De teller staat stil

Over de opmars van lokale modellen en wat het toch betekent dat intelligentie geen meter meer kent

Dit is de elfde blog in mijn reeks over de tokeneconomie. Eerdere delen staan onderaan, met korte samenvatting.
Het startschot van het huidige AI-tijdperk klonk eind 2022 met de lancering van ChatGPT. Anthropic en Google volgden binnen enkele maanden met hun eigen producten, en de drie commerciële modellen verbeterden razendsnel — van GPT-3.5 naar GPT-5.5, van Claude 1 naar Claude Opus 4.7, van Bard naar Gemini 3.
Naast die commerciële modellen waren er vanaf het begin ook open modellen — GPT-J, BLOOM, LLaMA. Ze bestonden, ze waren downloadbaar, maar ze waren in 2023 geen serieus alternatief voor wie kwaliteit nodig had. De kloof in prestaties was te groot.
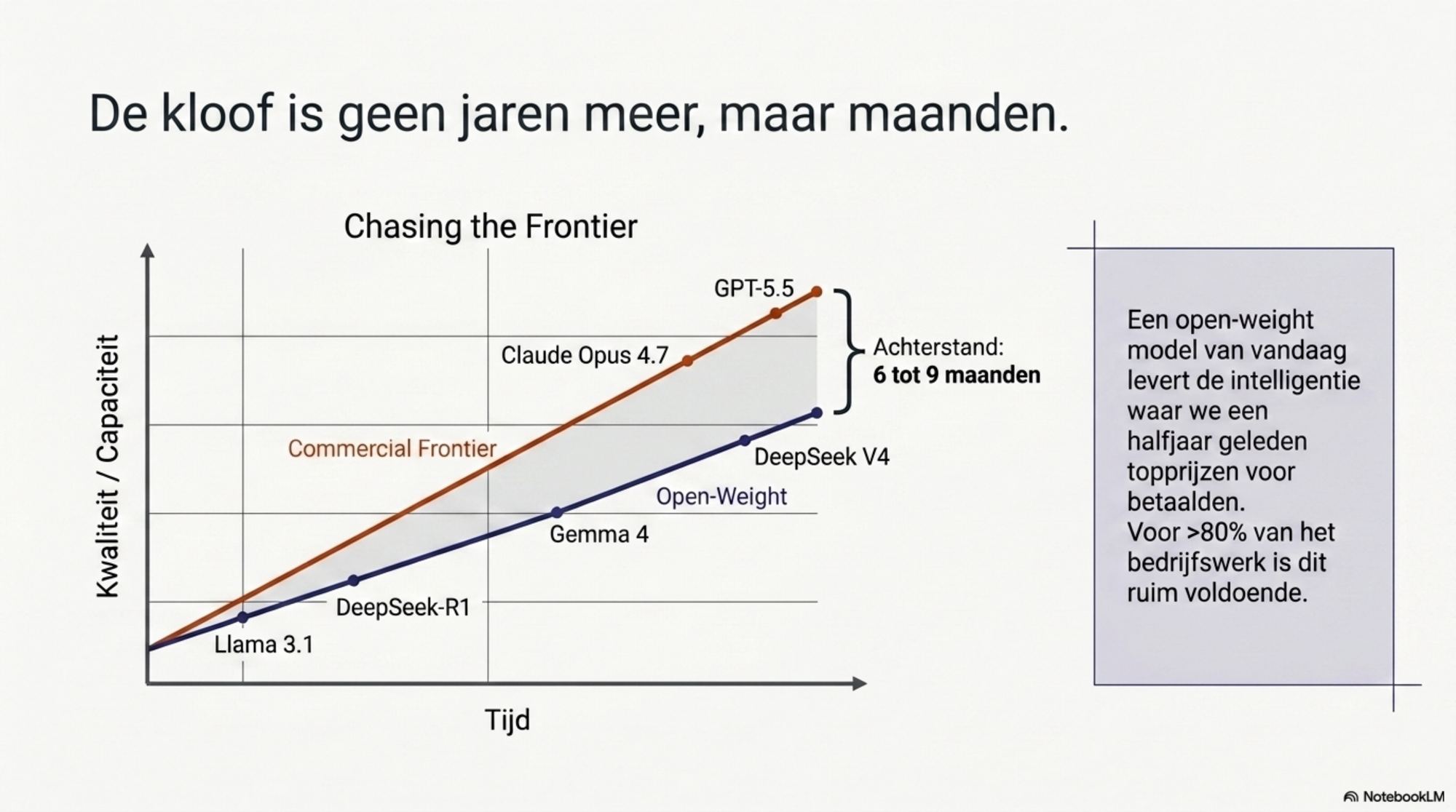
Vanaf 2024 begon dat patroon te kantelen. Meta's Llama 3, Google's Gemma, Alibaba's Qwen en vooral DeepSeek brachten de afstand tot de commerciële frontier maand na maand terug. De closed frontier-modellen lopen nog steeds voor — vooral op de moeilijkste taken, op alignment en op subtiele meerstaps-redenering. Maar de afstand is geen jaren meer; het is een kwestie van maanden. Een goed open-weight model van vandaag levert ongeveer wat de commerciële frontier zes tot negen maanden geleden bood. En daar betaalden organisaties op dat moment serieus geld voor. Voor een groot deel van het dagelijkse werk is dat ruim voldoende.
En vooral: lokale modellen tellen geen tokens. Bij lokale inferentie staat de teller stil. Dat is het structurele verschil met alles wat ik in deze reeks tot nu toe heb besproken. Geen tokenrekening per inferentie, geen abonnement, geen dataoverdracht naar een buitenlandse server. Wel: investering in hardware, tijd om in te regelen, en de eerlijke beperkingen die bij open modellen horen.
Een waarschuwing vooraf over getallen
Wie modellen vergelijkt in 2026, doet dat met asterisken. Benchmarks raken verzadigd, modellen worden er expliciet op getraind, en veel scores zijn self-reported zonder onafhankelijke verificatie — SWE-bench Verified, lang de standaard voor codering, is door OpenAI zelf gemarkeerd als gecontamineerd. De ELO-rating op Chatbot Arena geeft een breder beeld, maar deelt alleen zijn naam met het schaakratingsysteem; sinds eind 2023 gebruikt Arena het Bradley-Terry-model en meet het gebruikersvoorkeur, niet pure capaciteit.
Tegelijk komt uit het geheel van benchmarks, ELO-ratings en marktanalyses een consistente richting naar voren — de afstand tussen open-weight en commerciële frontier is gekrompen, en is in 2026 een kwestie van maanden, niet jaren. Dat is wat in deze blog telt. De derde decimaal is fictie; de richting is hard.
Hoe snel het is gegaan
De opmars van open-weight modellen is een van de snelste kwaliteitsverbeteringen die de AI-sector ooit zag — en tegelijk een goed voorbeeld waarom je niet moet uitgaan van een rechte inhaallijn.
De Stanford AI Index 2025 vatte de verkleining van de kloof bondig samen: de Arena-afstand tussen het beste open-weight en het beste closed model was gekrompen van ongeveer 8 procentpunt begin 2024 naar 1,7 procentpunt begin 2025. Dat haalde wereldwijd de voorpagina's. De Stanford AI Index 2026 voegde daar een ongemakkelijke voetnoot aan toe: in maart 2026 was die afstand weer opgelopen tot circa 3,3 procentpunt, en zes van de tien topmodellen op Arena waren weer gesloten. Het verkleinen van de kloof verloopt niet in een rechte lijn; het is een dynamisch evenwicht waarbij de ene partij voorbijspringt en de andere terugslaat.
Twee patronen zijn wel zichtbaar. Ten eerste: open-weight modellen volgen de commerciële frontier het dichtst op codering en wiskunde — taken met objectieve verificatie. Op brede redenering, kennisintegratie en complexe agentic workflows is de afstand structureel groter. Ten tweede: de Chinese inhaalslag is reëel. Eind 2023 lagen verschillen tussen Amerikaanse en Chinese modellen op brede benchmarks als MMLU en HumanEval nog tussen de 17 en 32 procentpunt; in 2024 was dat aanzienlijk kleiner geworden. De serieuze open-weight modellen anno mei 2026 komen uit drie regio's: de Verenigde Staten (Meta's Llama, Google's Gemma, Microsoft's Phi), China (Alibaba's Qwen, DeepSeek, Moonshot's Kimi, Zhipu's GLM) en Europa (Mistral). China heeft kwantitatief de meeste labs en de hoogste releasefrequentie.
Een paar ijkpunten illustreren de versnelling — niet als precieze ranglijst, maar als markers.
Llama 3.1 405B (Meta, juli 2024) was het eerste open-weight model dat aantoonbaar GPT-4-niveau bereikte op algemene taken. Het 405B-model alleen kostte ruim 30 miljoen GPU-uren op NVIDIA H100's. Landmark: open toegang tot frontier-kwaliteit.
Qwen 2.5 (Alibaba, najaar 2024) verving Llama als meest gebruikte basis voor fine-tuning wereldwijd. De 72B-variant kwam op brede benchmarks in de buurt van GPT-4-niveau en presteerde bovengemiddeld op niet-Engelstalige tekst.
DeepSeek-R1 (DeepSeek, januari 2025) werd het schokgolf-moment. DeepSeek publiceerde dat V3 — de basis voor R1 — voor circa $5,6 miljoen aan officiële trainingrun was getraind, en R1 zelf voor nog eens enkele honderdduizenden dollars. Deze cijfers gelden exclusief R&D, eerdere experimenten en de infrastructuur eromheen; semiconductor-onderzoeksbureau SemiAnalysis schatte de totale kosten, inclusief servers en GPU's, op meer dan een miljard dollar. Maar het kernpunt stond: frontier-redenering vereist niet per definitie miljarden voor één trainingsrun. Gewichten publiek beschikbaar onder MIT-licentie.
Gemma 4 (Google, voorjaar 2026) bracht frontier-niveau intelligentie in een uitzonderlijk compact formaat. De 26B MoE-variant activeert volgens Google's documentatie ongeveer 4 miljard parameters per token — waardoor hij presteert als een 27B maar draait als een 4B. De 31B Dense-variant staat in de top van de open-model ranglijst op Arena. Apache 2.0-licentie, meer dan 400 miljoen downloads over alle Gemma-generaties.
DeepSeek V4 (DeepSeek, april 2026) zette de volgende stap na R1. V4 Pro heeft circa 1,6 biljoen parameters totaal, waarvan in de orde van vijftig miljard actief per token dankzij Mixture-of-Experts — en ondersteunt standaard een miljoen tokens context. MIT-licentie. DeepSeek claimt dat V4 Pro de huidige commerciële frontier met enkele maanden achterloopt voor een fractie van de kosten; onafhankelijke verificatie is bij publicatie nog beperkt.
Het patroon door deze ijkpunten heen is consistent: open-weight modellen volgen de commerciële frontier met een achterstand die korter is geworden. Eind 2023 ging het nog om ruim een jaar; in mei 2026 schatten meerdere analyses (Epoch AI, Artificial Analysis) de achterstand op drie tot negen maanden, afhankelijk van benchmark en taak. Dat betekent niet dat open-weight de frontier heeft ingehaald. Het betekent dat een lokaal model van vandaag bij benadering geeft wat een commercieel frontier-model een halfjaar geleden bood — en dat is voor heel veel taken meer dan voldoende.
Een nuance over distillatie
Westerse media — en het Witte Huis in een memo van april 2026 — kaderden DeepSeek's succes vaak als bewijs dat de Chinese inhaalslag berustte op het kopiëren van Amerikaanse modellen. Distillatie staat in dat verhaal centraal: de techniek waarbij een nieuw model wordt getraind door antwoorden van een bestaand model als leersignaal te gebruiken.
Twee dingen zijn hier tegelijk waar en worden vaak door elkaar gehaald.
Ten eerste is distillatie zelf een legitieme en industriebrede techniek. Anthropic verwoordde het in februari 2026 in een eigen blogpost — een post waarin Anthropic overigens drie Chinese labs (DeepSeek, Moonshot en MiniMax) beschuldigde van ongeoorloofde distillatie van Claude — letterlijk zo: "Distillation is a widely used and legitimate training method. For example, frontier AI labs routinely distill their own models to create smaller, cheaper versions for their customers." Open-source projecten als Alpaca en Vicuna gebruikten openlijk GPT-4-outputs om hun modellen te verfijnen. De techniek zelf is niet het probleem.
Ten tweede wordt het juridisch grijs zodra een lab outputs van een directe concurrent gebruikt om een rivaliserend model te trainen. OpenAI's terms of service verbieden dat expliciet. En dit is niet exclusief een Chinees fenomeen. Op 30 april 2026 verklaarde Elon Musk in een federale rechtszaal onder ede dat xAI "deels" distillatie heeft toegepast op OpenAI-modellen om Grok te trainen — Musk noemde het zelf een industriestandaardpraktijk.
De Chinese inhaalslag kan dus niet worden weggewuifd als "ze hebben het toch maar gekopieerd". DeepSeek's innovaties op Mixture-of-Experts en trainingsefficiëntie zijn substantieel en onafhankelijk verifieerbaar. Distillatie speelt een rol — bij vrijwel alle moderne labs, in oost én west. De inhaalslag is echt, of de juridische framing ervan nu uitkomt of niet.
Hoe goed zijn ze écht?
Een eerlijke vergelijking vraagt om voorzichtigheid met de cijfers — scores zijn vaak self-reported, benchmarks gecontamineerd, en de ranglijst verandert per maand. Wat je wel kunt zien, is in welke categorie een model zit.
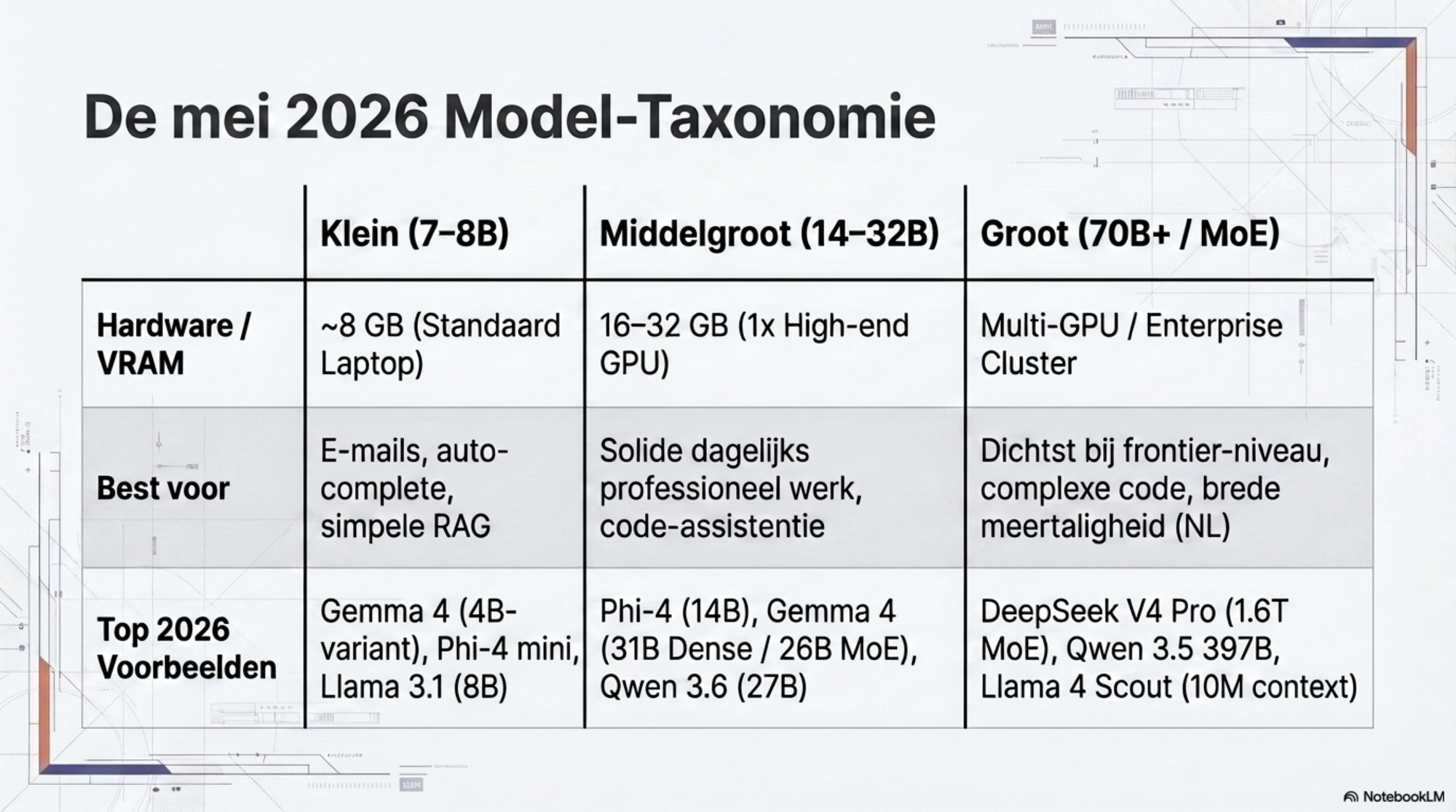
Kleine modellen (7–8B parameters) zijn goed genoeg voor een aanzienlijk deel van het dagelijkse professionele AI-werk: e-mails samenvatten, code aanvullen, eenvoudige analyses. Ze draaien op acht gigabyte RAM, het geheugen van een standaard laptop. Voor complexe redenering, creatief schrijven of taken die brede kennisintegratie vereisen zijn ze niet geschikt.
Middelgrote modellen (14–32B parameters) doen voor veel alledaagse professionele taken niet onder voor wat de commerciële frontier een halfjaar geleden bood. Microsoft's Phi-4 (14B), Gemma 4 31B en Qwen 3.6 27B zitten in deze categorie. Microsoft rapporteert dat Phi-4 op specifieke STEM-benchmarks zoals MATH en GPQA Diamond goed scoort voor zijn grootte, al moeten dergelijke vendor-claims met de eerder genoemde voorbehouden gelezen worden. Deze modellen vergen 16 tot 32 gigabyte VRAM.
Grote open-weight modellen (70B+, MoE) komen op specifieke taken — vooral codering — dicht in de buurt van de commerciële frontier. Op de onafhankelijke SWE-bench Pro staat Claude Opus 4.7 (Anthropic) bovenaan voor closed modellen; de beste open-weight modellen — DeepSeek V4, Kimi K2, GLM-5 — zitten daar enkele tot tien procentpunten onder. Op SWE-rebench, eveneens onafhankelijk uitgevoerd, liggen alle scores lager, maar de relatieve volgorde is grotendeels gelijk. De afstand tot de commerciële frontier is reëel, maar voor objectief verifieerbare taken zoals codering kleiner dan op andere domeinen.
Waar commerciële modellen structureel voor blijven lopen: veiligheidsalignment, instruction-following op complexe meerstaps-taken, robuustheid in productie, en de absolute top van creatief en analytisch schrijven. Commerciële labs lopen bovendien meestal één tot twee generaties voor op wat ze intern ontwikkelen ten opzichte van wat ze als open-weight vrijgeven.
Er is geen enkel antwoord op de vraag wat het beste lokale model is. De ranglijst verschuift per benchmark, per maand, per type taak. Maar in categorieën van gebruik kun je goed kiezen.
Dichtst bij de frontier op codering en wiskunde: DeepSeek V4 Pro (MIT). Lokaal draaien vereist serieuze infrastructuur — een multi-node H100/H200 cluster — vanwege de circa 865 GB aan modelgewichten in mixed precision. Niet voor thuis; wel voor een organisatie met eigen serveromgeving. Wie geen cluster heeft, gebruikt de DeepSeek API, en dan telt de teller weer.
Brede kwaliteit en meertaligheid, inclusief Nederlands: Qwen 3.5 397B (Apache 2.0). Sparse MoE met ongeveer 17 miljard actieve parameters per token. Alibaba's sterkste open-weight model, met expliciete optimalisatie voor meer dan tweehonderd talen — wie veel in het Nederlands werkt, kan met deze keuze de structurele taaltaks die ik in eerdere blogs beschreef deels omzeilen. Vereist meerdere GPU's voor volledige precisie; quantized versies draaien op minder.
Voor wie op één GPU wil draaien: Gemma 4 31B (Dense) of de 26B MoE-variant (Apache 2.0). Past op één high-end consumer GPU of een DGX Spark. De pragmatische keuze voor een team dat serieuze kwaliteit wil zonder een cluster te beheren. Qwen 3.6 27B (Apache 2.0) zit in dezelfde categorie, met sterke prestaties op coderingsbenchmarks voor zijn grootte.
Extreem lange context: Llama 4 Scout (Meta community license, met restricties boven 700 miljoen MAU). Tien miljoen tokens contextvenster — vooralsnog ongeëvenaard in de open-weight wereld. Minder sterk op pure redenering, maar voor hele codebases of lange juridische dossiers in één context is er weinig alternatief.
Voor wie alleen een laptop heeft: Gemma 4 MoE of Phi-4. Draaien op consumentenhardware met 8 tot 24 GB VRAM. Kwaliteit lager dan de top hierboven, maar goed genoeg voor het meeste dagelijkse werk.
Wie geeft dit weg — en waarom?
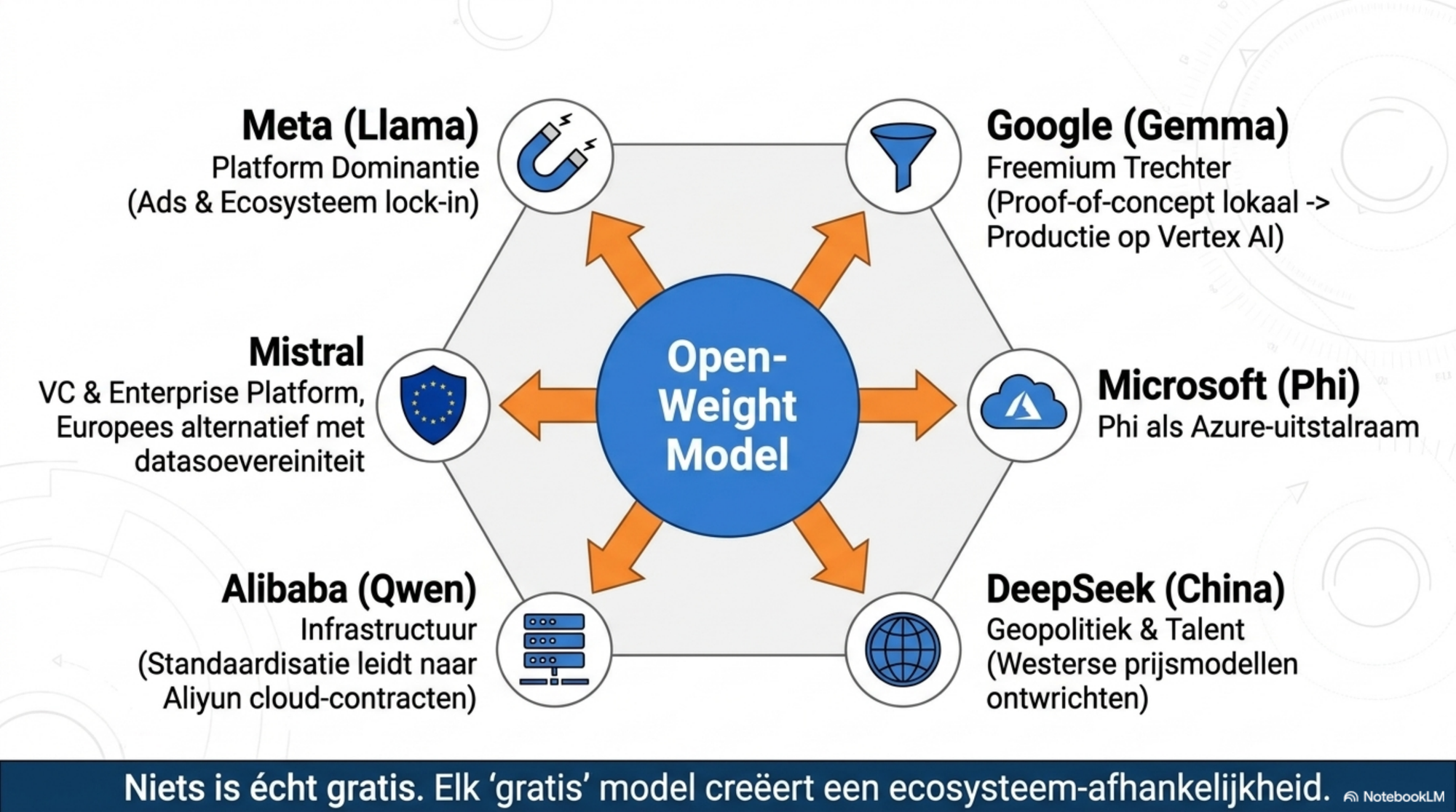
De meest interessante vraag is niet hoe goed deze modellen zijn. De meest interessante vraag is waarom iemand dit gratis weggeeft. Miljardeninvesteringen, tienduizenden GPU's, maanden trainen — en dan de gewichten publiceren onder een open licentie. Dat vraagt om een verklaring.
Meta (Llama) heeft het meest transparante motief. Meta's businessmodel is reclame, betaald uit de engagement van miljarden gebruikers op Facebook, Instagram en WhatsApp. Het vrijgeven van Llama kost Meta geen modelomzet — Meta verdient niet aan modelverkoop. Wat het oplevert: Meta AI wordt beter door het ecosysteem dat rond Llama wordt gebouwd, advertentietools draaien op Llama, en elke developer die Llama leert bouwen, bouwt indirect aan Meta's platform. Cloud-providers als AWS en Azure betalen Meta bovendien indirect via managed-service-overeenkomsten.
Google (Gemma) volgt een klassieke freemium-trechter. Meer dan 400 miljoen downloads, ruim 100.000 community-varianten. Elke download is een potentiële enterprise-klant die Google Cloud's betaalde infrastructuur nodig heeft zodra hij wil schalen. Proof-of-concept met Gemma, productie op Vertex AI.
Alibaba (Qwen) stuurt bewust richting Alibaba Cloud (Aliyun). De strategie is identiek aan de route die AWS met open-source databases bewandelde: maak het fundament gratis, verdien aan de infrastructuur eromheen. Elke productie-deployment van Qwen is een potentieel Aliyun-contract.
Mistral (Frans) financiert zich via venture capital en een betaald enterprise-platform. De open modellen zijn marketing: reputatie opbouwen, talent aantrekken, klanten binnenhalen via het open kanaal. Expliciete positionering als Europees alternatief — datasoevereiniteit als verkoopargument.
Microsoft (Phi) gebruikt kleine, efficiënte modellen als uitstalraam voor Azure. Elke developer die Phi leert bouwen, bouwt op Azure.
DeepSeek (China) is de meest complexe case. MIT-licentie, een betaalde API en een chatproduct, maar geen hyperscaler-cloud zoals AWS of Aliyun erachter en geen reclame-businessmodel. Het bestaan van de API verklaart niet de keuze om frontier-gewichten weg te geven onder een van de meest permissieve licenties die bestaan. De meest waarschijnlijke aanvullende verklaring: strategische reputatieopbouw, talent aantrekken en geopolitieke signaalwaarde — China als serieuze AI-speler die westerse labs op zowel kwaliteit als kosten confronteert.
Niets is werkelijk gratis. Elke aanbieder heeft een motief. Begrijpen wat dat motief is, helpt inschatten welke afhankelijkheid je aangaat.
Welke afhankelijkheid ga je aan?
Open-weight modellen beloven onafhankelijkheid. Maar die belofte is genuanceerder dan ze lijkt.
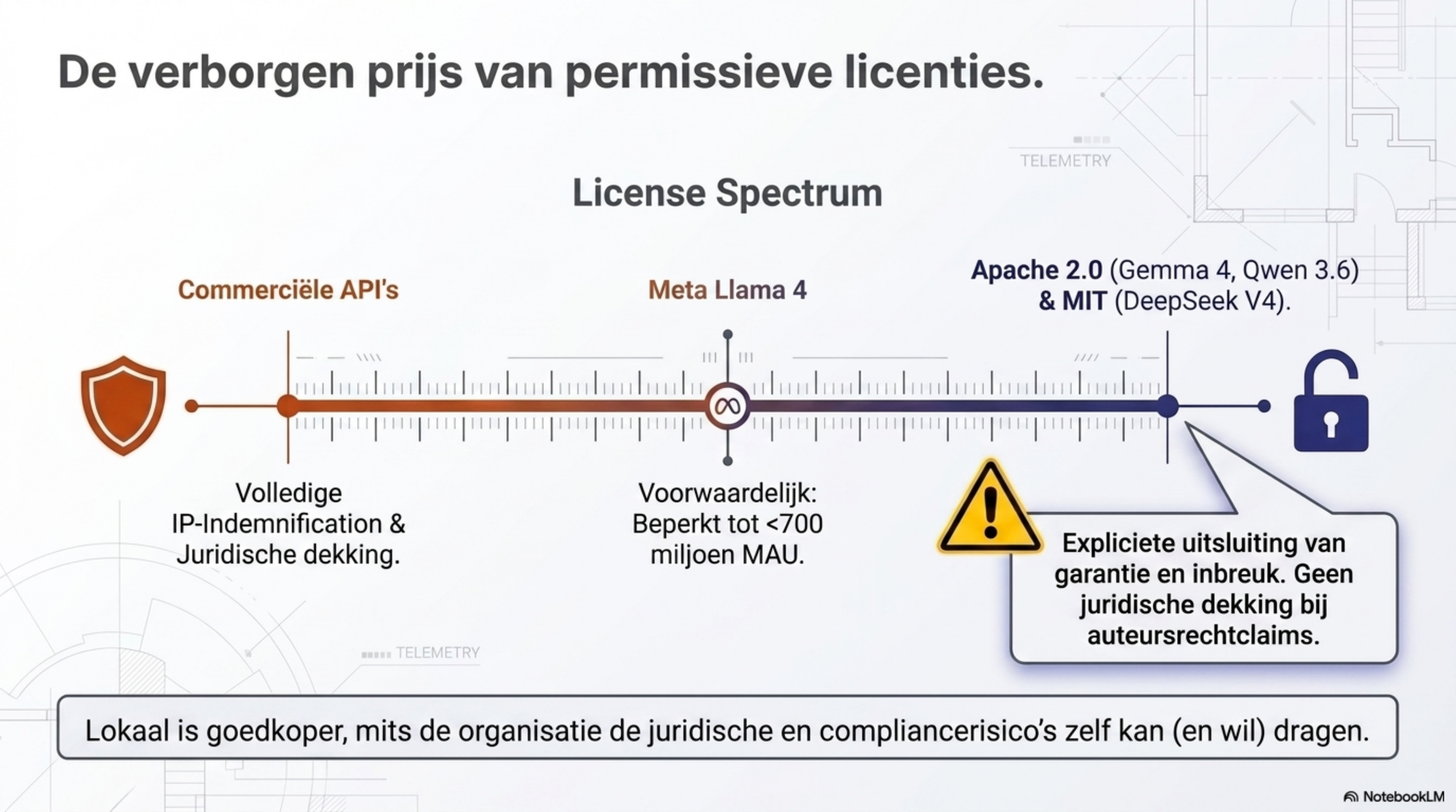
Licentierisico. Gemma 4 en Qwen 3.5/3.6 zijn Apache 2.0 — de meest permissieve klasse, zonder restricties voor commercieel gebruik. DeepSeek V3.2 en V4 zijn MIT-gelicentieerd, eveneens zeer permissief. Llama 4 valt onder Meta's eigen licentie, die bedrijven met meer dan 700 miljoen maandelijkse actieve gebruikers uitsluit. Sommige Qwen-varianten, waaronder de oudere 72B, vallen onder de Qwen License in plaats van Apache 2.0. Wie op open-weight bouwt, moet weten welke licentie van toepassing is — en die kan per modelgrootte verschillen, zelfs binnen één familie.
Juridische dekking — het verborgen verschil. OpenAI, Anthropic, Google en Microsoft bieden enterprise-klanten een IP-indemnification: als een output bijvoorbeeld een auteursrechtenkwestie oplevert of een schadeclaim van een derde partij, dekt het lab dat juridisch. Functioneel komt het neer op een verzekering. Apache 2.0 en MIT — de licenties waaronder vrijwel alle serieuze open-weight modellen worden uitgebracht — sluiten warranty en non-infringement juist expliciet uit. Dat staat in de licentietekst zelf. Voor gereguleerde sectoren — zorg, financiën, juridisch, overheid — is dit niet onbelangrijk. Het verandert de berekening van "lokaal is goedkoper" naar "lokaal is goedkoper, mits we het risico zelf kunnen dragen". Voor een softwareontwikkelaar die intern code genereert is dat triviaal. Voor een advocatenkantoor dat juridische analyses naar cliënten stuurt is het dat allerminst.
Platformafhankelijkheid in een nieuw jasje. Qwen is een veel gebruikte fine-tuning basis — maar van Alibaba, opererend onder Chinese wetgeving. Wie zijn AI-infrastructuur op Qwen bouwt, verplaatst zijn afhankelijkheid van Anthropic naar Alibaba. Dat is niet beter per se. Het is anders.
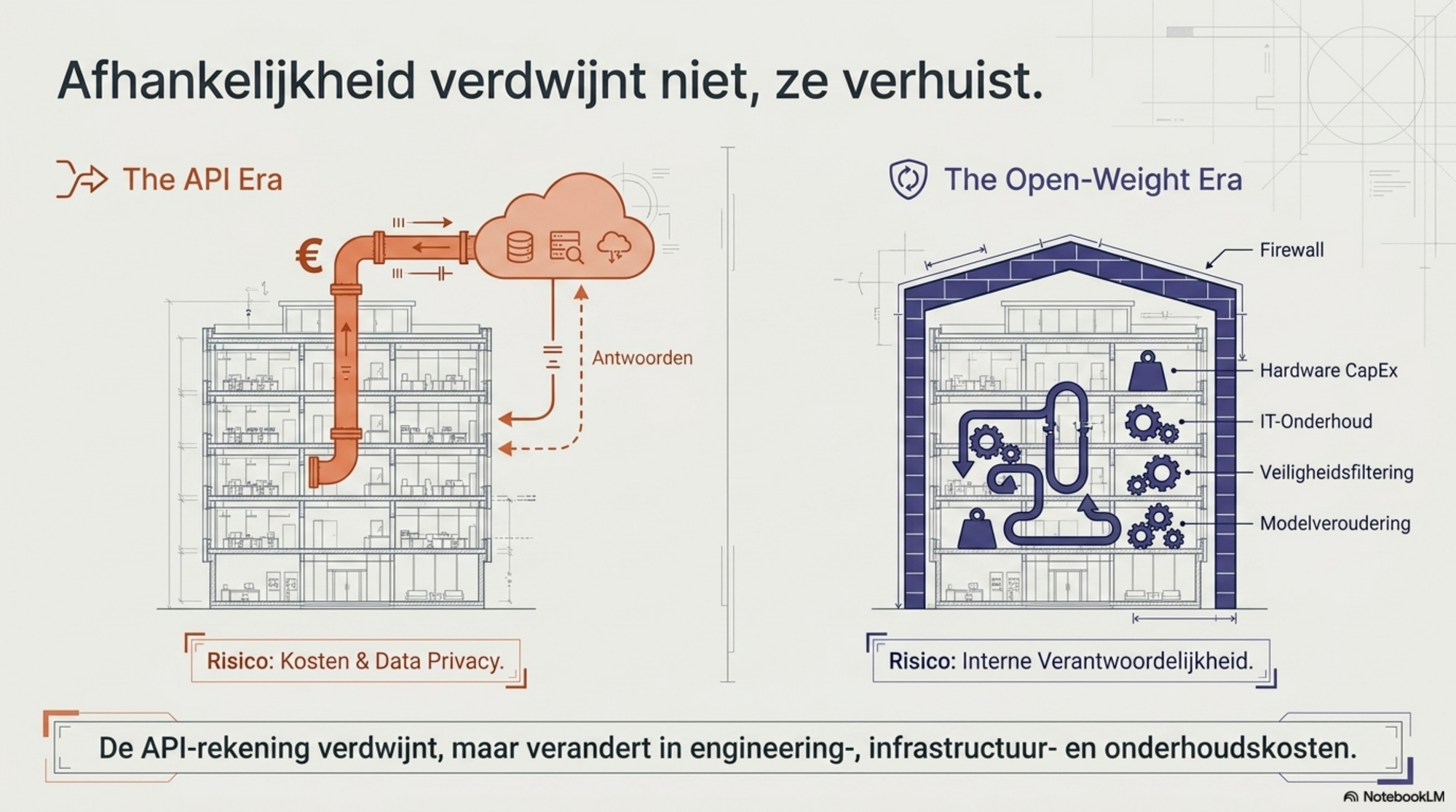
Modelveroudering. Open-weight modellen bevriezen op de dag van download. Over twee jaar draait iemand via API wat dan de standaard is; jij draait nog de Qwen of Gemma van 2026. Soms een voordeel — geen gedwongen migraties, geen stilzwijgende tokenizer-updates — maar ook een risico. De keuze tussen "stilstand die je controleert" en "vooruitgang die de leverancier controleert" is een echte keuze.
Onderhoudskosten verschuiven. Open-weight is niet gratis: kosten verschuiven van licentie naar engineering, infrastructuur en onderhoud. De besparing op API-tokens kan substantieel zijn, maar smelt deels weg tegen de nieuwe kosten van zelf hosten, beheren en upgraden.
Veiligheid en alignment. Commerciële labs investeren substantieel in safety-filtering. Open-weight modellen zijn kwetsbaarder voor misbruik — niet omdat ze slecht zijn, maar omdat de veiligheidslagen er expliciet af te halen zijn. Wie open-weight inzet voor productie, neemt die verantwoordelijkheid zelf op zich.
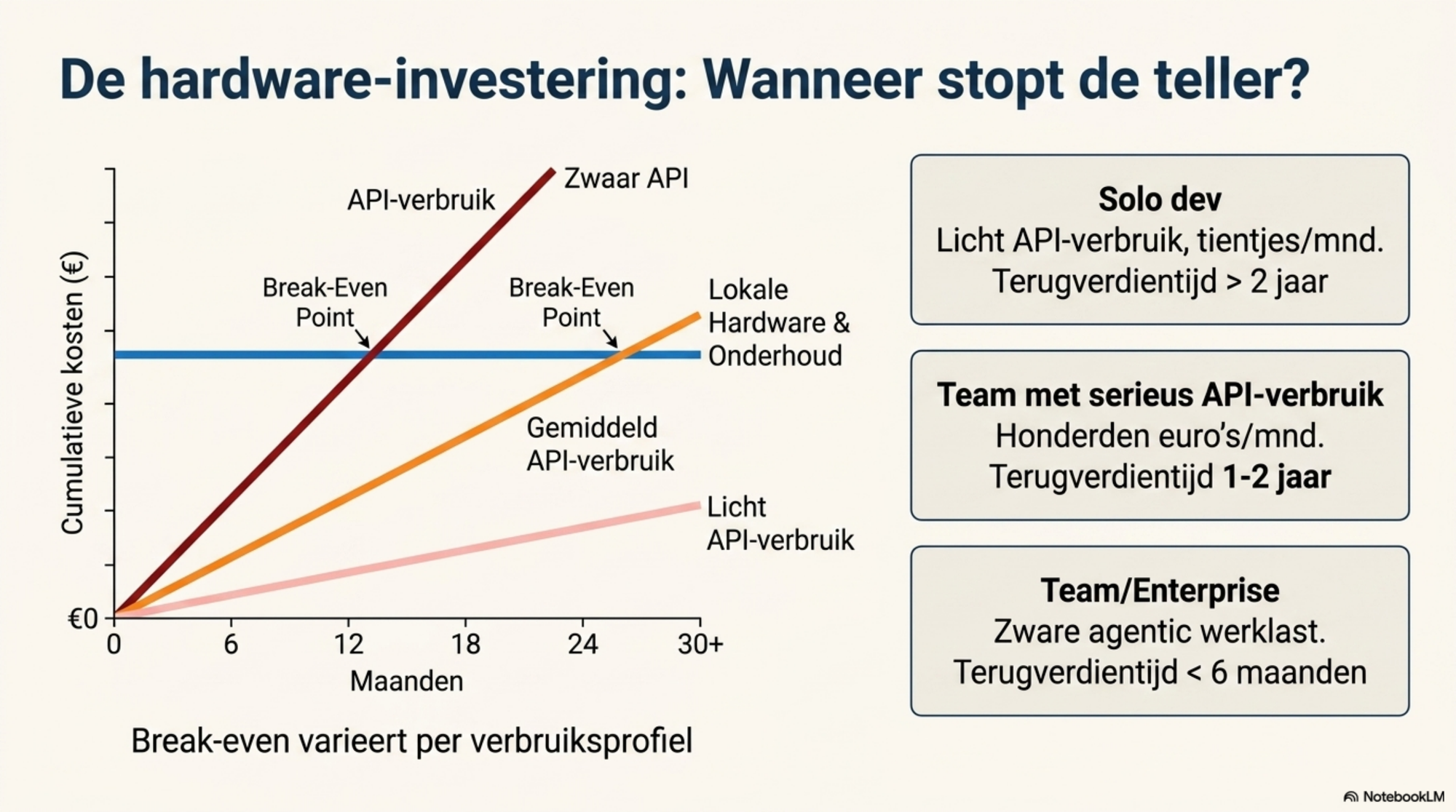
De kostenrekensom bij lokaal draaien
Lokaal draaien kost ook geld — alleen op een andere manier dan een API. Geen rekening per token, maar een eenmalige investering in hardware plus terugkerende kosten voor onderhoud, energie en tijd. Hoe snel die investering zich terugverdient, hangt af van één centrale variabele: hoe hoog de huidige tokenrekening is.
Voor een solo gebruiker met een paar tientjes API-kosten per maand is de break-even op een lokale setup van enkele duizenden euro's lang — meerdere jaren — als die er al komt. Voor een team dat structureel honderden tot duizenden euro's per maand uitgeeft aan API-tokens, ligt de break-even binnen één à twee jaar. Voor een organisatie met een grote agentic werklast — waarbij modellen continu draaien voor classificatie, samenvatting of documentverwerking — kan een lokale of hybride opzet binnen maanden terugverdiend zijn.
De hardwaremarkt is op dit moment uitgesproken dynamisch — vraag overstijgt aanbod, geheugentekorten zijn structureel, prijzen veranderen per maand. Wat in mei 2026 geldt, is een momentopname. Grofweg: NVIDIA's RTX 5090 (32 GB) is de huidige consumentenkaart voor lokale inferentie, opvolger van de inmiddels uitgefaseerde RTX 4090. Mac Studio's met grote unified memory zijn aantrekkelijk maar kampen met levertijden van weken. NVIDIA's DGX Spark biedt 128 GB unified memory in een kant-en-klare workstation. AMD's Strix Halo-platform (Ryzen AI Max+ 395) is de interessantste nieuwkomer met 128 GB unified memory in mini-PC-formaat. Voor enterprise-deployment van de grootste modellen blijven multi-GPU clusters of refurbished datacenter-systemen aan de orde.
Wat in geen enkele hardwarerekensom past: de setup-tijd, de beheerscapaciteit en de opleercurve. Lokaal draaien is geen plug-and-play voor niet-technische gebruikers. En naast hardware en setup zijn er de inhoudelijke beperkingen die ik eerder besprak — modelveroudering, ontbrekende juridische dekking, eigen verantwoordelijkheid voor veiligheid en alignment. De vraag is dus niet alleen of de break-even-rekening uitkomt, maar of een organisatie de bredere trade-off bewust kan dragen.
Waar begin je? Een handvol tools domineert het lokale landschap. Ollama is het laagdrempeligst: één commando installeert de runtime en start een model, inclusief een OpenAI-compatibele API. LM Studio voegt een grafische interface toe — geen terminal nodig. vLLM is de productieoptie, met continuous batching en multi-GPU tensor parallelism voor de hoogste doorvoer per euro hardware. llama.cpp draait op vrijwel alle hardware, inclusief CPU — langzamer, maar volledig offline. Voor IDE-integratie voegt Continue.dev lokale inferentie toe aan VS Code en JetBrains, zonder dat er een byte naar een externe server gaat.

Voor wie is dit realistisch?
Solo developers en technisch vaardige professionals: direct toepasbaar. Een Mac Studio, een Strix Halo mini-PC of een RTX 5090-workstation opent toegang tot een aanzienlijk deel van frontier-kwaliteit voor nul marginale kosten per inferentie. Hoe snel die investering zich terugverdient, hangt vooral af van hoe zwaar je nu op betaalde API's leunt.
Teams met gevoelige data — AVG, IP, compliance: het sterkste argument. Data verlaat het gebouw niet. Voor juridische kantoren, ziekenhuizen, banken en overheidsorganisaties is datasoevereiniteit geen optie maar een vereiste. Een zelf-gehoste stack is dan geen kostenoptimalisatie maar noodzaak.
Organisaties met hoog volume standaardwerk: het hybride model is het meest realistisch. Lokaal voor classificatie, samenvatting, documentverwerking. Frontier API voor de moeilijke vragen die werkelijk frontier-capaciteit vereisen. Onderzoek wijst uit dat dit patroon de inferentierekening met 60 tot 80 procent kan reduceren zonder kwaliteitsverlies — exacte percentages variëren met de werklast.
Non-technische eindgebruikers: nog niet. Een zelf-gehoste stack vergt engineeringkennis die buiten het bereik van de gemiddelde medewerker valt.
Frontier-taken: eerlijk nee, voor nu. Complexe agentic workflows, subtiele creatieve taken, geavanceerde meerstaps-redenering — de commerciële frontier loopt structureel voor. De afstand krimpt per kwartaal, om vervolgens soms weer iets op te lopen. Maar hij bestaat.
De grootste valkuil: alles routeren naar het sterkste beschikbare model omdat het er staat. Bedrijfsmatig is dat hetzelfde als elke patiënt bij de neurochirurg neerleggen: te duur voor het meeste werk, en de neurochirurg heeft geen tijd meer voor het werk dat er werkelijk toe doet. De juiste benadering is triage — sturen op type taak, gevoeligheid van data en de werkelijke kwaliteitseis.
| Situatie | Aanbevolen aanpak | Reden |
|---|---|---|
| Gevoelige data — AVG, IP, juridisch, zorg | Volledig lokaal | Data verlaat gebouw niet |
| Hoog volume standaardwerk (samenvatting, classificatie, RAG) | Hybride: lokaal + frontier API | Substantiële kostenbesparing |
| Complexe agentic of creatieve taken | Frontier API | Kwaliteitskloof is reëel |
| Solo developer, dagelijks gebruik | Lokaal (Strix Halo / Mac Studio / RTX 5090-systeem) | Terugverdientijd afhankelijk van huidig API-verbruik |
| Non-technische eindgebruiker | API of managed product | Setup-drempel te hoog |
| Team wil fine-tunen op eigen data | Lokaal (minimaal 32B basis) | Gewichten zijn van jou |
| Klantgericht output, gereguleerde sector | Frontier API met indemnification | Juridische dekking weegt op tegen kostenvoordeel |
De derde weg is echt
Na tien blogs in deze reeks heb ik de tokeneconomie beschreven als een systeem van afhankelijkheden die de gemiddelde gebruiker niet ziet: tokenizers die per lab verschillen, taaltaksen die structureel zijn ingebakken, prijzen die veranderen zonder aankondiging, abonnementen die de werkelijke kosten verbergen, en een geopolitieke tweedeling tussen westerse en Chinese modellen.
Lokale modellen doorbreken dat systeem — niet volledig, niet voor iedereen, maar structureel anders dan alles ervoor.
De teller staat stil. Geen tokenrekening per inferentie, geen model dat stilzwijgend een nieuwe tokenizer krijgt, geen enterprise-prijsverhoging die in een nachtelijke e-mail wordt aangekondigd. De hardware staat op jouw plek. De gewichten zijn van jou. De data verlaat het gebouw niet.
In ruil betaal je eenmalig hardware, structureel onderhoud, en de eerlijkheid dat je voor de moeilijkste taken nog steeds een commerciële API nodig hebt.
Wat in deze blog bewust ontbreekt, is een tabel met benchmark-scores tot op één decimaal. Niet omdat die getallen niet bestaan, maar omdat ze geen ranglijst rechtvaardigen die langer dan een maand houdbaar is. De cijfers verschuiven; de richting is wat telt.
De richting is duidelijk. Lokale en open-weight modellen geven je vandaag ongeveer wat de commerciële frontier zes tot negen maanden geleden bood. Voor een groot deel van het dagelijkse werk is dat ruim voldoende. Voor de moeilijkste taken — complexe agentic workflows, subtiel meerstaps-redeneren, klantgerichte output in gereguleerde sectoren — loopt de commerciële frontier nog steeds voor.
Voor elke organisatie die nu serieus met AI aan de slag gaat — en dat betekent in 2026 ook werken met agents — komt daarmee één vraag centraal te staan: welke weg past bij welke taak? Er zijn drie serieuze opties. Westerse commerciële modellen (OpenAI, Anthropic, Google, Microsoft) leveren de hoogste kwaliteit, met juridische dekking en enterprise-features — tegen een prijs die in 2026 fors stijgt. Chinese commerciële modellen (DeepSeek, Alibaba, Moonshot, Zhipu) bieden vergelijkbare prestaties voor een fractie van de kosten, maar onder Chinese wetgeving en met andere afhankelijkheidsrisico's. Open-weight modellen geven controle, datasoevereiniteit en geen tokenrekening, in ruil voor een investering in hardware, onderhoud en het accepteren van beperkingen.
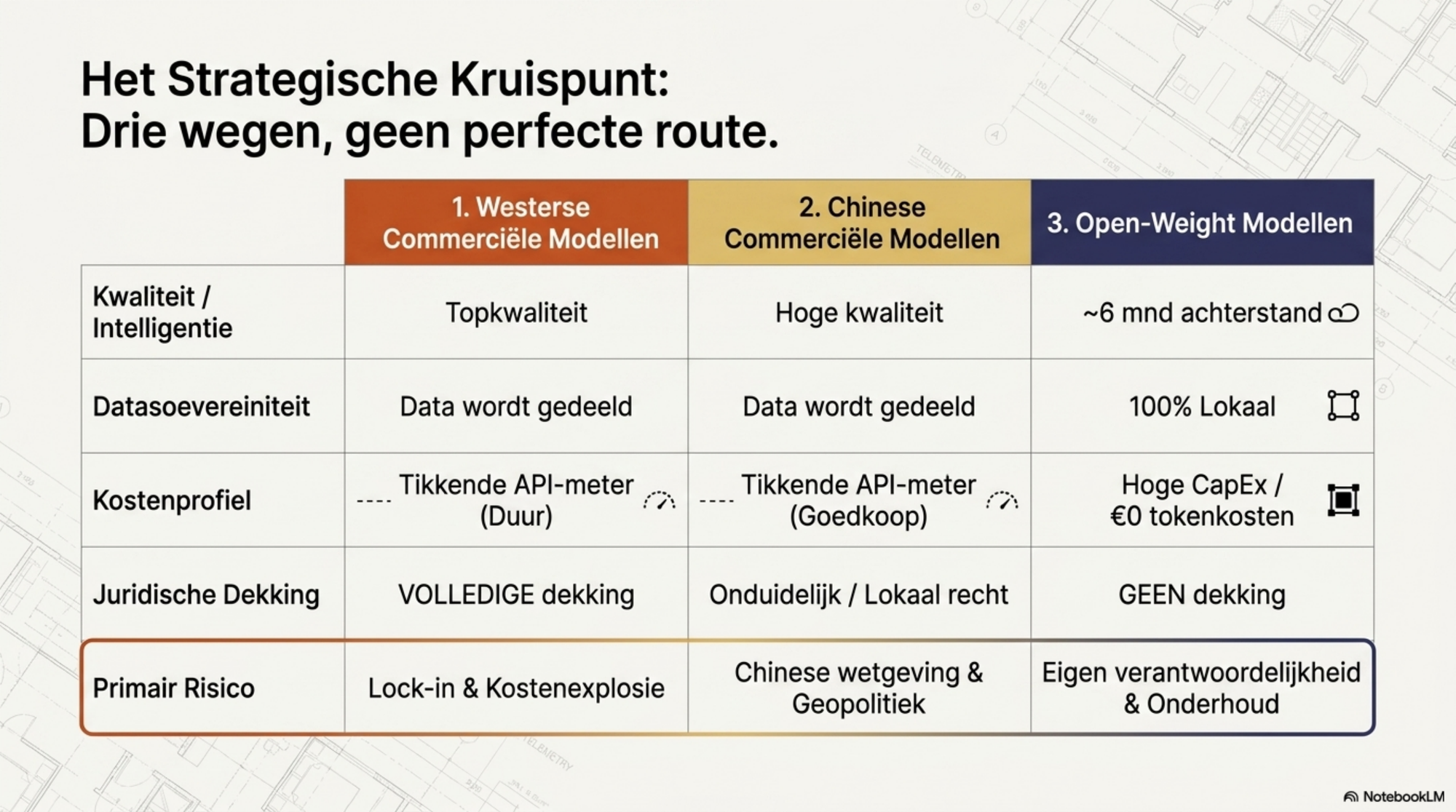
Geen van deze drie is universeel beter. Voor agents die continu draaien op duizenden documenten zijn de kosten van de verkeerde keuze enorm. Voor klantgerichte output in gereguleerde sectoren zijn de juridische risico's van de verkeerde keuze enorm. Voor een kleine organisatie zonder eigen engineeringcapaciteit zijn de operationele kosten van de verkeerde keuze enorm. De drie wegen verdienen elk een serieuze afweging.

In de volgende blogs in deze reeks ga ik daarom door op de tokeneconomie zoals die nu beweegt. Eén blog over de prijsontwikkelingen van de afgelopen tijd — wie verhoogt, wie verlaagt, en wat dat betekent voor wie nu een keuze moet maken. En een blog over een concreet routerings-schema: welke taak hoort bij welke weg, welk model bij welke organisatie, welk kanaal bij welk soort werk. Welke teller je laat tikken, en welke je laat stilstaan.
Deze blog maakt deel uit van een bredere reeks over AI als systeemverschuiving — van de economie van tokens tot de versnelling van de technologie en wat dat betekent voor mensen en organisaties. De technische kant van AI in de praktijk beschrijft Edwin van Dillen. De bredere gedachten over organisatie, intentie en uitvoering zijn uitgewerkt op augmentedorganisation.nl, intentdriven.nl en augmentedengineering.nl.
De tokenreeks — eerder verschenen
Tokens op de meter — 23 maart 2026 Sam Altman beschreef het businessmodel openlijk: intelligentie wordt een nutsvoorziening, afgerekend per token. Deze blog introduceert de token als rekeneenheid, beschrijft de verslavingsfase waarin AI-bedrijven nu zitten — goedkoop om afhankelijkheid te bouwen — en legt uit waarom de uitgestelde rekening reëel is. Tokenefficiëntie is nu al een strategische vaardigheid.
De tokeneconomie — 24 maart 2026 Alibaba richtte de Alibaba Token Hub op: een formele business unit met de missie "tokens creëren, distribueren en toepassen". Drie lagen — foundational modellen, API-distributie, agentic platforms — vormen een verticaal geïntegreerd ecosysteem. Opmerkelijk: de tokeneconomie benoemt zichzelf, terwijl eerdere technologiegolven pas achteraf werden benoemd.
De token als meetlat — 27 maart 2026 Vier lenzen waarop bedrijven tokenverbruik meten — als factuur, als prestatiemeting, als statussymbool en als waardesignaal. Centrale conclusie: tokenefficiëntie is een proxy voor denkkwaliteit, niet voor technische vaardigheid.
SAP wordt tokenreseller — 28 maart 2026 SAP-CEO Christian Klein kondigde het einde van het abonnementsmodel aan. SAP's "AI Units" zijn onder de motorkap tokens ingekocht bij Anthropic, OpenAI en anderen. SAP is in essentie tokenreseller geworden. Systemen commoditiseren; menselijk vermogen blijft de onvervangbare differentiator.
De meter die lastig is te lezen — 7 april 2026 Drie betalingswerelden: de transparante API-wereld, de verpakte abonnementswereld en de geabstraheerde enterprise-wereld. Abonnementen zijn voor de gemiddelde gebruiker drie tot veertien keer duurder per token dan directe API-toegang. In de enterprise wrapper-wereld ontbreekt de prikkel tot tokenefficiëntie structureel.
Tokenafhankelijkheid — april 2026 Via de Black Mirror-aflevering Common People en het concept enshittification: hoe Anthropic in zes stappen laat zien hoe de uitgestelde rekening stap voor stap wordt gepresenteerd. Agentic AI verdiept de afhankelijkheid structureel.
De tokenizer als verborgen variabele — april 2026 Een token bij OpenAI is niet hetzelfde als een token bij Anthropic. En een token bij Anthropic 4.6 is niet hetzelfde als bij 4.7. Vergelijking van alle grote labs: OpenAI (tiktoken, 200k vocabulaire), Google (SentencePiece, 262k), xAI, Anthropic (proprietary, ongedocumenteerd), Microsoft (geen eigen tokenizer). De stickerprice is geen eerlijke vergelijkingsmaatstaf.
De taaltaks — mei 2026 Nederlandse gebruikers betalen structureel 30 tot 35 procent meer tokens dan Engelstaligen voor dezelfde inhoud, door hogere tokenizer-fertiliteit. Bij technische content op Anthropic's Opus 4.7-tokenizer loopt dit op tot circa 90 procent. De taaltaks staat op geen enkele factuurlijn — maar hij tikt elke keer mee.
De prijs van intelligentie — mei 2026 De huidige lage tokenprijs is geen marktprijs maar een strategische keuze: venture capital en hyperscalers betalen het verschil om afhankelijkheid te bouwen. Die subsidie-fase eindigt. Anthropic verschoof enterprise-klanten stilletjes naar gebruiksgebaseerde facturering. De markt beweegt naar cognitieve stratificatie in drie lagen: commodity-cognitie, enterprise frontier, en strategische AI — met toenemende afstand tussen elke laag.
De Chinese AI-labs — mei 2026 DeepSeek, Qwen, Kimi, GLM — Chinese labs bieden frontier-kwaliteit voor een fractie van de westerse prijs. Structurele kostenvoordelen, geopolitieke spanningen, en een tokenizer die relatief gunstig omgaat met niet-Engelse talen. Maar: Chinese wetgeving volgt het model waar het ook naartoe gaat.
Co-creatie: Dit stuk is gemaakt samen met Claude (Anthropic) en NotebookLM (Google). De gedachten, posities en interpretaties zijn van mij.