen zijn geen beschrijvingen van wat deze bedrijven nu verdienen — het zijn projecties van wat ze móeten gaan verdienen. De kapitaalstructuur dwingt richting hogere prijzen, stratificatie en het afknijpen van toegang voor wie niet genoeg betaalt. Compute is schaars, energie is schaars, de IPO nadert. De cognitieve stratificatie die ik in de vorige blog beschreef, is geen beleid — het is de uitkomst van de financiële bovenbouw.
De tweede kracht is die van de Chinese labs. Ze hebben structurele kostenvoordelen — efficiëntere architecturen, geen netbottleneck, een infrastructuur die verder wordt uitgebouwd op eigen chips. Ze geven hun modellen weg onder MIT-licentie. Ze prijzen agressief, en zullen goedkoper worden naarmate Huawei's Ascend-productie opschaalt. De prikkel om te stoppen bestaat niet. OpenRouter laat al zien wat developers doen als ze vrij kunnen kiezen: ze kiezen voor intelligentie per dollar, niet voor herkomst. Agents draaien waar het goedkoopst is. Dat is geen sentiment — dat is economie.
Wat de uitkomst van deze twee tegengestelde krachten is, weet ik niet. Dat zou een voorspelling zijn, en dit is een analyse. Wat ik wel zie, zijn de terugkoppelingen die al in gang zijn gezet. Westerse labs maken hun middensegment goedkoper als reactie op Chinese prijsdruk — Sonnet en GPT-4o-niveau zijn al fors gedaald. Een concreet voorbeeld: xAI lanceerde op 30 april 2026 Grok 4.3 met $1,25 input en $2,50 output per miljoen tokens — een verlaging van 40% op input en 60% op output ten opzichte van zijn voorganger, bewust gepositioneerd in de prijsklasse van Chinese open-weight modellen. Grok 4.3 scoort 53 op de AA Intelligence Index, direct naast DeepSeek V4 Pro (52) — en kost minder dan een tiende van Claude Opus 4.7. Geopolitieke maatregelen proberen de markt te segmenteren en Chinese modellen buiten bepaalde sectoren te houden. Chinese labs gaan juist open-weight om die segmentering te omzeilen. Het zijn geen statische posities. Het is een dynamisch systeem dat zichzelf blijft aanpassen.
Wat in dit geheel opvalt is de afwezigheid van Europa. Er is geen Europees frontier-lab dat meetelt. Er is geen Europese tokenizer, geen Europees open-weight ecosysteem van betekenis. Europa is consument in een krachtenveld tussen twee producenten. Dat heeft gevolgen voor datapositie, voor strategische autonomie, voor de vraag op wiens infrastructuur het Europese bedrijfsleven zijn cognitieve processen gaat draaien. De keuze is niet of Europa afhankelijk wordt — de vraag is van wie.
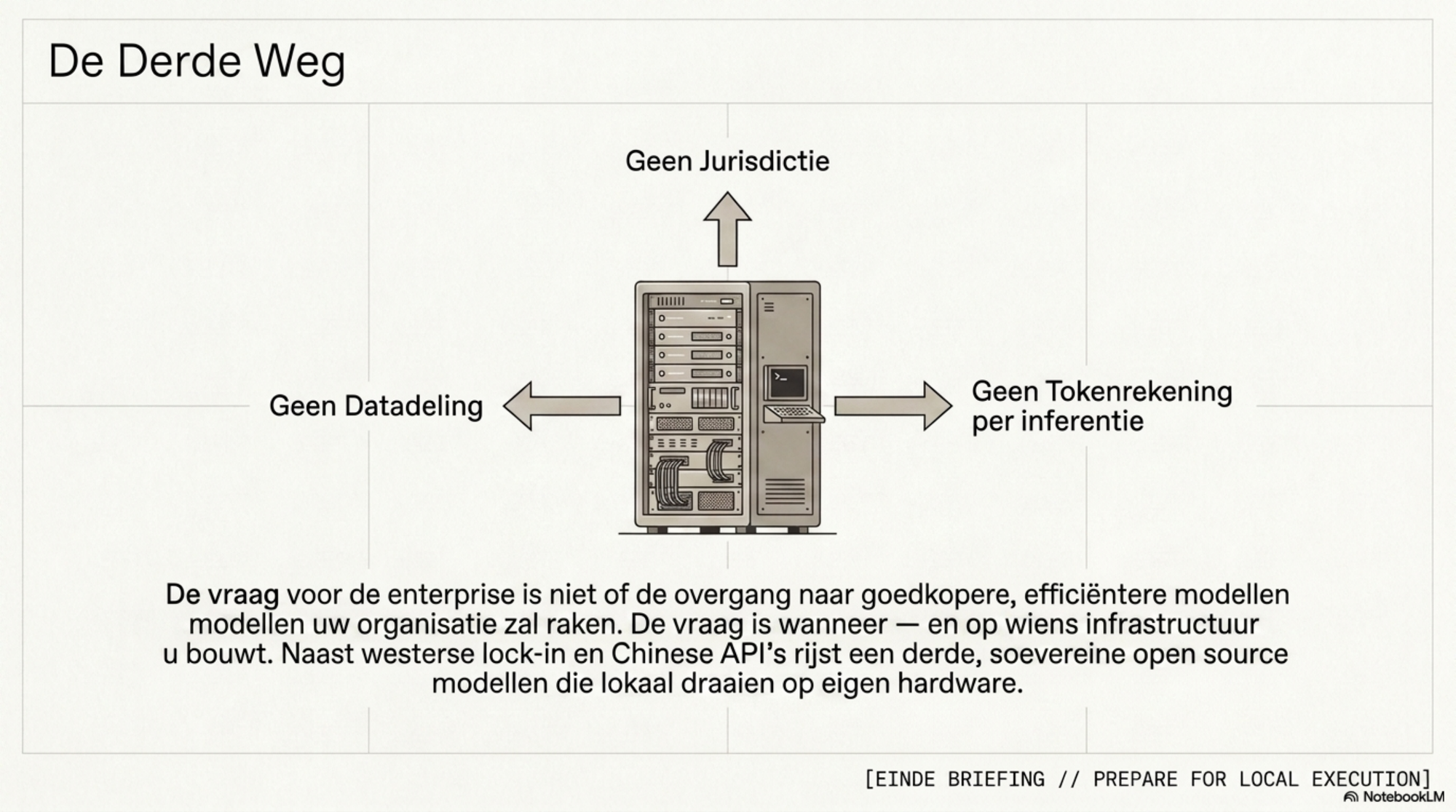
Maar er is een derde weg. Eén die in deze blog nog niet aan bod is gekomen.
Naast de westerse frontier-labs en de Chinese open-weight modellen bestaat er een derde optie: lokaal draaien. Open-source modellen die niet via een API worden aangeroepen maar op eigen hardware worden uitgevoerd — buiten iedere jurisdictie, zonder datadeling, zonder tokenrekening per inferentie. De intelligentie per dollar ziet er bij lokale modellen fundamenteel anders uit dan bij alle API-aanbieders die ik tot nu toe heb besproken. Hoeveel anders, en voor wie dat realistisch is — dat is de volgende blog.
Deze blog maakt deel uit van een bredere reeks over AI als systeemverschuiving — van de economie van tokens tot de versnelling van de technologie en wat dat betekent voor mensen en organisaties. De technische kant van AI in de praktijk beschrijft Edwin van Dillen. De bredere gedachten over organisatie, intentie en uitvoering zijn uitgewerkt op augmentedorganisation.nl, intentdriven.nl en augmentedengineering.nl.
De tokenreeks — eerder verschenen
Tokens op de meter — 23 maart 2026 Sam Altman beschreef het businessmodel openlijk: intelligentie wordt een nutsvoorziening, afgerekend per token. Deze blog introduceert de token als rekeneenheid, beschrijft de verslavingsfase waarin AI-bedrijven nu zitten — goedkoop om afhankelijkheid te bouwen — en legt uit waarom de uitgestelde rekening reëel is. Tokenefficiëntie is al nu een strategische vaardigheid.
De tokeneconomie — 24 maart 2026 Alibaba richtte de Alibaba Token Hub op: een formele business unit met de missie "tokens creëren, distribueren en toepassen." Drie lagen — foundational modellen, API-distributie, agentic platforms — vormen een verticaal geïntegreerd ecosysteem. Opmerkelijk: de tokeneconomie benoemt zichzelf, terwijl eerdere technologiegolven pas achteraf werden benoemd.
De token als meetlat — 27 maart 2026 Naar aanleiding van een WSJ-artikel: vier lenzen waarop bedrijven tokenverbruik meten — als factuur (Zapier), als prestatiemeting (Meta, Shopify), als statussymbool (tokenmaxxing bij OpenAI en Anthropic intern), en als waarde-signaal (Vercel, Kumo AI). Centrale conclusie: tokenefficiëntie is een proxy voor denkkwaliteit, niet voor technische vaardigheid.
SAP wordt tokenreseller — 28 maart 2026 SAP-CEO Christian Klein kondigde het einde van het abonnementsmodel aan. Als AI-agents de taken van tien medewerkers overnemen, heb je tien keer zo weinig seats nodig. SAP's "AI Units" zijn onder de motorkap tokens ingekocht bij Anthropic, OpenAI en anderen — SAP is in essentie een tokenreseller geworden. Systemen commoditiseren; menselijk vermogen blijft de onvervangbare differentiator.
De meter die lastig is te lezen — 7 april 2026 Drie betalingswerelden: de transparante API-wereld, de verpakte abonnementswereld (Claude Pro, ChatGPT Plus), en de geabstraheerde enterprise-wereld (M365 Copilot, GitHub Copilot). Kernconclusie: abonnementen zijn voor de gemiddelde gebruiker 3× tot 14× duurder per token dan directe API-toegang. In de enterprise wrapper-wereld ontbreekt de prikkel tot tokenefficiëntie structureel.
Tokenafhankelijkheid — april 2026 Via de Black Mirror-aflevering Common People en het concept enshittification: hoe Anthropic in vier stappen (piekuur-throttling, afsluiting third-party tools, enterprise van flat fee naar seat plus verbruik, nieuwe tokenizer bij 4.7) laat zien hoe de uitgestelde rekening stap voor stap wordt gepresenteerd. Agentic AI verdiept de afhankelijkheid structureel.
De tokenizer als verborgen variabele — april 2026 Een token bij OpenAI is niet hetzelfde als een token bij Anthropic. En een token bij Anthropic 4.6 is niet hetzelfde als bij 4.7. Vergelijking van alle grote labs: OpenAI (tiktoken, open source, 200k vocabulaire), Google (SentencePiece, 262k), xAI (SentencePiece + byte-fallback, 131k), Anthropic (proprietary, ongedocumenteerd), Microsoft (geen eigen tokenizer, leent van modelpartners). De stickerprice is geen eerlijke vergelijkingsmaatstaf.
De taaltaks — mei 2026 Er is een belasting die nergens op de factuur staat: de taaltaks. Tokenizers zijn getraind op overwegend Engelse data, waardoor Nederlands structureel 30–35% meer tokens verbruikt voor dezelfde inhoud. Bij Anthropic Opus 4.7 stapelen taaltaks en nieuwe tokenizer op: tot 90% meer tokens dan een Engelstalige developer op hetzelfde model. De meetlat was nooit neutraal.
De prijs van intelligentie — mei 2026 De huidige lage tokenprijs is geen marktprijs maar een strategische keuze: venture capital en hyperscalers betalen het verschil om afhankelijkheid te bouwen. Die subsidie-fase eindigt. Anthropic verschoof enterprise-klanten stilletjes naar gebruiksgebaseerde facturering. De markt beweegt naar cognitieve stratificatie in drie lagen: commodity-cognitie, enterprise frontier, en strategische AI — met toenemende afstand tussen elke laag.
Co-creatie: Dit stuk is gemaakt samen met Claude (Anthropic) en NotebookLM (Google). De gedachten, posities en interpretaties zijn van mij.